[编译原理]词法分析实验之基于 DFA 的单词识别
Posted Spring-_-Bear
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[编译原理]词法分析实验之基于 DFA 的单词识别相关的知识,希望对你有一定的参考价值。
问题描述
基于 DFA 的单词识别问题的一种描述是:编写一个程序,输入一个确定的有穷自动机(DFA),使用该 DFA 识别单词
基本要求
设置 DFA 初始状态 X,终态 Y,过程态用数字表示:0 1 2 3 ······
样例输入
a b#
X Y 0 2#
X X-a->0 X-b->X
Y Y-a->0 Y-b->X
0 0-a->0 0-b->2
2 2-a->0 2-b->Y
abb#
ba#
aca#
样例输出
a
b
b
pass
b
a
error
a
error
输入说明
输入由 2 部分构成,第 1 部分为 DFA 的输入,其中第 1 行为有效字符,第 2 行为所有状态,第 3 行开始为状态变迁函数的表示(每个状态 1 行),以空行表示结束;第 2 部分为待识别符号串,可以包含多个,每个串以 ‘#’ 结束
输出说明
输出对每个待识别字串的单词识别情况。正确识别出 1 个单词则输出该单词,全部正确识别最后输出 pass;识别单词时出现错误则输出 error,识别结束。示例分析如下:
- 对于串 “abb#” 是全部单词正确识别,且遇 “#” 时进入终态
- 对于串 “ba#” 是能识别每个单词,但遇 “#” 时未进入终态,所以会输出每个单词,但最终为 "error”
- 对于串 “aca#” 是在识别到 “c” 时出错(非法字符),因此程序终止在这里,输出 “a” 和 “error”
DFA 状态转换图
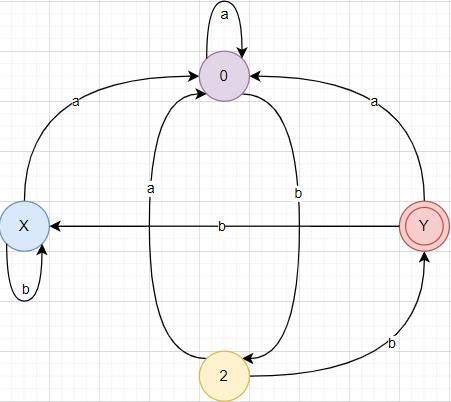
源码
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Scanner;
/**
* 基于 DFA 的单词识别
*
* @author Spring-_-Bear
* @date 2021-12-24 20:43
*/
public class Solution
private static final Scanner SCANNER = new Scanner(System.in);
public static void main(String[] args)
Solution solution = new Solution();
ArrayList<String> dfaInit = solution.dfaInit();
String validCharacters = dfaInit.get(0);
HashMap<String, String> stateMap = solution.toStateMap(dfaInit);
// 测试用例:abb# ba# aca#
String line;
while (!"".equals((line = SCANNER.nextLine())))
// 输入测试用例进行测试,因每行测试用例最后一个字符总为 # ,故不妨将 line 有效长度 -1
int len = line.length() - 1;
String state = "X";
int flag = 1;
// 依次遍历测试用例的每一个字符
for (int i = 0; i < len; i++)
char ch = line.charAt(i);
// 判断当前字符是否有效,不合法则输出 error,测试下一条用例
if (!validCharacters.contains(String.valueOf(ch)))
System.out.println("error");
flag = 0;
break;
// 获取当前状态 + 当前字符后转移到的状态
state = state + ch;
if (stateMap.containsKey(state))
System.out.println(ch);
state = stateMap.get(state);
// 判断末状态是否是终态 Y ,是则输出 pass,否则输出 error
if (flag == 1)
if ("Y".equals(state))
System.out.println("pass");
else
System.out.println("error");
/**
* 将状态变迁函数格式化为 key - value 形式,即: 初态 + 输入内容 -> 终态 例:Xa -> 0
*
* @param dfaInit DFA 内容
* @return 状态变迁函数集合
*/
public HashMap<String, String> toStateMap(ArrayList<String> dfaInit)
HashMap<String, String> stateMap = new HashMap<>(10);
// 集合 dfaFormat 中第一行为合法字符,第二行为所有状态,第三行开始为状态变迁函数,直接从第三行开始
int i = 2;
int size = dfaInit.size();
while (i < size)
String stateStr = dfaInit.get(i);
int len = stateStr.length();
StringBuilder stringBuilder = new StringBuilder();
/*
* 过滤调状态变迁函数中的非法字符,如 " "、-、>
* 因每行状态变迁函数的第一个字符为状态说明,第二个字符为空格,故直接从第三个字符开始遍历
*/
for (int j = 2; j < len; j++)
char ch = stateStr.charAt(j);
if (Character.isDigit(ch) || Character.isLetter(ch))
stringBuilder.append(ch);
stateStr = stringBuilder.toString();
// 每两相邻两个字符组成一个 key,下一个字符构成 value
len = stateStr.length();
for (int k = 0; k < len; k += 3)
String key = stateStr.charAt(k) + "" + stateStr.charAt(k + 1);
String value = stateStr.charAt(k + 2) + "";
stateMap.put(key, value);
++i;
return stateMap;
/**
* 初始化 DFA 内容
*
* @return DFA 内容集合
*/
public ArrayList<String> dfaInit()
String[] dfa = new String[]
"a b#",
"X Y 0 2#",
"X X-a->0 X-b->X",
"Y Y-a->0 Y-b->X",
"0 0-a->0 0-b->2",
"2 2-a->0 2-b->Y"
;
return new ArrayList<>(Arrays.asList(dfa));
/**
* DFA 的输入,其中第 1 行为有效字符,第 2 行为所有状态,第 3 行开始为状态变迁函数的表示(每个状态 1 行),以空行表示结束
*
* @return DFA 内容集合
*/
public ArrayList<String> dfaInput()
ArrayList<String> dfaList = new ArrayList<>();
String str;
while (!"".equals((str = SCANNER.nextLine())))
dfaList.add(str);
return dfaList;
以上是关于[编译原理]词法分析实验之基于 DFA 的单词识别的主要内容,如果未能解决你的问题,请参考以下文章