数据结构之计算要点
Posted 未定_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构之计算要点相关的知识,希望对你有一定的参考价值。
数据结构
一、绪论



二、线性表

1.约瑟夫环问题
删除位置的计算
从线性表中起始位置index出发开始计数,当计数到k时(间隔k-1个数据),删除该位置上的元素;同时该位置又是下一次计数的起始位置:index=(index+k-1)%顺序表长度
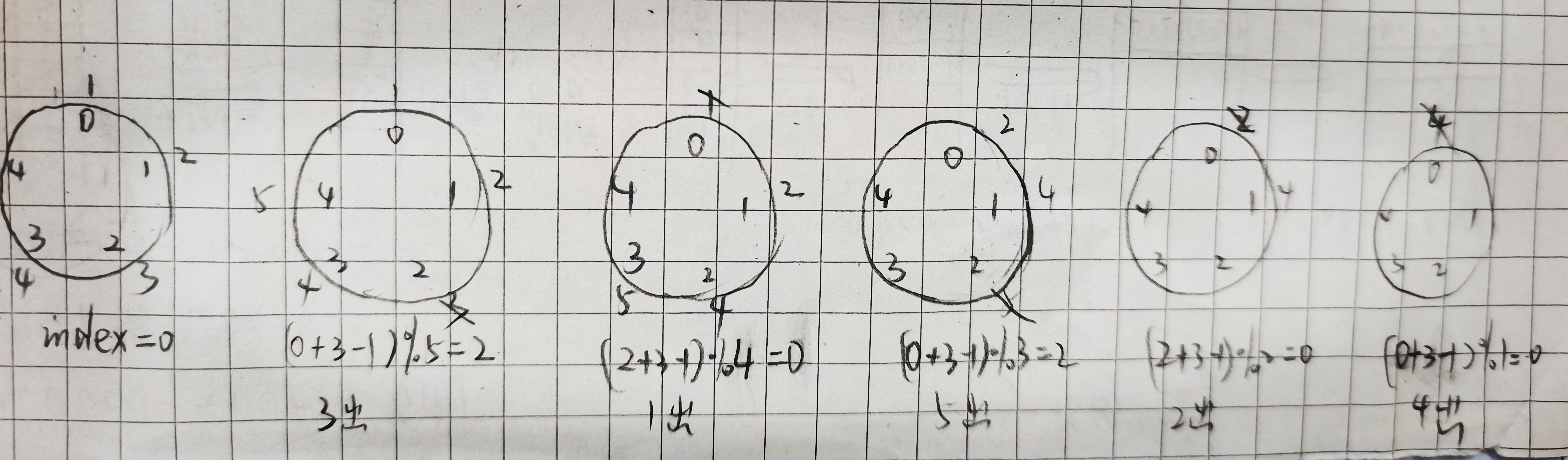
三、栈和队列
1.栈
2.循环队列
用指针front表示队头,rear表示队尾
rear=(rear+1)%QueueSize
为了区分队满与队空,当队列中还有一个空位时认为队满:
队满:(rear+1)%QueueSize=front
队空:front=rear
为了让第一个元素入到下标0处,front和rear可以在-1或数组下标最大处。
任意时刻队列中元素的个数:(rear-front+QueueSize)%QueueSize

四、数组和字符串
1.模式匹配
1.1 BF算法:
设串S长度为n,串T长度为m,在匹配成功的情况下,考虑两种极端情况:
- 最好:不成功的匹配都发生在串T的第一个字符。
∑ i = 1 n − m + 1 P i ( i − 1 + m ) \\sum_i=1^n-m+1 P_i(i-1+m) ∑i=1n−m+1Pi(i−1+m)= ( n + m ) 2 \\frac(n+m)2 2(n+m)=O(n+m)
( Pi 表示在第i个位置上匹配成功的概率,Pi= 1 n − m + 1 \\frac1n-m+1 n−m+11)
第i-1趟不成功比较了i-1次,第i趟成功比较了m次 - 最坏情况:不成功的匹配都发生在串T的最后一个字符。
∑ i = 1 n − m + 1 P i ( i ∗ m ) \\sum_i=1^n-m+1 P_i(i*m) ∑i=1n−m+1Pi(i∗m)= m ( n − m + 2 ) 2 \\fracm(n-m+2)2 2m(n−m+2)=O(n*m)
在i-1趟不成功的匹配中比较了(i-1)×m次,第i趟成功的匹配共比较了m次,所以总共比较了i×m次。
1.2 KMP模式匹配算法:
时间复杂性:O(n+m)
2.矩阵压缩
2.1 对称矩阵的压缩存储
对于下三角:
- 矩阵行列标从1开始:
aij在一维数组中的序号= i×(i-1)/2+ j
∵一维数组下标从0开始
∴aij在一维数组中的下标:k= i×(i-1)/2+ j-1 - 矩阵行列标从0开始:
aij在一维数组中的序号= i×(i+1)/2+ j+1
∵一维数组下标从0开始
∴aij在一维数组中的下标:k= i×(i+1)/2+ j
2.2 上三角矩阵的压缩存储:


2.3 对角矩阵的压缩存储:

k=(3*(i-1)-1)+(j-i+1)
k=2i+j-3
3.数组存储

五、树和二叉树
1.二叉树
1.1 基本性质
- 性质1:二叉树中,若叶子结点的个数为n0,度为2的结点个数为n2,则n0=n2+1。
- 性质2:二叉树第i层上最多有2i-1个结点(i>=1)。
- 性质3:一棵深度为k的二叉树中最多有2k-1个结点。
- 性质4:具有n个结点的完全二叉树的深度为⌊log2n⌋+1。
- 性质5:对一棵具有n个结点的完全二叉树从1开始按层序编号,对于编号为i(1<=i<=n)的结点(简称结点i),
如果i>1,则结点i的双亲的编号为⌊i/2⌋,否则是根结点无双亲。
如果2i<=n,则结点i的左孩子的编号为2i,否则无左孩子。
如果2i+1<=n,则结点i的右孩子的编号为2i+1,否则结点i无右孩子。
答: 最少2h-1 和 最多2h-1
图片来自《设高为h的二叉树(规定叶子结点的高度为1)只有度为0和2的结点,则此类二叉树的最少结点数和最多结点数分别为:》
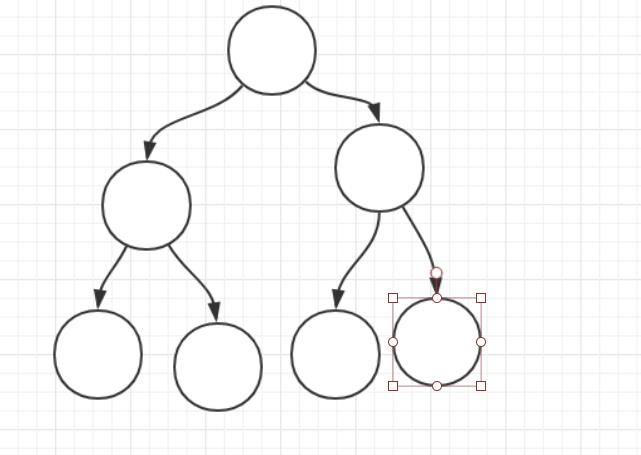
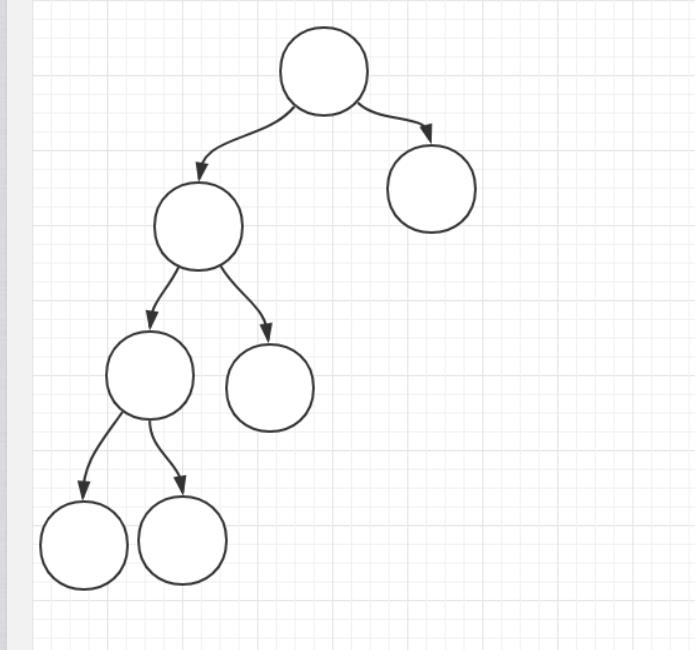
答案:至少2k-1 至多2k-1 序号2k-2+1

2.哈弗曼编码
等长编码: 所有编码都等长,表示n个不同的字符需要[log2n]位。
3.在2n个指针域中只有n-1个指针域用来存储孩子结点的地址,存在n+1个空指针,利用这些空指针存某种遍历的前序和后序结点,指向前驱和后继结点的指针称为线索,加上线索的二叉链表称为线索链表,加上线索的二叉树称为线索二叉树。

六、图
1.邻接矩阵时间和空间复杂度O(n2)
邻接表时间和空间复杂度O(n+e)
2.图的生成树唯一性不能确定,n 个顶点的生成树有 n-1条边。
3.对于含有 n 个顶点 e 条边的连通图,利用 Prim 算法求最小生成树的时间复杂度为O(n2),利用 Kruskal算法求最小生成树的时间复杂度为O(elog2e)。因为Prim 算法采用邻接矩阵做存储结构,适合于求稠密图的最小生成树;Kruskal 算法采用边集数组做存储结构,适合于求稀疏图的最小生成树。
4.可以一次性求所有结点之间的最短距离,只适合于小规模的图,时间复杂度为O(n3)
图规模小,用Floyd。如果边权值有负数,需要判断负圈。
图的规模大,且边的权值非负,用Dijkstra。
Dijkstra算法
用于求单源点最短路径问题。按照路径长度递增的顺序产生最短路径的方法,只适用于权值为正的情况。
5.AOE网与关键路径
ve[k]=max(ve[j]+len<vj,vk>)。初始化ve[0]=0
vl[k]=min(vl[j]-len<vk,vj>),vl[n-1]=ve[n-1]
e[i]=ve[k]
el[i]=vl[j]-len<vk,vj>
七、查找技术
查找算法的性能 :
平均查找长度:ASL=
∑
i
=
1
n
p
i
c
i
\\sum_i=1^n p_ic_i
∑i=1npici
pi为查找第i个记录的概率,ci为查找第i个记录所需的比较次数。
1.顺序查找
查找算法性能
- 查找成功时:
pi= 1 n \\frac1n n1,查找第i个记录需要n-i+1次比较。(因为是倒着比)
ASL= 1 n \\frac1n n1 ∑ i = 1 n ( n − i + 1 ) \\sum_i=1^n (n-i+1) ∑i=1n(n−i+1)= n ( n + 1 ) 2 \\fracn(n+1)2 2n(n+1)* 1 n \\frac1n n1= n + 1 2 \\fracn+12 2n+1=O(n) - 查找失败时:
比较次数是n-1次
ASL=O(n)
2.折半查找
判定树性质:
·任意结点的左右子树中结点个数最多相差1
·任意结点的左右子树的高度最多相差1
·任意两个叶子所处的层次最多相差1
与给定值的比较次数等于该记录结点在树中的层数。已知**判定树的深度为⌊log2n⌋+1 **,所以查找成功时,比较次数至多为⌊log2n⌋+1。
例:长度为11的有序表,比较3次就知道成功的情况有4种。(树的深度为4,第3层是满的)
查找算法性能
平均查找长度:
ASL=
∑
i
=
1
n
p
i
c
i
\\sum_i=1^n p_ic_i
∑i=1npici=
1
n
\\frac1n
n1
∑
j
=
1
k
j
∗
2
j
−
1
\\sum_j=1^k j*2^j-1
∑j=1kj∗2j−1=log2(n+1)-1(约等于)
平均时间复杂度:O(log2n)
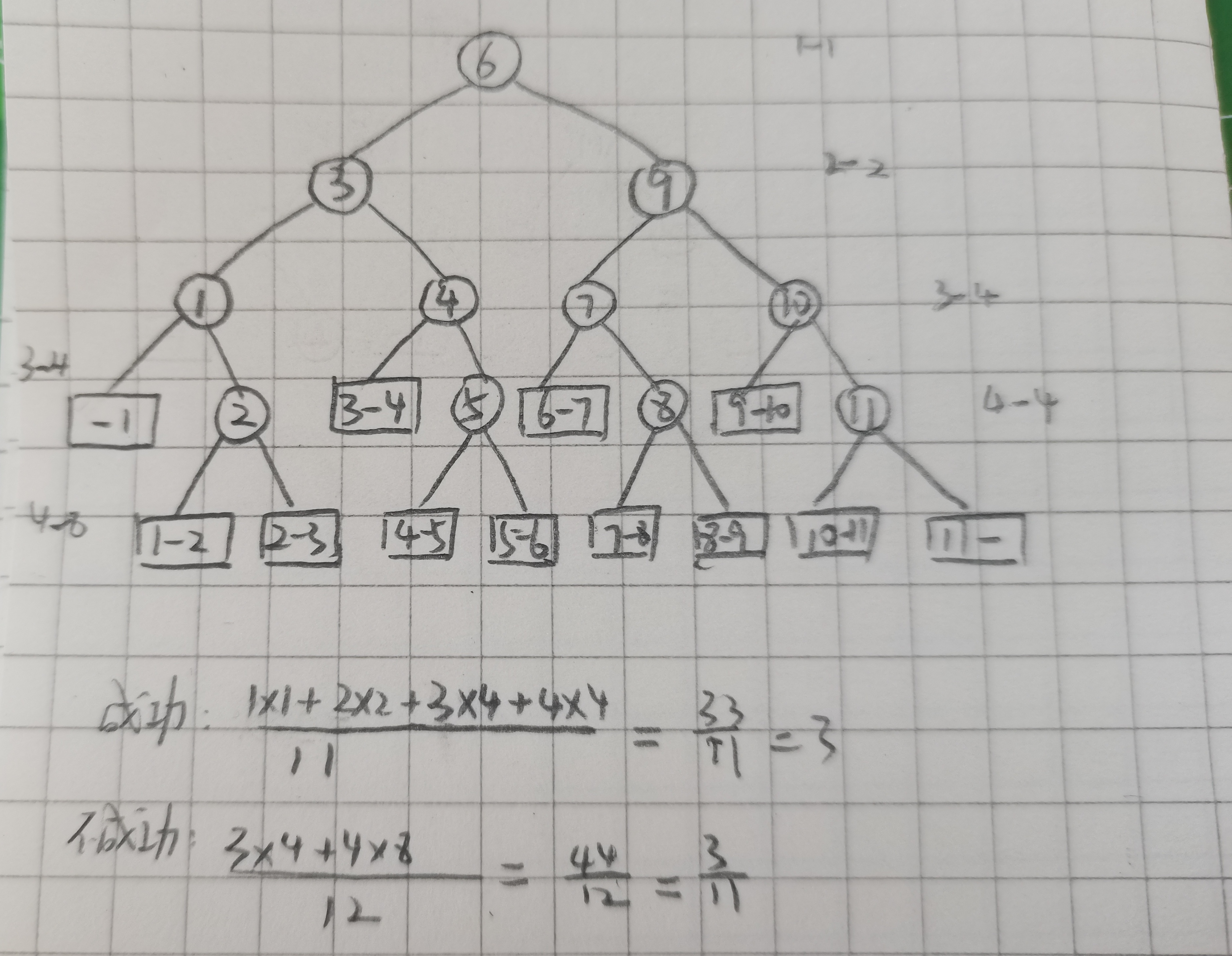
例:长度为11的有序表
查找成功时:
1
∗
2
0
+
2
∗
2
1
+
3
∗
2
2
+
4
∗
4
11
\\frac1*2^0+2*2^1+3*2^2+4*411
111∗20+2∗21+3∗22+4∗4=
33
11
\\frac3311
1133=3
不成功时:
3
∗
4
+
4
∗
8
12
\\frac3*4+4*812
123∗4+4∗8=
44
12
\\frac4412
1244=
3
11
\\frac311
113(因为和给定值进行的关键码的比较次数等于该路径上内部结点的个数,所以分子层数最大等于树的高度)
- 查找成功时:
ASL= 每 个 结 点 比 较 次 数 之 和 结 点 数 \\frac每个结点比较次数之和结点数 结点数每个结点比较次数之和 - 查找失败时:
ASL= 空 指 针 处 比 较 次 数 之 和 空 指 针 数 \\frac空指针处比较次数之和空指针数 空指针数空指针处比较次数之和 - 平均查找长度:
ASL= ∑ i = 1 n p i c i \\sum_i=1^n p_ic_i ∑i=1npici= 1 n \\frac1n n