Python爬虫-CSDN博文存为HTML/PDF文档
Posted Tr0e
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫-CSDN博文存为HTML/PDF文档相关的知识,希望对你有一定的参考价值。
前言
写了 CSDN 博客后,有没有担心过万一有一天博客“不见了”(你懂的)……你的心血不就白费了?还有看到喜欢的文章是不是想保存到本地、避免文章某一天就“没了”或者收费了?本文将学习记录下如何使用 Python 脚本将 CSDN 博文自动以 html、PDF 两种格式的文件保存到本地。
单篇保存
先来看看如何对指定的单篇文章进行本地保存和格式转换。
脚本编写
1、脚本需要导入以下模块:
import pdfkit
import requests
import parsel
2、同时 PC 需要安装 wkhtmltopdf 工具用于将 html 文档转换为 pdf,官网下载地址,安装后如下:
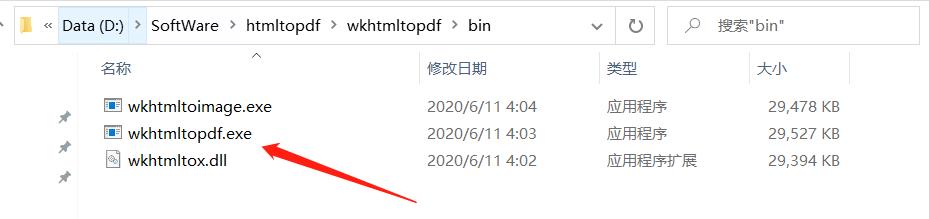 3、打开浏览器右键检查进行分析,获得文章内容相关的 html 元素(去除无关内容),通过简单的分析可以发现 article 标签下就是我们需要的内容:
3、打开浏览器右键检查进行分析,获得文章内容相关的 html 元素(去除无关内容),通过简单的分析可以发现 article 标签下就是我们需要的内容:
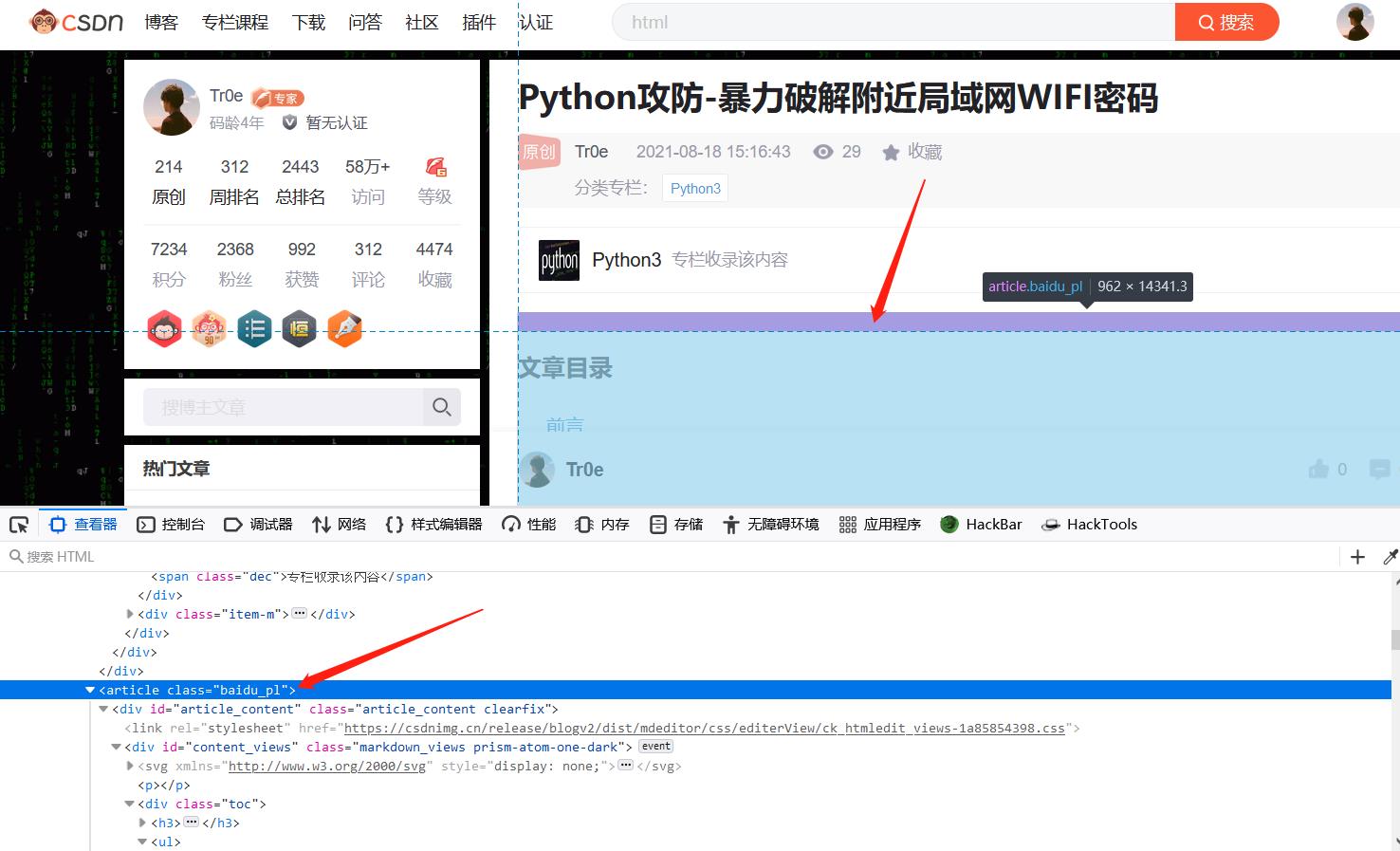 4、由于上述提取出来的 acticle 标签后面的网页元素无法形成一个完整的 html 文档,所以需要对其进行格式拼装。如下是一个标准的 html 结构:
4、由于上述提取出来的 acticle 标签后面的网页元素无法形成一个完整的 html 文档,所以需要对其进行格式拼装。如下是一个标准的 html 结构:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
相关内容
</body>
</html>
分析完上述前置内容,接下来就直接看完整脚本了:
import pdfkit
import requests
import parsel
url = 'https://bwshen.blog.csdn.net/article/details/119778471'
headers =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
response = requests.get(url=url, headers=headers)
html = response.text
selector = parsel.Selector(html)
# 提取文章的标题
title = selector.css('.title-article::text').get()
# 提取标签为 article 的内容
article = selector.css('article').get()
# 定义一个标准的html结构,用于对上面提取到的 article 标签内容进行组装
src_html = '''
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
content
</body>
</html>
'''
# 将文章内容组装成标准的 html 格式文档并保存到本地
with open(title + '.html', mode='w+', encoding='utf-8') as f:
f.write(src_html.format(content=article))
print('%s.html 已保存成功' % title)
# 调用 wkhtmltopdf 工具将html文档转换为pdf格式的文档
config = pdfkit.configuration(wkhtmltopdf=r'D:\\SoftWare\\htmltopdf\\wkhtmltopdf\\bin\\wkhtmltopdf.exe')
pdfkit.from_file(title + '.html', title + '.pdf', configuration=config)
print(title + '.pdf', '已保存成功')
效果演示
代码运行如下:
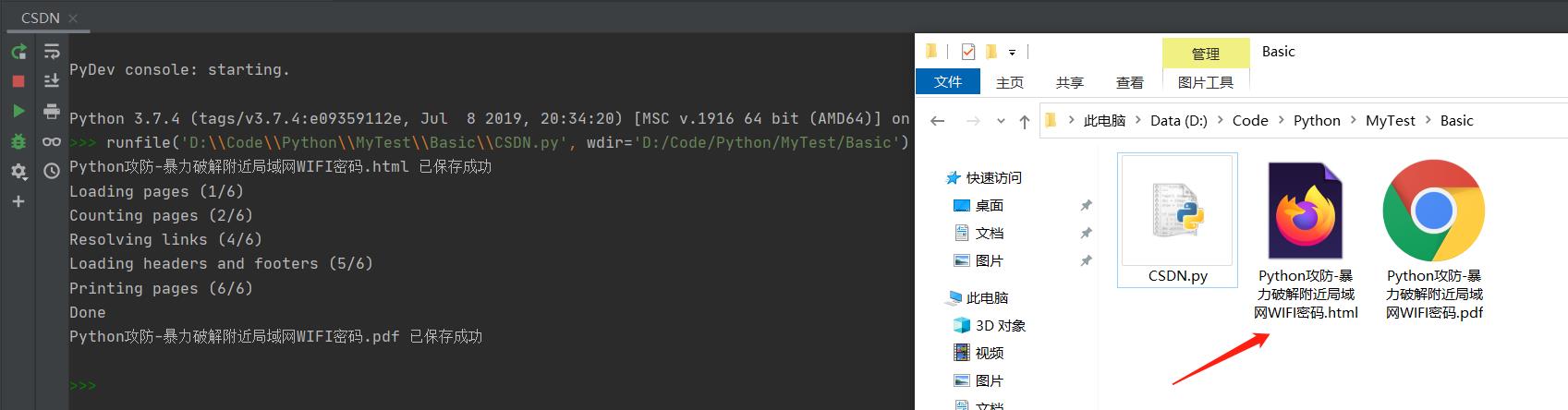 1、生成的 HTML 文档如下:
1、生成的 HTML 文档如下:
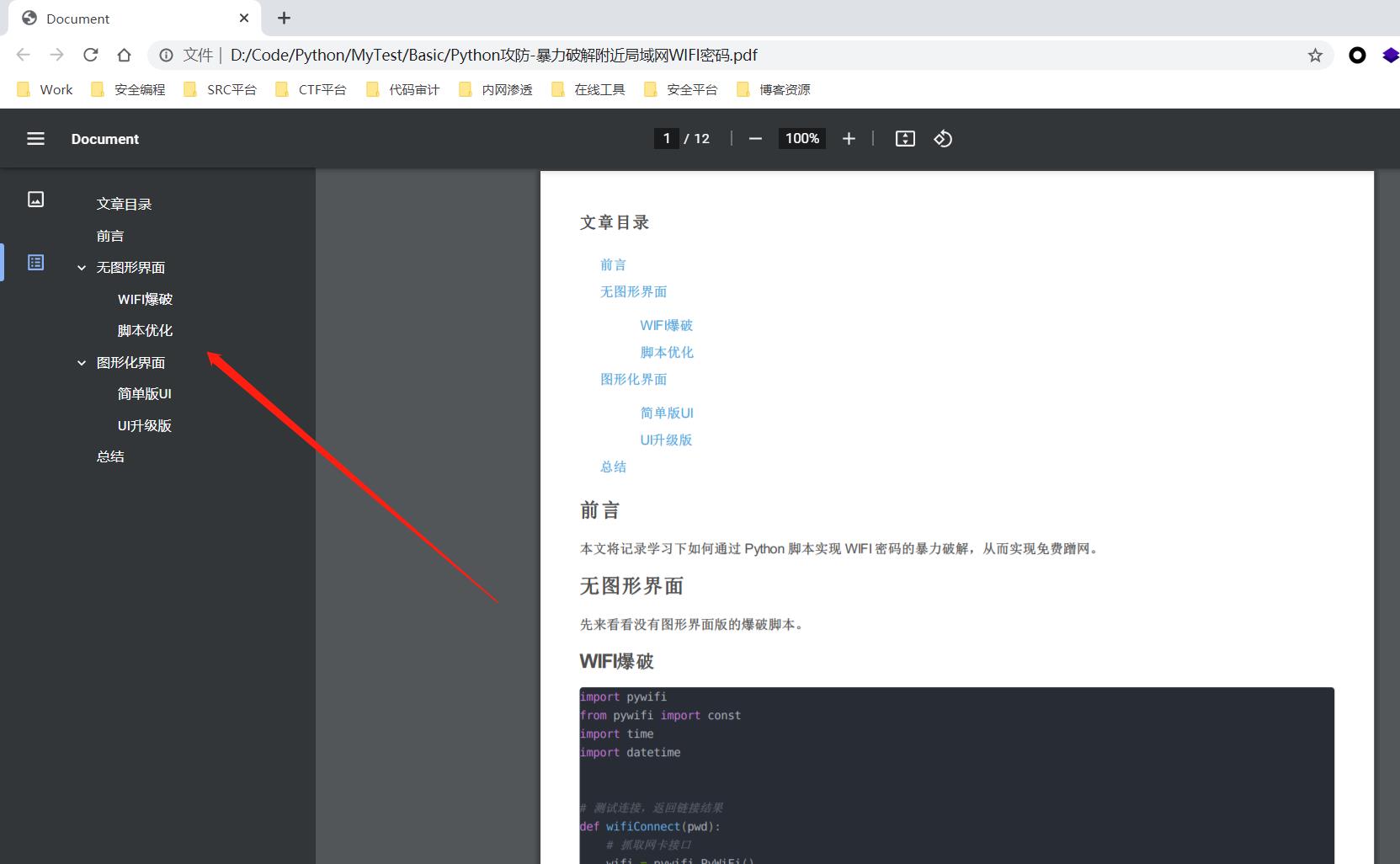
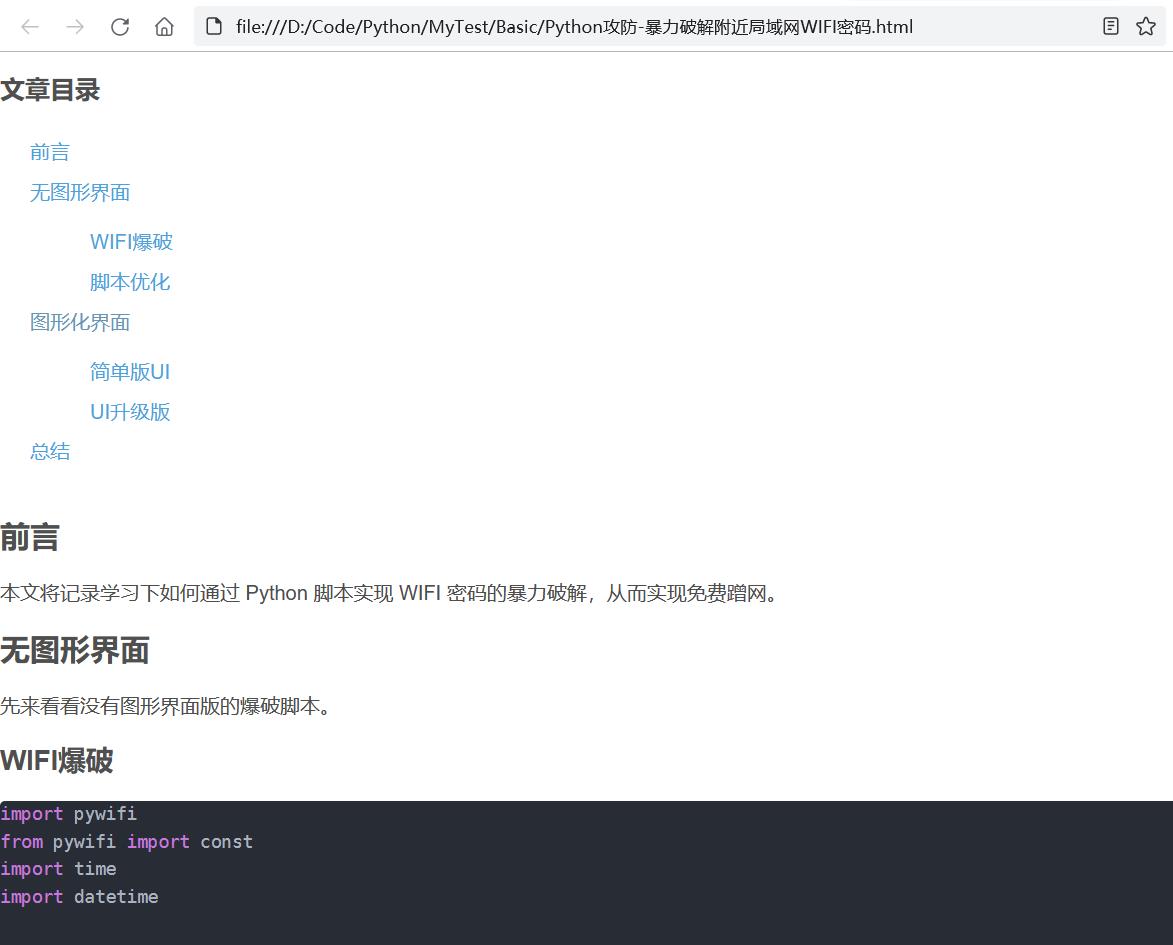 2、生成的 PDF 文件如下(带导航标签):
2、生成的 PDF 文件如下(带导航标签):
批量保存
单篇文章保存、转换解决了,那如何对某位博主的所有文章进行自动化保存转换呢?总不能一篇一篇处理吧……下面改进下脚本,实现对某位博主所有博文的批量自动化保存和转换。
脚本编写
访问我的博客主页,发现在如下所示标签里包含里当前页面的所有文章链接:
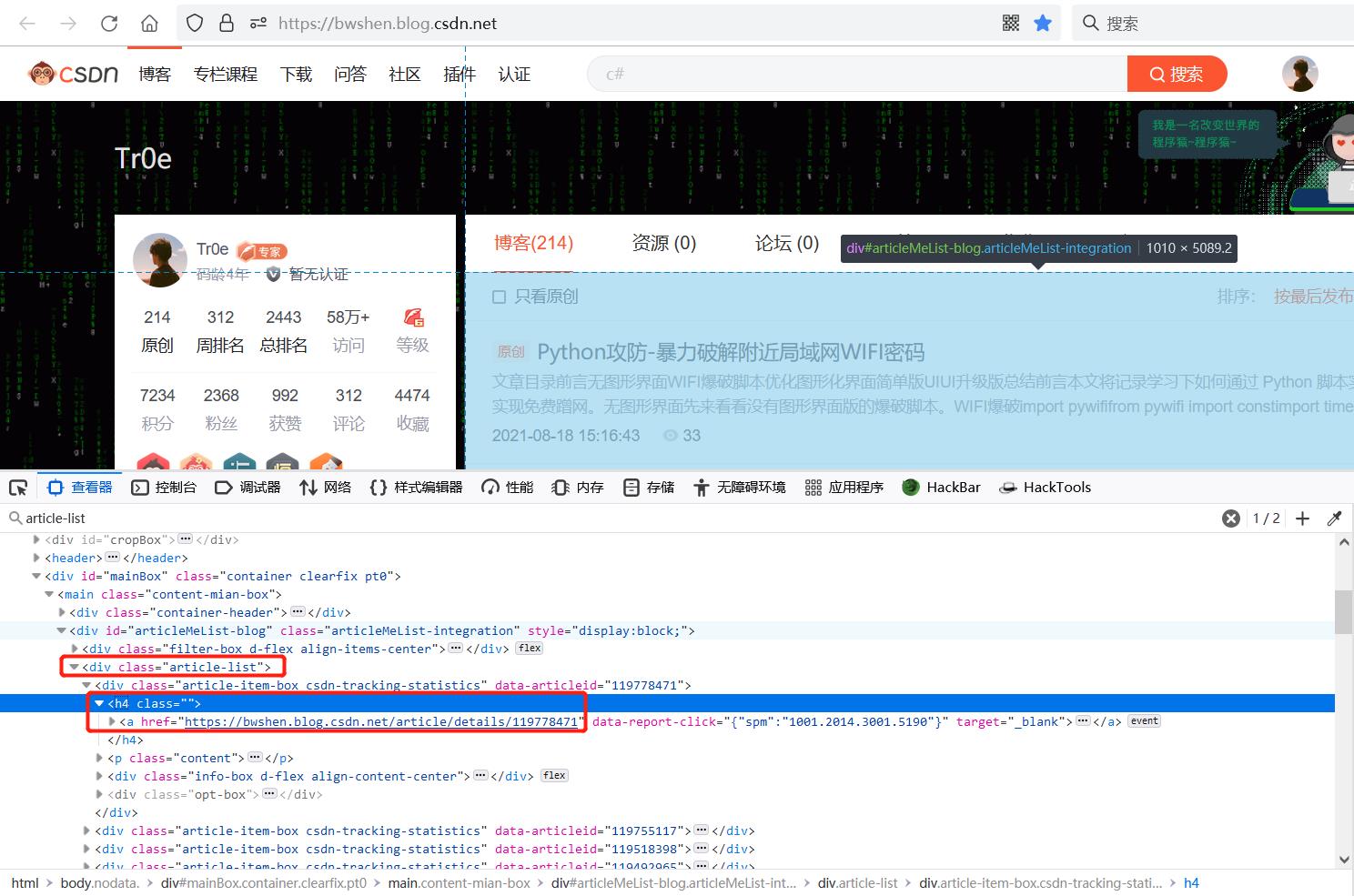 来看看完整代码:
来看看完整代码:
import pdfkit
import requests
import parsel
import time
src_html = '''
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
content
</body>
</html>
'''
headers =
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
def download_one_page(page_url):
response = requests.get(url=page_url, headers=headers)
html = response.text
selector = parsel.Selector(html)
title = selector.css('.title-article::text').get()
# 提取标签为article 的内容
article = selector.css('article').get()
# 保存HTML文档
with open(title+'.html', mode='w+', encoding='utf-8') as f:
f.write(src_html.format(content=article))
print('%s.html 已保存成功' % title)
# 将HTML转换成PDF
config = pdfkit.configuration(wkhtmltopdf=r'D:\\SoftWare\\htmltopdf\\wkhtmltopdf\\bin\\wkhtmltopdf.exe')
pdfkit.from_file(title+'.html', title+'.pdf', configuration=config)
print('%s.pdf 已保存成功' % title)
def down_all_url(index_url):
index_response = requests.get(url=index_url,headers=headers)
index_selector = parsel.Selector(index_response.text)
urls = index_selector.css('.article-list h4 a::attr(href)').getall()
for url in urls:
download_one_page(url)
time.sleep(2.5)
if __name__ == '__main__':
down_all_url('https://bwshen.blog.csdn.net/')
效果演示
代码运行效果如下:

总结
实际上若使用火狐浏览器,可借助现成的插件: PDF Saver For CSDN Blog 将某篇 CSDN 的博文保存成本地 PDF 文件,但是生成的 PDF 不带导航标签,且无法批量保存,所以还是用 Python 脚本吧。
以上是关于Python爬虫-CSDN博文存为HTML/PDF文档的主要内容,如果未能解决你的问题,请参考以下文章