多线程操作CSV文件并且将CSV文件转成XLSX文件python爬虫入门进阶(10)-2
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程操作CSV文件并且将CSV文件转成XLSX文件python爬虫入门进阶(10)-2相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
本文重点:这篇文章主要学习正则表达式以及re模块的使用。
关注下方公众号,众多福利免费嫖;加我VX进群学习,学习的路上不孤单

为啥写这篇文章?
上一篇文章我们简单的介绍了如何读写CSV文件,CSV文件操作起来还挺方便的【python爬虫入门进阶】(10)
。但是没有对CSV文件应用到实际的爬虫开发中。这篇文章将介绍如何通过多线程操作CSV文件,并将CSV文件转成xlsx文件。
爬取数据
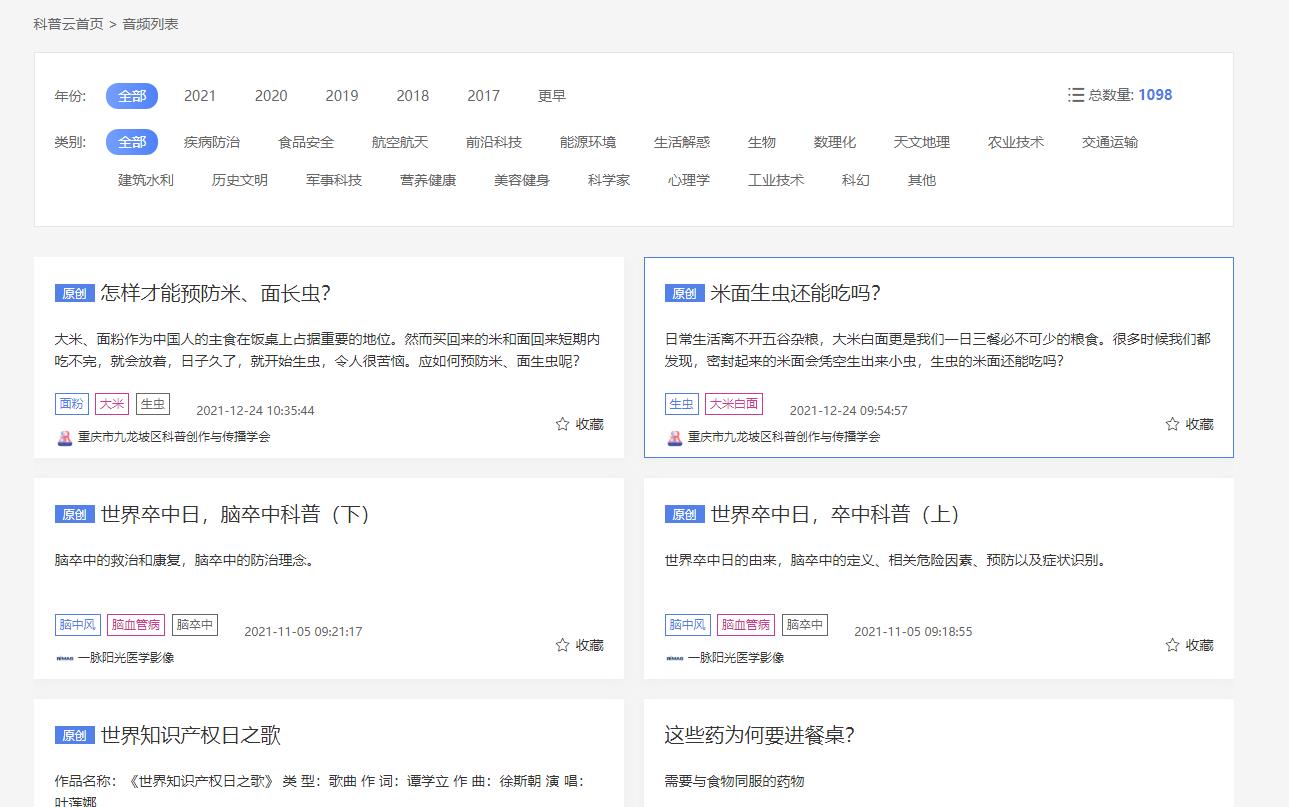
这里以某网站为例,如下图1所示。爬取该网站的音频文章的标题,作者,链接以及所属类别等信息。然后,将这些信息放在CSV文件中。
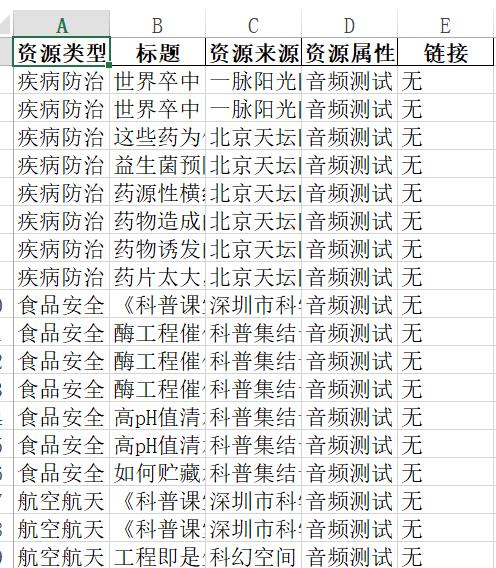
程序最后达到的效果如下图2所示:
定义类别
如果不分类别爬取的话是不知道每个文章所属的类别的。所以这里我先按照类别进行爬取,这样就可以知道每个文章的所属类别了。
category_id =
1: '疾病防治',
2: '食品安全',
3: '航空航天',
4: '前沿科技',
5: '能源环境',
6: '生活解惑',
7: '生物',
8: '数理化',
9: '天文地理',
10: '农业技术',
11: '交通运输',
12: '建筑水利',
13: '历史文明',
14: '军事科技',
15: '营养健康',
16: '美容健身',
17: '科学家',
18: '心理学',
19: '工业技术',
20: '科幻',
21: '其他'
source_property = "音频测试"
headers = ['资源类型', '标题', '资源来源', '资源属性', '链接']
with open(source_property + '.csv', 'a', encoding='utf-8', newline='') as fp:
writer = csv.writer(fp)
writer.writerow(headers)
for i in range(1, 22):
new_url = url + '?category_id=0&can_down=0&sort_rule=0'.format(str(i))
threadPool.apply_async(func=get_tab, args=(category_id.get(i), new_url))
这里首先定义了一个名为音频测试.csv的文件,然后写入文件头。
接着通过线程池去执行每个类别下的数据爬取任务。这里线程池的大小设置为4。
threadPool = ThreadPool(processes=4)
爬取每页的数据
首先获取每个类别下的总页数。然后,爬取每页的数据,将每页的数据写入到一个列表中。每爬取完一页数据之后就将该页数据写入到CSV文件中。其中列表中保存的数据是一个个元组。
def get_page(source_type, url):
resp = requests.get(url, verify=False)
html = etree.HTML(resp.content.decode('utf-8'))
# 提取文章标题
elements = html.xpath('//div[@class="list-block _blockParma _popAudio"]')
content = []
for element in elements:
# 文章标题
title = element.xpath('.//a[@class="_title"]/text()')[0].replace('\\n', '').strip()
# 提取链接
href = "无"
# 提取标签
span = element.xpath('./p[3]//text()')[2].replace('\\n', '').strip()
content.append((source_type, title, span, source_property, href))
save_data(source_property, content)
操作CSV
因为是多线程同时操作同一个CSV文件。所以,在写入数据的时候需要加上锁。不然有可能就会出现数据丢失的情况。
import threading
glock = threading.Lock()
def save_data(source_property, content):
glock.acquire()
with open(source_property + '.csv', 'a', encoding='utf-8', newline='') as fp:
writer = csv.writer(fp)
writer.writerows(content)
glock.release()
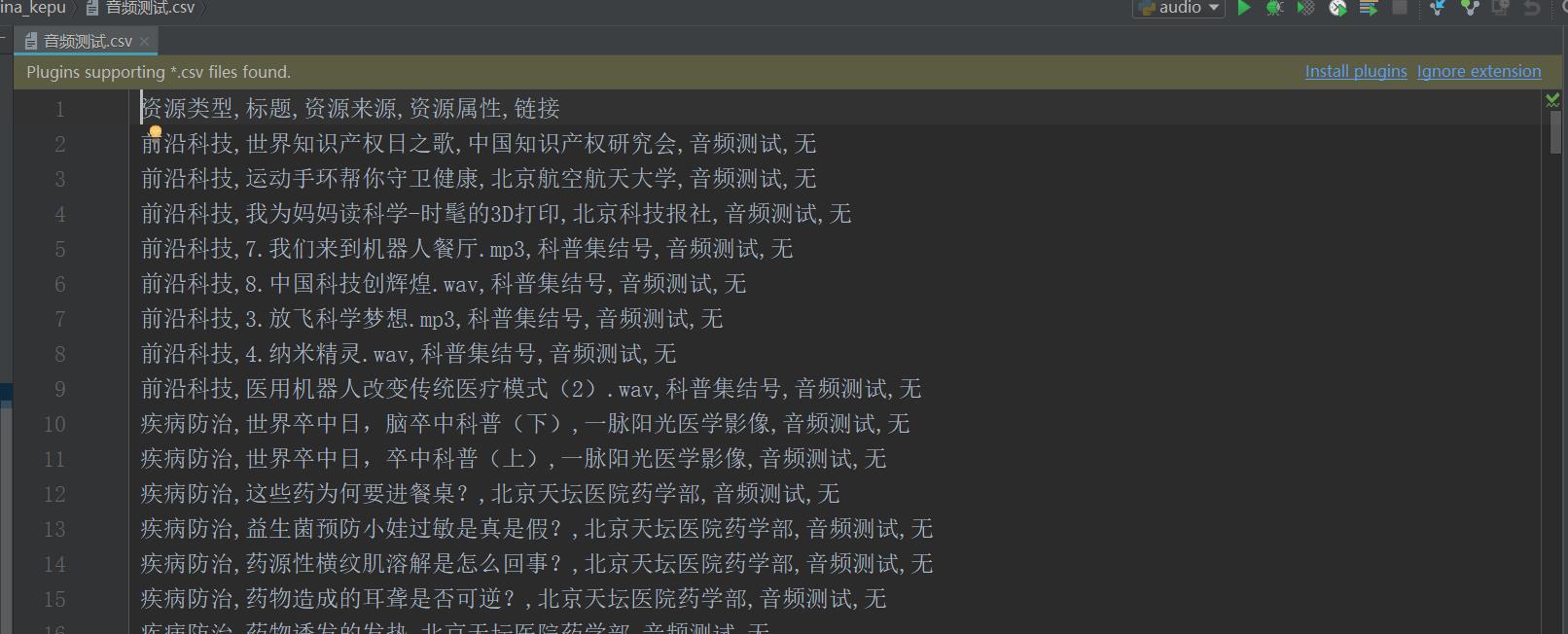
定义一个全局的Lock锁,在操作CSV文件之前获取锁,在操作完成之后在释放锁。在Windows下CSV的默认编码是gbk。在写入的时候可能有部分字符会出现乱码的情况。所以,这里指定编码为utf-8。写入完成之后的效果如下图3所示:
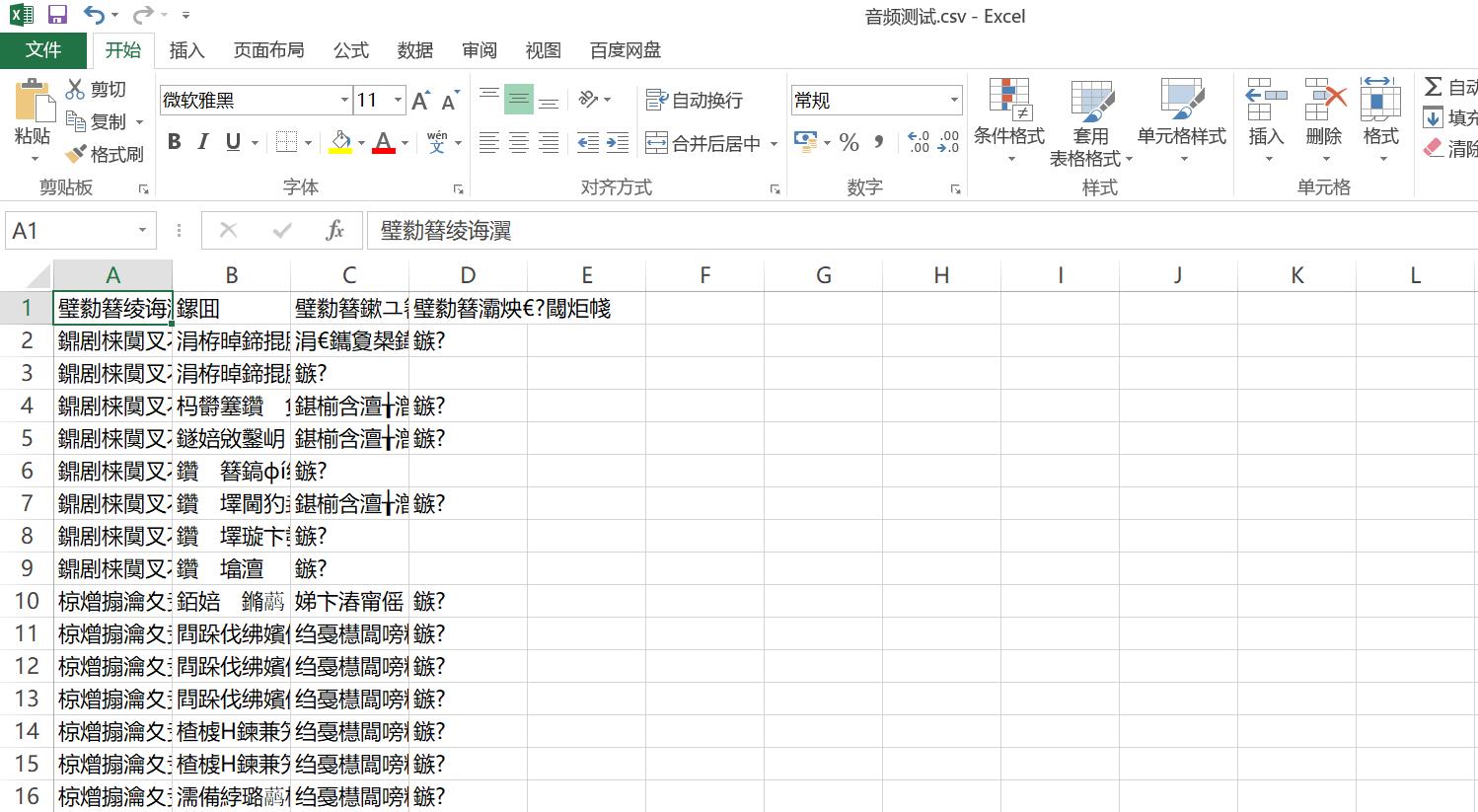
但是,在windows下打开utf-8编码的csv文件会出现乱码的情况。如下图4所示:
所以,这里还需要将CSV文件转成xlsx文件。转换的代码如下所示:
def csv_2_xlsx(src_path, source_type):
try:
csv = pd.read_csv(src_path, encoding="utf-8", low_memory=False)
except:
csv = pd.read_csv(src_path, encoding="gbk", low_memory=False)
csv.to_excel("xlsx/" + src_path[:-3] + 'xlsx', sheet_name=source_type, index=False)
完整代码
import csv
import pandas as pd
import requests
from lxml import etree
import os
import threading
from multiprocessing.pool import ThreadPool
glock = threading.Lock()
threadPool = ThreadPool(processes=4)
category_id =
1: '疾病防治',
2: '食品安全',
3: '航空航天',
4: '前沿科技',
5: '能源环境',
6: '生活解惑',
7: '生物',
8: '数理化',
9: '天文地理',
10: '农业技术',
11: '交通运输',
12: '建筑水利',
13: '历史文明',
14: '军事科技',
15: '营养健康',
16: '美容健身',
17: '科学家',
18: '心理学',
19: '工业技术',
20: '科幻',
21: '其他'
# 判断是图片还是视频
source_property = "音频测试"
requests.packages.urllib3.disable_warnings()
url = r"https://cloud.kepuchina.cn/newSearch/audio"
def get_tab(source_type, url):
resp = requests.get(url, verify=False)
html = etree.HTML(resp.content.decode('utf-8'))
# 获取总页数
total_page_sour = html.xpath('//div[@class="total-page"]//text()')[0]
total_page = total_page_sour[1:len(total_page_sour) - 1]
for i in range(1, int(total_page) + 1):
page_url = url + "&page=" + str(i)
get_page(source_type, page_url)
print(threading.current_thread().getName() + '该tab数据写入完成')
def get_page(source_type, url):
resp = requests.get(url, verify=False)
html = etree.HTML(resp.content.decode('utf-8'))
# 提取文章标题
elements = html.xpath('//div[@class="list-block _blockParma _popAudio"]')
content = []
for element in elements:
# 文章标题
title = element.xpath('.//a[@class="_title"]/text()')[0].replace('\\n', '').strip()
# 提取链接
href = "无"
# 提取标签
span = element.xpath('./p[3]//text()')[2].replace('\\n', '').strip()
content.append((source_type, title, span, source_property, href))
save_data(source_property, content)
# 将数据写入到CSV文件中
def save_data(source_property, content):
glock.acquire()
with open(source_property + '.csv', 'a', encoding='utf-8', newline='') as fp:
writer = csv.writer(fp)
writer.writerows(content)
glock.release()
# 在window下直接打开utf-8编码的CSV文件会出现中文乱码
def csv_2_xlsx(src_path, source_type):
try:
csv = pd.read_csv(src_path, encoding="utf-8", low_memory=False)
except:
csv = pd.read_csv(src_path, encoding="gbk", low_memory=False)
csv.to_excel("xlsx/" + src_path[:-3] + 'xlsx', sheet_name=source_type, index=False)
if __name__ == '__main__':
if os.path.exists(source_property + '.csv'):
os.remove(source_property + '.csv')
if os.path.exists('xlsx//' + source_property + '.xlsx'):
os.remove('xlsx//' + source_property + '.xlsx')
# 创建若干个线程 前言
headers = ['资源类型', '标题', '资源来源', '资源属性', '链接']
with open(source_property + '.csv', 'a', encoding='utf-8', newline='') as fp:
writer = csv.writer(fp)
writer.writerow(headers)
for i in range(1, 22):
new_url = url + '?category_id=0&can_down=0&sort_rule=0'.format(str(i))
threadPool.apply_async(func=get_tab, args=(category_id.get(i), new_url))
# get_tab(category_id.get(i), new_url)
threadPool.close()
threadPool.join()
csv_2_xlsx(source_property + '.csv', source_property)
print(threading.current_thread().getName() + "文件转成xlsx")
总结
本文以某科普网站为例介绍了如何通过多线程将爬取的数据写入到CSV文件中,并且将CSV文件转成xlsx文件。
粉丝专属福利
软考资料:实用软考资料
面试题:5G 的Java高频面试题
学习资料:50G的各类学习资料
脱单秘籍:回复【脱单】
并发编程:回复【并发编程】
👇🏻 验证码 可通过搜索下方 公众号 获取👇🏻
以上是关于多线程操作CSV文件并且将CSV文件转成XLSX文件python爬虫入门进阶(10)-2的主要内容,如果未能解决你的问题,请参考以下文章