Flink 极简教程: 架构及原理 Apache Flink® — Stateful Computations over Data Streams
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 极简教程: 架构及原理 Apache Flink® — Stateful Computations over Data Streams相关的知识,希望对你有一定的参考价值。

Flink 极简教程: 架构及原理 Apache Flink® — Stateful Computations over Data Streams
关键词
分布式流处理
分布式计算引擎
All streaming use cases
- Event-driven Applications
- Stream & Batch Analytics
- Data Pipelines & ETL
Guaranteed correctness
- Exactly-once state consistency
- Event-time processing
- Sophisticated late data handling
Layered APIs
- SQL on Stream & Batch Data
- DataStream API & DataSet API
- ProcessFunction (Time & State)
Operational Focus
- Flexible deployment
- High-availability setup
- Savepoints
Scales to any use case
- Scale-out architecture
- Support for very large state
- Incremental checkpointing
Excellent Performance
- Low latency
- High throughput
- In-Memory computing
Flink 是什么?
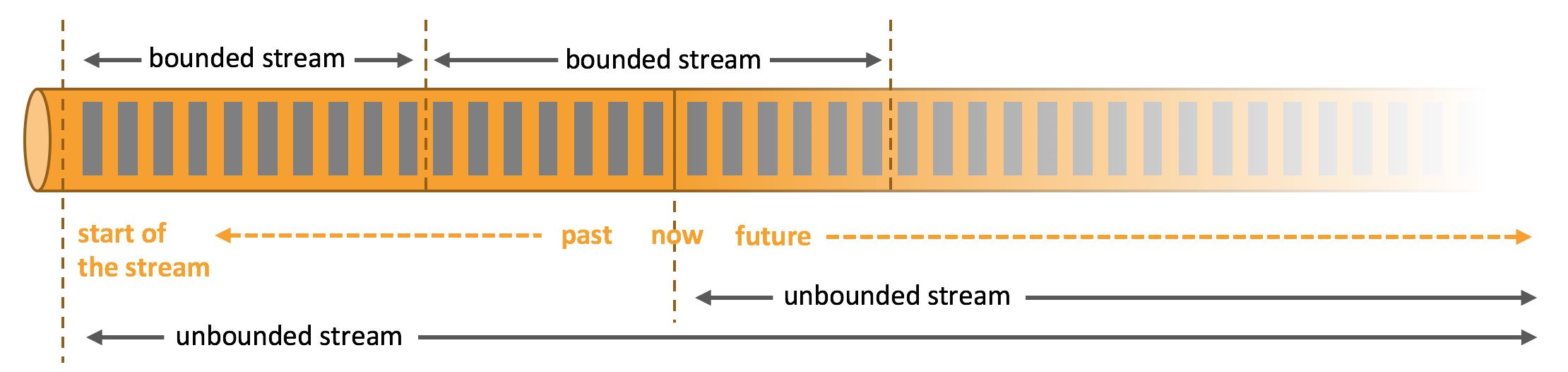
Apache Flink 是一个分布式流计算引擎,用于在无边界和有边界数据流上进行有状态的计算。
Flink 的核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
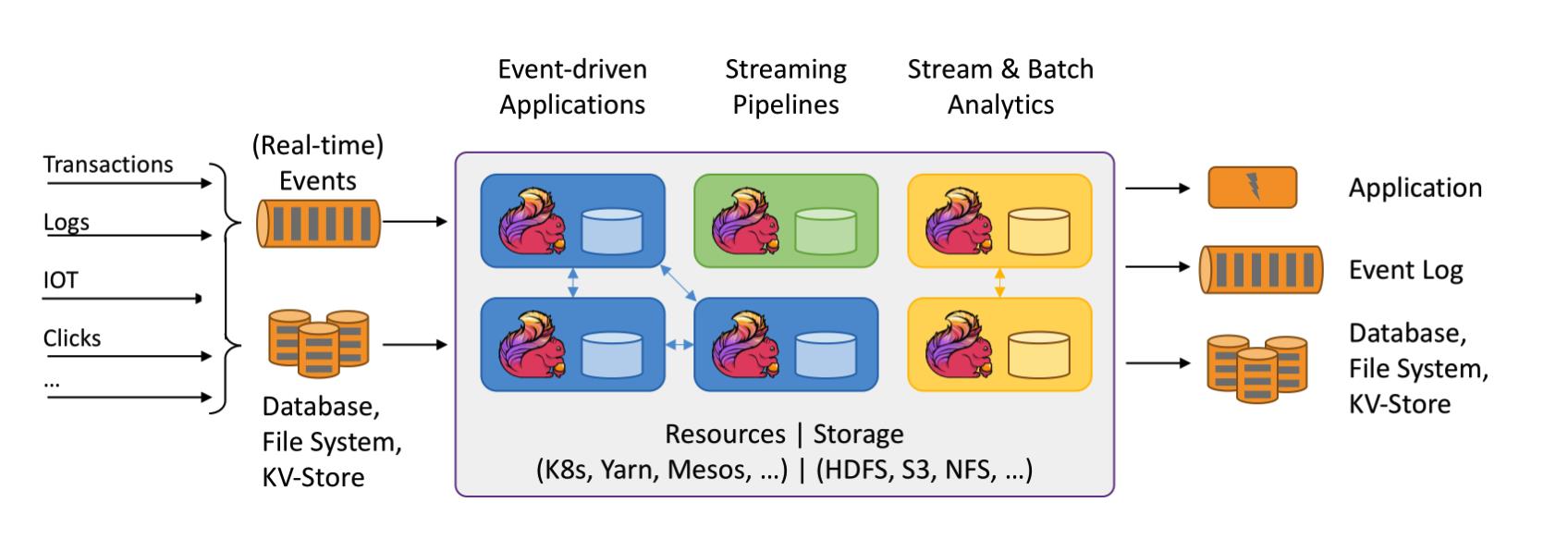
Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
参考: https://flink.apache.org/zh/flink-architecture.html
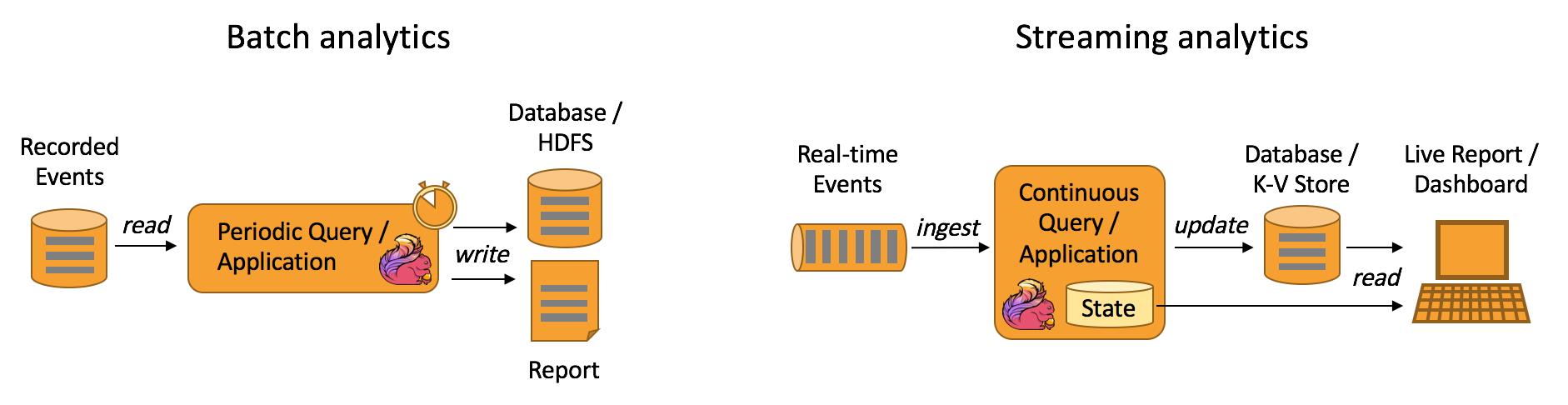
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。
现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为他们它们所提供的SLA是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是通过一个独立的开源框架来实现其中每一种处理方案。
1.实现批处理的开源方案有 MapReduce、Tez、Crunch、Spark.
2.实现流处理的开源方案有 Samza、Storm .
Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
基本特性
关于Flink所支持的特性,我这里只是通过分类的方式简单做一下梳理,涉及到具体的一些概念及其原理会在后面的部分做详细说明。
流处理特性
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口(Window)操作
支持有状态计算的Exactly-once语义
支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
支持具有Backpressure功能的持续流模型
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持Batch on Streaming处理和Streaming处理
Flink在JVM内部实现了自己的内存管理
支持迭代计算
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
API支持
对Streaming数据类应用,提供DataStream API
对批处理类应用,提供DataSet API(支持Java/Scala)
Libraries支持
支持机器学习(FlinkML)
支持图分析(Gelly)
支持关系数据处理(Table)
支持复杂事件处理(CEP)
整合支持
支持Flink on YARN
支持HDFS
支持来自Kafka的输入数据
支持Apache HBase
支持Hadoop程序
支持Tachyon
支持ElasticSearch
支持RabbitMQ
支持Apache Storm
支持S3
支持XtreemFS
基本概念
Stream
Transformation
Operator
用户实现的Flink程序是由Stream和Transformation这两个基本构建块组成,其中Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。当一个Flink程序被执行的时候,它会被映射为Streaming Dataflow。一个Streaming Dataflow是由一组Stream和Transformation Operator组成,它类似于一个DAG图,在启动的时候从一个或多个Source Operator开始,结束于一个或多个Sink Operator。
Dataflow Programming Model
Flink核心是一个流式的数据流执行引擎,并且能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用。
Flink 针对数据流的分布式计算提供了数据分布,数据通信及容错机制等功能。基于流执行引擎,Flink提供了跟多高抽象层的API , 便于用户编写分布式任务。
Levels of Abstraction
Flink offers different levels of abstraction to develop streaming/batch applications.
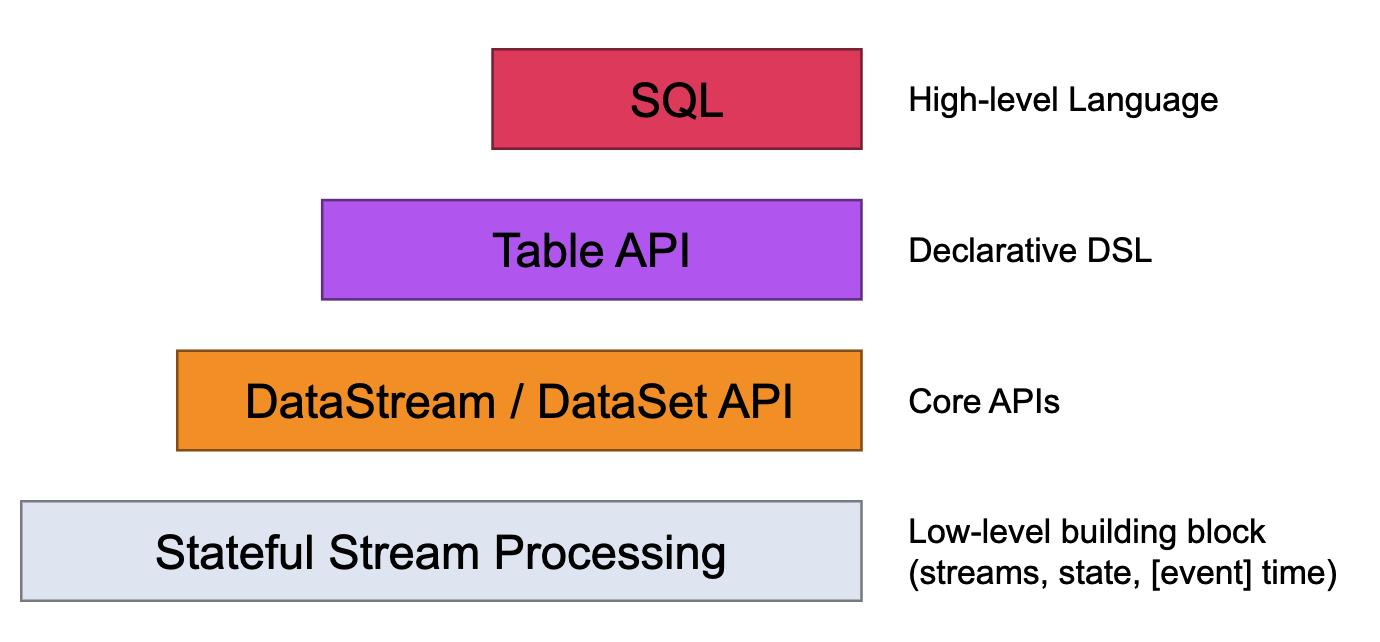
最低级别的抽象只是提供有状态的流(stateful streaming)。它 通过Process Function嵌入到DataStream API 中。它允许用户自由处理来自一个或多个流的事件,并使用一致的容错状态。此外,用户可以注册事件时间和处理时间回调,允许程序实现复杂的计算。
DataStream API (bounded/unbounded streams) and the DataSet API (bounded data sets)
: 实际上,大多数应用程序不需要上述低级抽象,而是针对核心 API 进行编程, 例如DataStream API(有界/无界流)和DataSet API (有界数据集)。这些流畅的 API 为数据处理提供了通用的构建块,如各种形式的用户指定的转换、连接、聚合、窗口、状态等。这些 API 中处理的数据类型在各自的编程语言中表示为类。低级Process Function与DataStream API集成,使得仅对某些操作进行低级抽象成为可能。该数据集API提供的有限数据集的其他原语,如循环/迭代。表API: The Table API is a declarative DSL centered around tables, which may be dynamically changing tables (when representing streams)。Tables have a schema attached (similar to tables in relational databases) and the API offers comparable operations, such as select, project, join, group-by, aggregate, etc. Table API programs declaratively define what logical operation should be done rather than specifying exactly how the code for the operation looks. Though the Table API is extensible by various types of user-defined functions, it is less expressive than the Core APIs, but more concise to use (less code to write). In addition, Table API programs also go through an optimizer that applies optimization rules before execution 。尽管 Table API 可以通过各种类型的用户定义函数进行扩展,但它的表现力不如核心 API,但使用起来更简洁(编写的代码更少)。此外,Table API 程序在执行前还会经过一个优化器,该优化器会应用优化规则。
可以在表和DataStream / DataSet之间无缝转换,允许程序混合Table API以及DataStream 和DataSet API。 One can seamlessly convert between tables and DataStream/DataSet, allowing programs to mix Table API and with the DataStream and DataSet APIs.
- Flink 提供的最高级别抽象是SQL。这种抽象在语义和表达上都类似于Table API,但将程序表示为 SQL 查询表达式。在SQL抽象与表API SQL查询紧密地相互作用,并且可以在中定义的表执行表API。
- The highest level abstraction offered by Flink is SQL. This abstraction is similar to the Table API both in semantics and expressiveness, but represents programs as SQL query expressions. The SQL abstraction closely interacts with the Table API, and SQL queries can be executed over tables defined in the Table API.
下面具体介绍常见的几种API:
DataSet API
对静态数据进行批处理作业,将静态数据抽象成分布式的数据集,用户可以方便的使用Flink提供的各种操作符对分布式数据集进行处理,支持Java,Scala和python;
DataStream API
对数据流进行流处理作业,将流式的数据抽象成分布式的数据流,用户可以方面的对分布式数据流进行各种操作,支持Java,scala和python;
Table API
对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过SQL的DSL对关系表进行各种查询操作,支持Java和Scala;
SQL
SQL查询是使用TableEnvironment的sqlquery()方法执行的,该方法以SQL的形式返回SQL查询的结果。Table可以在后续的SQL和Table API查询中使用,可以转换诶DataSet和DataStream,也可以写入TableSink。SQL和Table API可以无缝的整合,进行整体优化并转换为单个程序。要访问SQL中查询的表,必须在TableEnvironment中注册他,可以从TableSource,Table,DataStream和DataSet注册表,用户也可以在TableEnvironment中注册外部目录以制定数据源的位置。Blink开源后,将使Flink SQL更加完善稳定。
StateFul Stream Processing
最低级抽象只提供有状态流,通过Process Function嵌入到DataStream API中,它允许用户自由处理来自一个或者多个流的时间,并使用一致的容错状态,此外用户可以注册event time和processing time回调,允许程序实现复杂的计算。
程序和数据流 Programs and Dataflows
Flink 程序的基本构建块是流和转换。(请注意,Flink 的 DataSet API 中使用的 DataSet 在内部也是流——稍后会详细介绍。)从概念上讲,流是(可能永无止境的)数据记录流,而转换是将一个或多个流作为输入,并因此产生一个或多个输出流。
当执行时,Flink 程序被映射到流数据流,由流和转换操作符组成。每个数据流以一个或多个源开始,以一个或多个接收器结束。数据流类似于任意有向无环图 (DAG)。
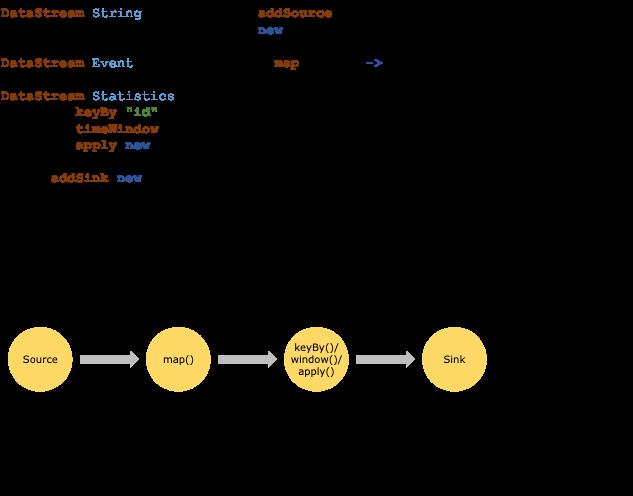
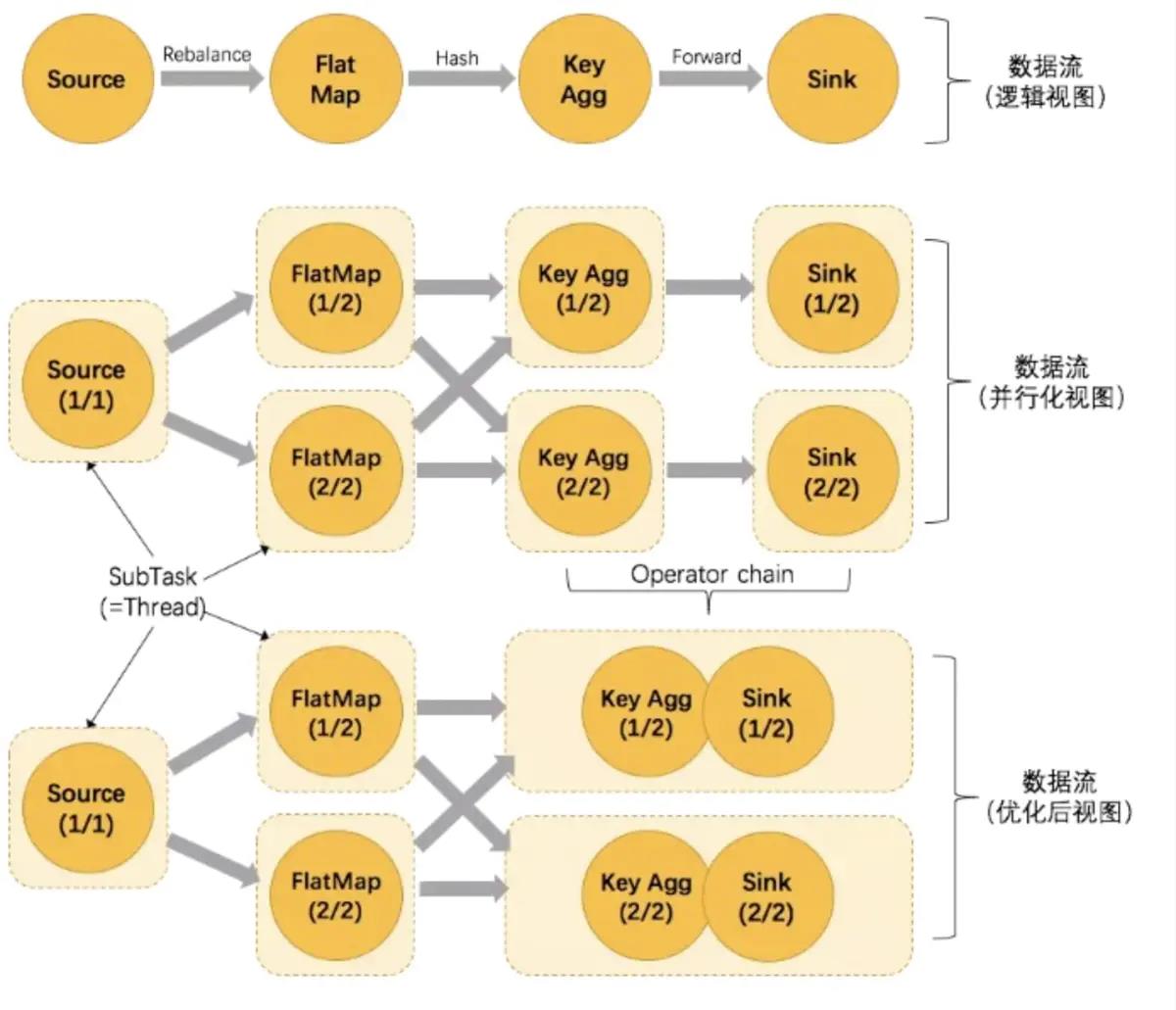
并行数据流 Parallel Dataflows
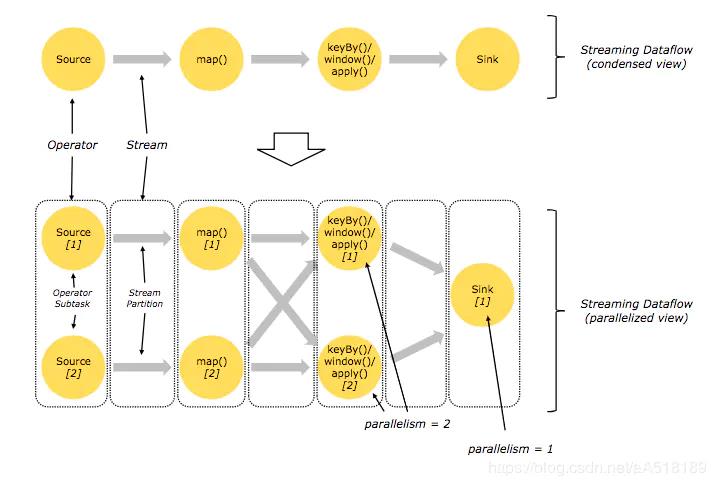
Flink 中的程序本质上是并行和分布式的。在执行过程中,一个流有一个或多个流分区,每个算子有一个或多个算子子任务。运算符子任务彼此独立,并在不同的线程中执行,并且可能在不同的机器或容器上执行。
运算符子任务的数量是该特定运算符的并行度。流的并行性始终是其生产运算符的并行性。同一程序的不同操作符可能具有不同级别的并行性。
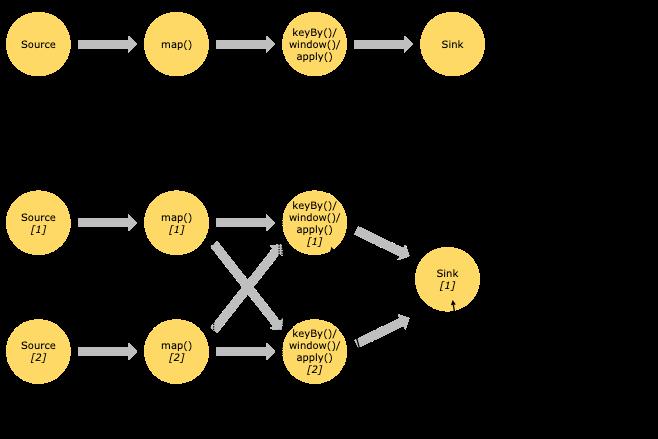
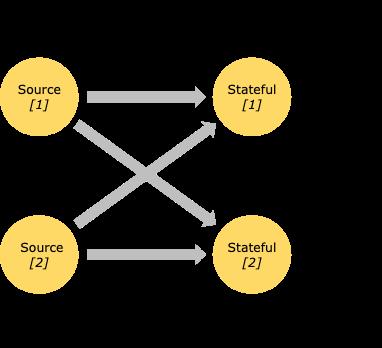
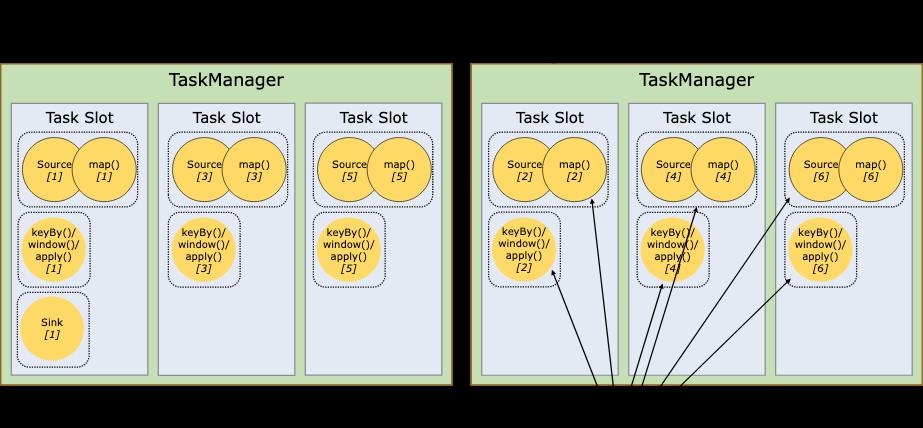
Streams can transport data between two operators in a one-to-one (or forwarding) pattern, or in a redistributing pattern:
One-to-one streams (for example between the Source and the map() operators in the figure above) preserve the partitioning and ordering of the elements. That means that subtask[1] of the map() operator will see the same elements in the same order as they were produced by subtask[1] of the Source operator.
Redistributing streams (as between map() and keyBy/window above, as well as between keyBy/window and Sink) change the partitioning of streams. Each operator subtask sends data to different target subtasks, depending on the selected transformation. Examples are keyBy() (which re-partitions by hashing the key), broadcast(), or rebalance() (which re-partitions randomly). In a redistributing exchange the ordering among the elements is only preserved within each pair of sending and receiving subtasks (for example, subtask[1] of map() and subtask[2] of keyBy/window). So in this example, the ordering within each key is preserved, but the parallelism does introduce non-determinism regarding the order in which the aggregated results for different keys arrive at the sink.
Details about configuring and controlling parallelism can be found in the docs on parallel execution.
Windows
聚合事件(例如,计数、总和)在流上的工作方式与在批处理中的工作方式不同。例如,不可能对流中的所有元素进行计数,因为流通常是无限的(无界)。相反,流上的聚合(计数、总和等)由windows限定范围,例如“过去 5 分钟内的计数”或“最后 100 个元素的总和”。
Windows 可以是时间驱动的(例如:每 30 秒)或数据驱动的(例如:每 100 个元素)。通常区分不同类型的窗口,例如翻滚窗口(无重叠)、 滑动窗口(有重叠)和会话窗口(由不活动的间隙打断)。
Aggregating events (e.g., counts, sums) works differently on streams than in batch processing. For example, it is impossible to count all elements in a stream, because streams are in general infinite (unbounded). Instead, aggregates on streams (counts, sums, etc), are scoped by windows, such as “count over the last 5 minutes”, or “sum of the last 100 elements”.
Windows can be time driven (example: every 30 seconds) or data driven (example: every 100 elements). One typically distinguishes different types of windows, such as tumbling windows (no overlap), sliding windows (with overlap), and session windows (punctuated by a gap of inactivity).

Time
在流式程序中提及时间时(例如定义窗口),可以指代不同的时间概念:
事件时间是创建事件的时间。它通常由事件中的时间戳描述,例如由生产传感器或生产服务附加。Flink 通过时间戳分配器访问事件时间戳。
摄取时间是事件在源运营商处进入 Flink 数据流的时间。
处理时间是执行基于时间的操作的每个操作员的本地时间。
When referring to time in a streaming program (for example to define windows), one can refer to different notions of time:
Event Time is the time when an event was created. It is usually described by a timestamp in the events, for example attached by the producing sensor, or the producing service. Flink accesses event timestamps via timestamp assigners.
Ingestion time is the time when an event enters the Flink dataflow at the source operator.
Processing Time is the local time at each operator that performs a time-based operation.
Stateful Operations
虽然数据流中的许多操作一次只查看一个单独的事件(例如事件解析器),但有些操作会记住多个事件的信息(例如窗口操作符)。这些操作称为有状态的。
有状态操作的状态可以被视为嵌入式键/值存储。状态与有状态操作符读取的流一起被严格地划分和分布。因此,在keyBy()函数之后,只能在键控流上访问键/值状态,并且仅限于与当前事件键关联的值。对齐流和状态的键可确保所有状态更新都是本地操作,保证一致性而没有事务开销。这种对齐还允许 Flink 重新分配状态并透明地调整流分区。
While many operations in a dataflow simply look at one individual event at a time (for example an event parser), some operations remember information across multiple events (for example window operators). These operations are called stateful.
The state of stateful operations is maintained in what can be thought of as an embedded key/value store. The state is partitioned and distributed strictly together with the streams that are read by the stateful operators. Hence, access to the key/value state is only possible on keyed streams, after a keyBy() function, and is restricted to the values associated with the current event’s key. Aligning the keys of streams and state makes sure that all state updates are local operations, guaranteeing consistency without transaction overhead. This alignment also allows Flink to redistribute the state and adjust the stream partitioning transparently.
容错检查点
Flink 使用流重放和检查点的组合来实现容错。检查点与每个输入流中的特定点以及每个操作符的相应状态相关。流数据流可以从检查点恢复,同时通过恢复操作符的状态和从检查点重放事件来保持一致性(恰好一次处理语义)。
检查点间隔是一种权衡执行期间容错开销与恢复时间(需要重放的事件数)的方法。
Flink 核心组件
分布式系统需要解决:分配和管理在集群的计算资源、处理配合、持久和可访问的数据存储、失败恢复。Fink专注分布式流处理。
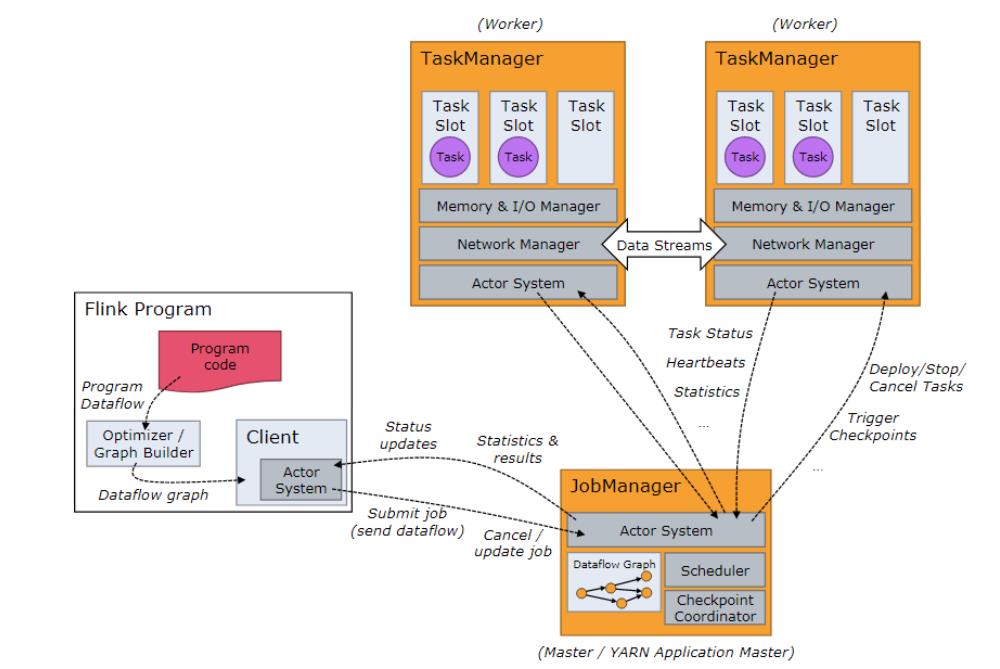
Components of a Flink Setup
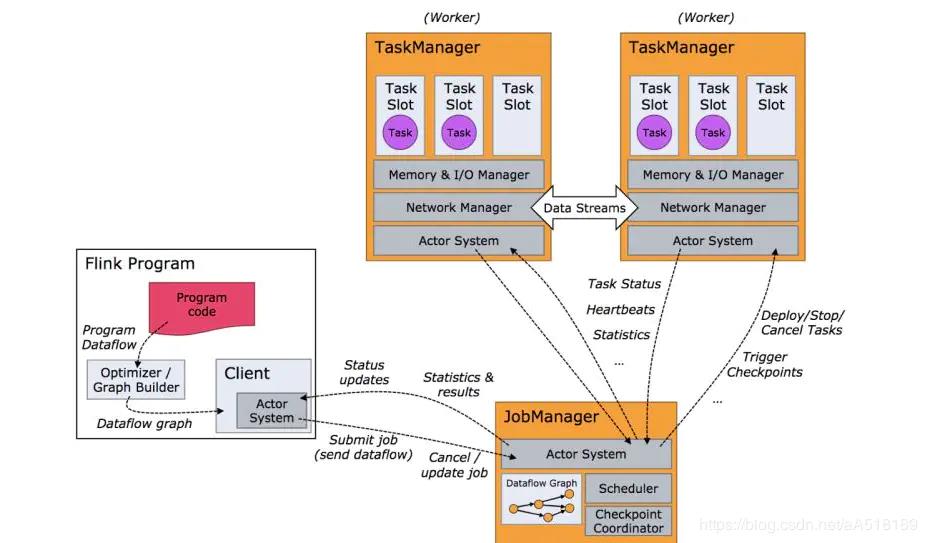
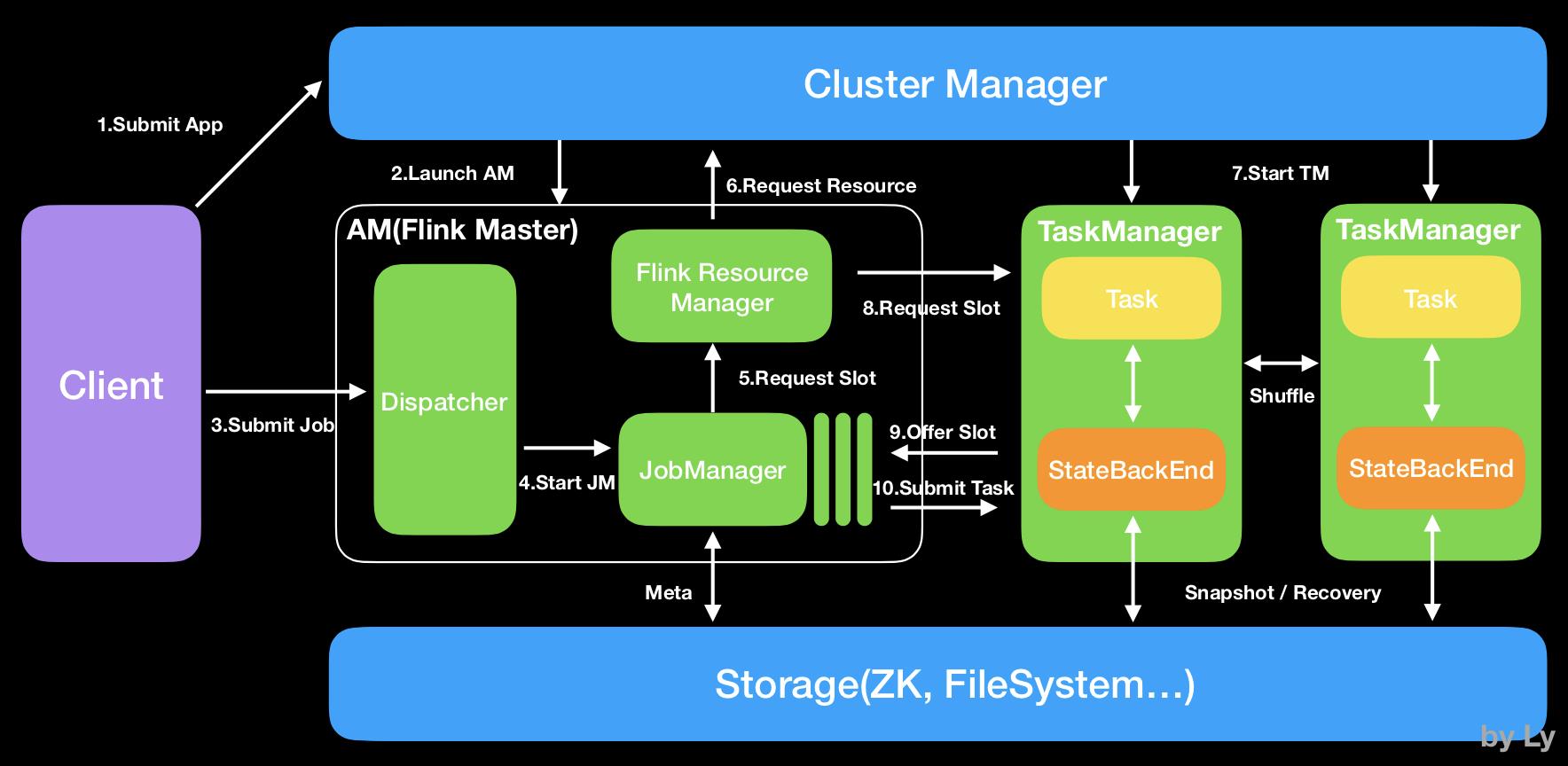
1.JobManager
接收 Application,包含StreamGraph(DAG)、JobGraph(logical dataflow graph,已经进过优化,如task chain)和JAR,将JobGraph转化为ExecutionGraph(physical dataflow graph,并行化),包含可以并发执行的tasks。其他工作类似Spark driver,如向RM申请资源、schedule tasks、保存作业的元数据,如checkpoints。JM可分为JobMaster和ResourceManager(和下面的不同),分别负责任务和资源,在Session模式下启动多个job就会有多个JobMaster。
Job Managers, Task Managers, Clients
The Flink runtime consists of two types of processes:
-
The JobManagers (also called masters) coordinate the distributed execution. They schedule tasks, coordinate checkpoints, coordinate recovery on failures, etc.
There is always at least one Job Manager. A high-availability setup will have multiple JobManagers, one of which one is always the leader, and the others are standby.
-
The TaskManagers (also called workers) execute the tasks (or more specifically, the subtasks) of a dataflow, and buffer and exchange the data streams.
There must always be at least one TaskManager.
The JobManagers and TaskManagers can be started in various ways: directly on the machines as a standalone cluster, in containers, or managed by resource frameworks like YARN or Mesos. TaskManagers connect to JobManagers, announcing themselves as available, and are assigned work.
The client is not part of the runtime and program execution, but is used to prepare and send a dataflow to the JobManager. After that, the client can disconnect, or stay connected to receive progress reports. The client runs either as part of the Java/Scala program that triggers the execution, or in the command line process
./bin/flink run ....
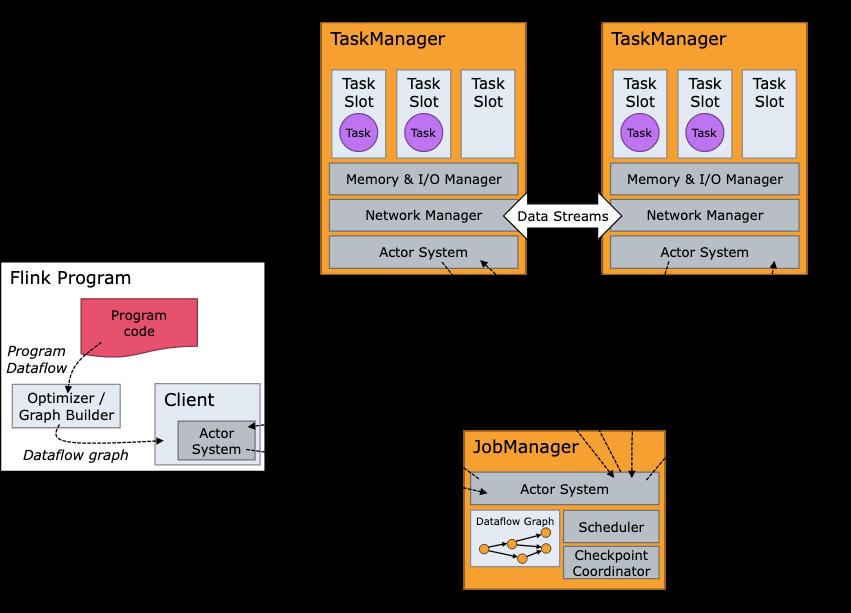
2.ResourceManager
一般是Yarn,当TM有空闲的slot就会告诉JM,没有足够的slot也会启动新的TM。kill掉长时间空闲的TM。
3.TaskManager
类似Spark的executor,会跑多个线程的task、数据缓存与交换。
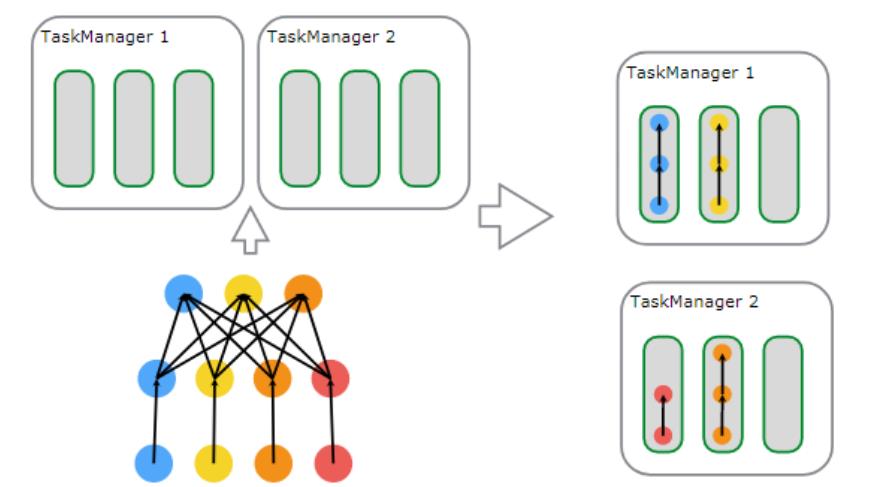
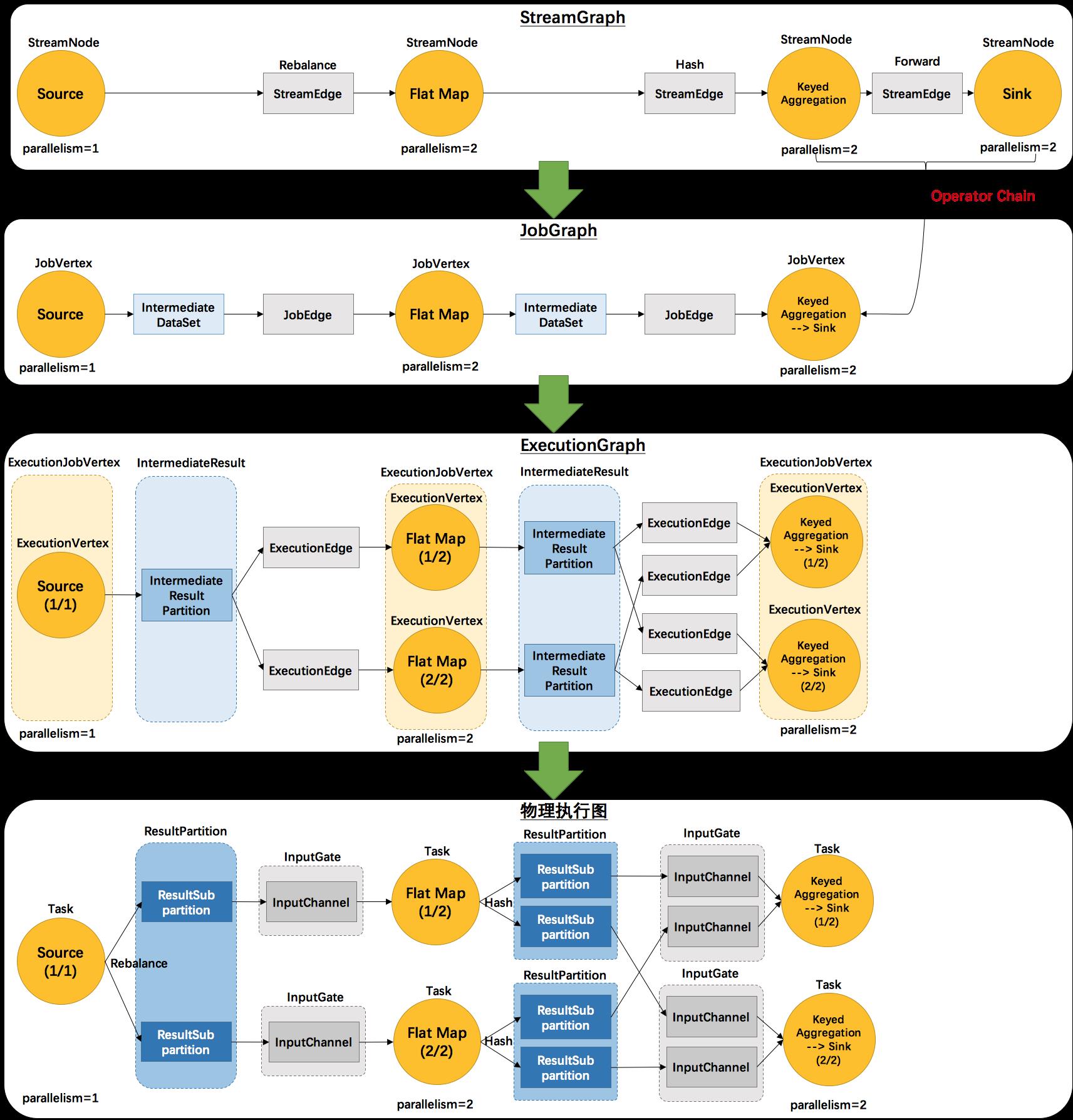
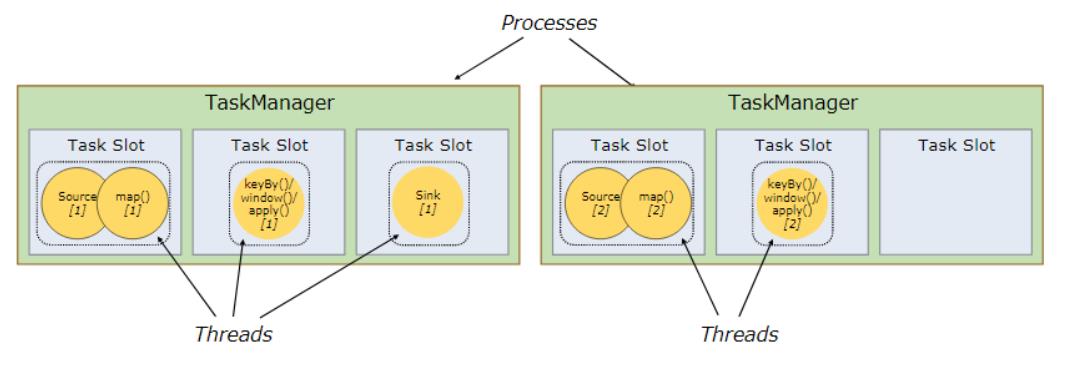
source(),map()形成一个操作链, keyBy(), window(), apply() 形成一个操作链。
Flink这样设计的目的在于,操作链中的所有操作可以使用一个线程来执行,这样可以避免多个操作在不同线程执行带来的上下文切换损失,并且可以直接在一个jvm中共享数据
4.Dispatcher(Application Master)
提供REST接口来接收client的application提交,它负责启动JM和提交 Application,同时运行Web UI。
5.Task
Task 是最基本的调度单位,由一个线程执行,里面包含一个或多个operator。多个operators就成为operation chain,需要上下游并发度一致,且传递模式(之前的Data exchange strategies)是forward。
flink的taskmanager运行task的时候是每个task采用一个单独的线程,这就会带来很多线程切换开销,进而影响吞吐量。为了减轻这种情况,flink进行了优化,也即对subtask进行链式操作,链式操作结束之后得到的task,再作为一个调度执行单元,放到一个线程里执行。如下图的,source/map 两个算子进行了链式;keyby/window/apply有进行了链式,sink单独的一个。
Task 执行: Spark中每个Stage中的Task会被分配到一个Worker中的 -> Executor容器里面的 -> 一个线程池中被执行,Flink称每个Executor为一个TaskManager,每个TaskManager中会有多个slot作为内存隔离:
Spark: Worker ——> Executor ——> 线程池 ——> 线程
Flink: Worker ——> TaskManager ——> Slot ——> 线程
6.Task Slots and Resources
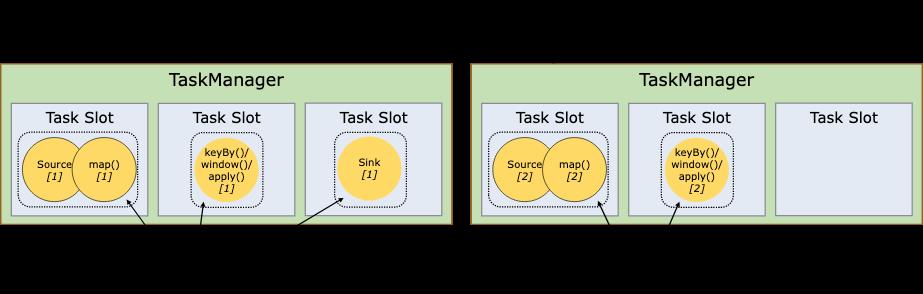
每个task slot是TaskManager的一部分,若一个taskManager有三个taskSlot,则这三个taskSlot会均分这个TaskManager的资源(仅内存,不包括CPU)。有多个slot意味着同一个JVM中会有多个子任务,这些任务会共享JVM的TCP连接和心跳信息。这里要说明的是,slot的个数不是subtask的个数是一一对应,一个slot中可以有多个subtask。在默认情况下,同一个job中的子任务(subtask)是可以共享一个slot的。
slot 是TM的资源子集。一个slot并不代表一个线程,它里面并不一定只放一个task。
多个task在一个slot就涉及 slot sharing group。
一个jobGraph的任务需要多少slot,取决于最大的并发度,这样的话,并发1和并发2就不会放到一个slot中。
Co-Location Group是在此基础上,数据的forward形式,即一个slot中,如果它处理的是key1的数据,那么接下来的task也是处理key1的数据,此时就达到Co-Location Group。
尽管有slot sharing group,但一个group里串联起来的task各自所需资源的大小并不好确定。阿里日常用得最多的还是一个task一个slot的方式。
Task Slots and Resources
每个 worker(TaskManager)都是一个 JVM进程 ,可以在不同的线程中执行一个或多个子任务。
为了控制一个 worker 接受多少任务,一个 worker 有所谓的任务槽 Task Slot(至少一个)。 每个任务槽 Task Slot 代表 TaskManager 资源的一个固定子集。
例如,具有三个插槽的 TaskManager 会将其托管内存的 1/3 专用于每个插槽。分配资源意味着子任务不会与来自其他作业的子任务竞争托管内存,而是拥有一定数量的保留托管内存。
请注意,这里没有发生 CPU 隔离;当前插槽仅分隔任务的托管内存。 通过调整任务槽的数量,用户可以定义子任务如何相互隔离。每个 TaskManager 有一个插槽意味着每个任务组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。
拥有多个插槽 Task Slot , 意味着更多的子任务共享同一个 JVM。
同一 JVM 中的任务共享 TCP 连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每个任务的开销。
Each worker (TaskManager) is a JVM process, and may execute one or more subtasks in separate threads. To control how many tasks a worker accepts, a worker has so called task slots (at least one).
Each task slot represents a fixed subset of resources of the TaskManager. A TaskManager with three slots, for example, will dedicate 1/3 of its managed memory to each slot. Slotting the resources means that a subtask will not compete with subtasks from other jobs for managed memory, but instead has a certain amount of reserved managed memory. Note that no CPU isolation happens here; currently slots only separate the managed memory of tasks.
By adjusting the number of task slots, users can define how subtasks are isolated from each other. Having one slot per TaskManager means each task group runs in a separate JVM (which can be started in a separate container, for example). Having multiple slots means more subtasks share the same JVM. Tasks in the same JVM share TCP connections (via multiplexing) and heartbeat messages. They may also share data sets and data structures, thus reducing the per-task overhead.
By default, Flink allows subtasks to share slots even if they are subtasks of different tasks, so long as they are from the same job. The result is that one slot may hold an entire pipeline of the job. Allowing this slot sharing has two main benefits:
A Flink cluster needs exactly as many task slots as the highest parallelism used in the job. No need to calculate how many tasks (with varying parallelism) a program contains in total.
It is easier to get better resource utilization. Without slot sharing, the non-intensive source/map() subtasks would block as many resources as the resource intensive window subtasks. With slot sharing, increasing the base parallelism in our example from two to six yields full utilization of the slotted resources, while making sure that the heavy subtasks are fairly distributed among the TaskManagers.
The APIs also include a resource group mechanism which can be used to prevent undesirable slot sharing.
As a rule-of-thumb, a good default number of task slots would be the number of CPU cores. With hyper-threading, each slot then takes 2 or more hardware thread contexts.
slot和parallelism
1.slot是指taskmanager的并发执行能力
在hadoop 1.x 版本中也有slot的概念,有兴趣的读者可以了解一下
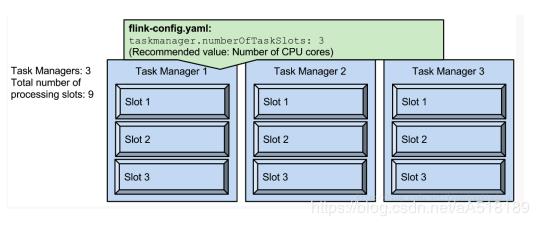
taskmanager.numberOfTaskSlots:3
每一个taskmanager中的分配3个TaskSlot,3个taskmanager一共有9个TaskSlot
2.parallelism是指taskmanager实际使用的并发能力
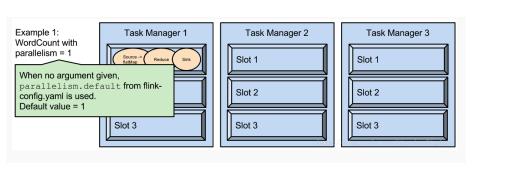
parallelism.default:1
运行程序默认的并行度为1,9个TaskSlot只用了1个,有8个空闲。设置合适的并行度才能提高效率。
3.parallelism是可配置、可指定的
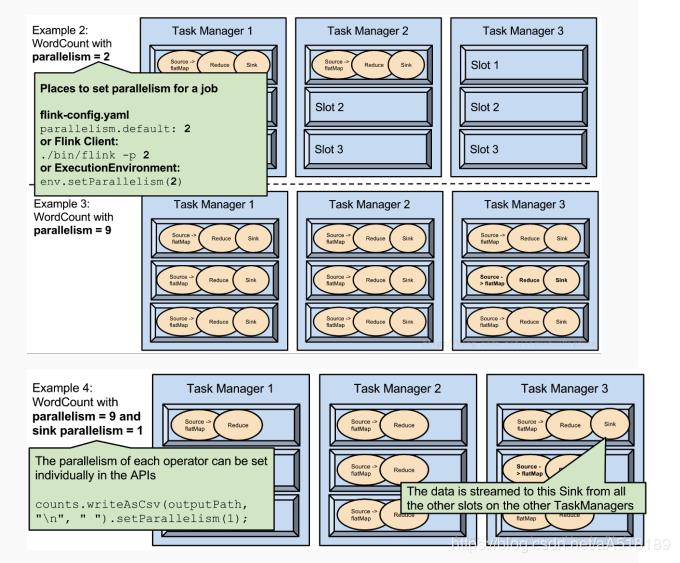
1.可以通过修改$FLINK_HOME/conf/flink-conf.yaml文件的方式更改并行度
2.可以通过设置$FLINK_HOME/bin/flink 的-p参数修改并行度
3.可以通过设置executionEnvironmentk的方法修改并行度
4.可以通过设置flink的编程API修改过并行度
5.这些并行度设置优先级从低到高排序,排序为api>env>p>file.
6.设置合适的并行度,能提高运算效率
7.parallelism不能多与slot个数。
slot和parallelism总结
1.slot是静态的概念,是指taskmanager具有的并发执行能力
2.parallelism是动态的概念,是指程序运行时实际使用的并发能力
3.设置合适的parallelism能提高运算效率,太多了和太少了都不行
4.设置parallelism有多中方式,优先级为api>env>p>file
7. Tasks and Operator Chains (算子链)
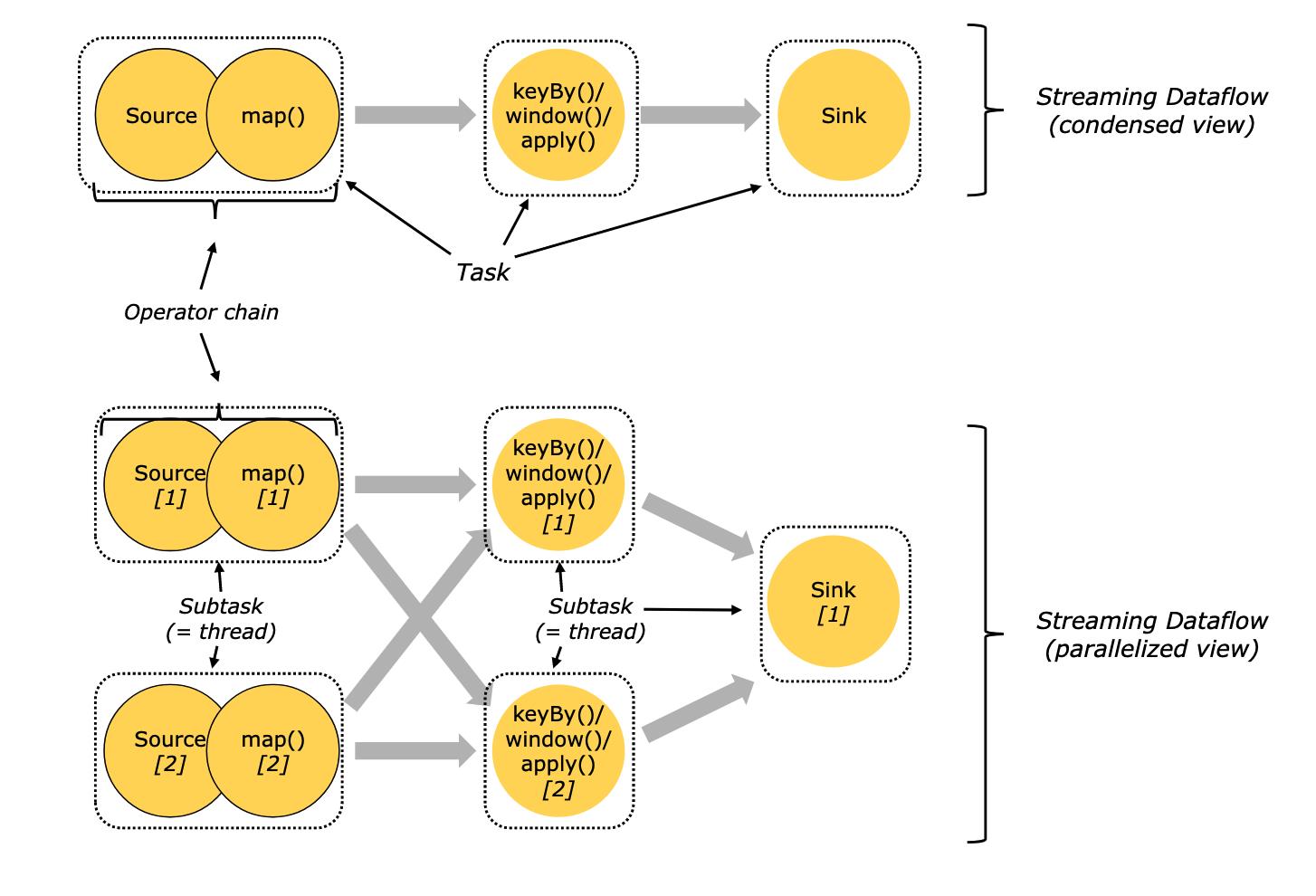
Flink会在生成JobGraph阶段,将代码中可以优化的算子优化成一个算子链(Operator Chains)以放到一个task(一个线程)中执行,以减少线程之间的切换和缓冲的开销,提高整体的吞吐量和延迟。
算子之间是否可以组成一个Operator Chains,看是否满足以下条件:
- 上下游算子的并行度一致
- 下游节点的入度为1
- 上下游节点都在同一个 slot group 中
- 下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter 等默认是ALWAYS)
- 上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
- 两个节点间数据分区方式是 forward
- 用户没有禁用 chain(代码中是否配置disableChain())
算子被定义后,先根据条件优化算子链 ,然后组成一个个subtask,最后根据是否可以共享slot分布在taskManager的slot中执行。
Flink 体系结构
Flink的基础架构图:
两种运行模式:
1.Session模式:预先启动好AM和TM,每提交一个job就启动一个Job Manager并向Flink的RM申请资源,不够的话,Flink的RM向YARN的RM申请资源。适合规模小,运行时间短的作业。./bin/flink run ./path/to/job.jar
2.Job模式:每一个job都重新启动一个Flink集群,完成后结束Flink,且只有一个Job Manager。资源按需申请,适合大作业。./bin/flink run -m yarn-cluster ./path/to/job.jar
下面是简单例子,详细看官网。
# 启动yarn-session,4个TM,每个有4GB堆内存,4个slot
cd flink-1.7.0/
./bin/yarn-session.sh -n 4 -jm 1024m -tm 4096m -s 4
# 启动作业
./bin/flink run -m yarn-cluster -yn 4 -yjm 1024m -ytm 4096m ./examples/batch/WordCount.jar细节取决于具体环境,如不同的RM
Application Deployment
Framework模式:Flink作业为JAR,并被提交到Dispatcher or JM or YARN。
Library模式:Flink作业为application-specific container image,如Docker image,适合微服务。
Task Execution
作业调度:在流计算中预先启动好节点,而在批计算中,每当某个阶段完成计算才启动下一个节点。
资源管理:slot作为基本单位,有大小和位置属性。JM有SlotPool,向Flink RM申请Slot,FlinkRM发现自己的SlotManager中没有足够的Slot,就会向集群RM申请。后者返回可用TM的ip,让FlinkRM去启动,TM启动后向FlinkRM注册。后者向TM请求Slot,TM向JM提供相应Slot。JM用完后释放Slot,TM会把释放的Slot报告给FlinkRM。在Blink版本中,job模式会根据申请slot的大小分配相应的TM,而session模式则预先设置好TM大小,每有slot申请就从TM中划分相应的资源。
任务可以是相同operator (data parallelism),不同 operator (task parallelism),甚至不同application (job parallelism)。TM提供一定数量的slots来控制并行的任务数。
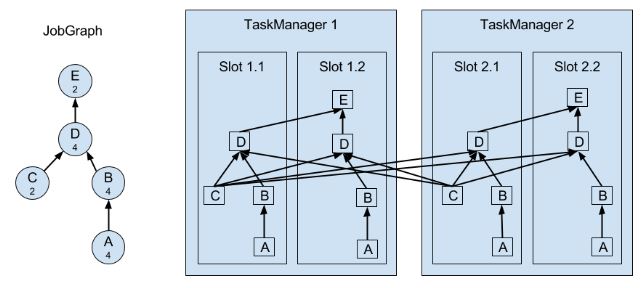
上图A和C是source function,E是sink function,小数字表示并行度。
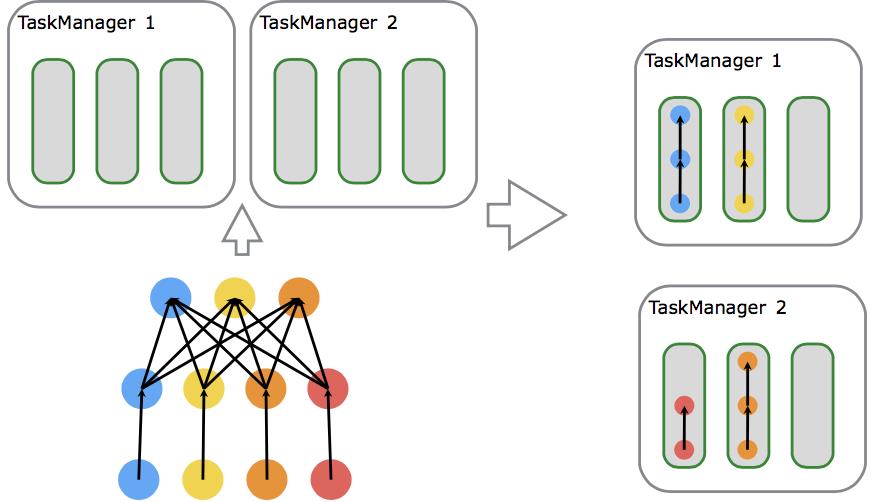
一个TM是一个JVM进程,它通过多线程完成任务。线程的隔离不太好,一个线程失败有可能导致整个TM失败。
Highly-Available Setup
从失败中恢复需要重启失败进程、作业和恢复它的state。
当一个TM挂掉而RM又无法找到空闲的资源时,就只能暂时降低并行度,直到有空闲的资源重启TM。
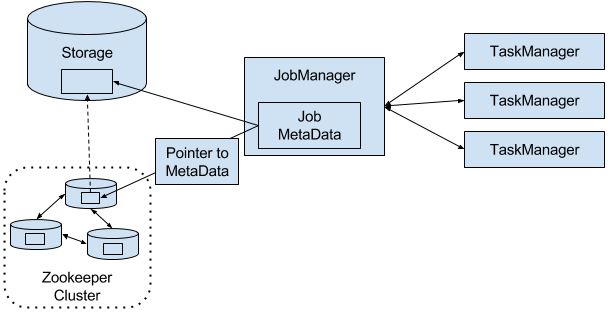
当JM挂掉就靠ZK来重新选举,和找到JM存储到远程storage的元数据、JobGraph。重启JM并从最后一个完成的checkpoint开始。
JM在执行期间会得到每个task checkpoints的state存储路径(task将state写到远程storage)并写到远程storage,同时在ZK的存储路径留下pointer指明到哪里找上面的存储路径。
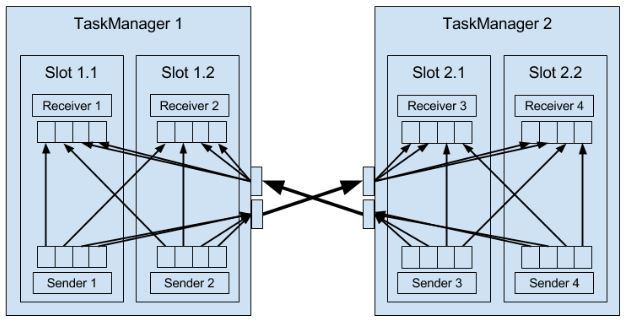
背压
数据涌入的速度大于处理速度。在source operator中,可通过Kafka解决。在任务间的operator有如下机制应对:
Local exchange:task1和2在同一个工作节点,那么buffer pool可以直接交给下一个任务,但下一个任务task2消费buffer pool中的信息速度减慢时,当前任务task1填充buffer pool的速度也会减慢。
Remote exchange:TM保证每个task至少有一个incoming和一个outgoing缓冲区。当下游receiver的处理速度低于上有的sender的发送速度,receiver的incoming缓冲区就会开始积累数据(需要空闲的buffer来放从TCP连接中接收的数据),当挤满后就不再接收数据。上游sender利用netty水位机制,当网络中的缓冲数据过多时暂停发送。
Data Transfer in Flink
TM负责数据在tasks间的转移,转移之前会存储到buffer(这又变回micro-batches)。每个TM有32KB的网络buffer用于接收和发送数据。如果sender和receiver在不同进程,那么会通过操作系统的网络栈来通信。每对TM保持permanent TCP连接来交换数据。每个sender任务能够给所有receiving任务发送数据,反之,所有receiver任务能够接收所有sender任务的数据。TM保证每个任务都至少有一个incoming和outgoing的buffer,并增加额外的缓冲区分配约束来避免死锁。
如果sender和receiver任务在同一个TM进程,sender会序列化结果数据到buffer,如果满了就放到队列。receiver任务通过队列得到数据并进行反序列化。这样的好处是解耦任务并允许在任务中使用可变对象,从而减少了对象实例化和垃圾收集。一旦数据被序列化,就能安全地修改。而缺点是计算消耗大,在一些条件下能够把task穿起来,避免序列化。(C10)
Flow Control with Back Pressure
receiver放到缓冲区的数据变为队列,sender将要发送的数据变为队列,最后sender减慢发送速度。
Event Time Processing
event time处理的数据必须有时间戳(Long unix timestamp)并定义了watermarks。watermark是一种特殊的records holding a timestamp long value。它必须是递增的(防止倒退),有一个timestamp t(下图的5),暗示所有接下来的数据都会大于这个值。后来的,小于这个值,就被视为迟来数据,Flink有其他机制处理。
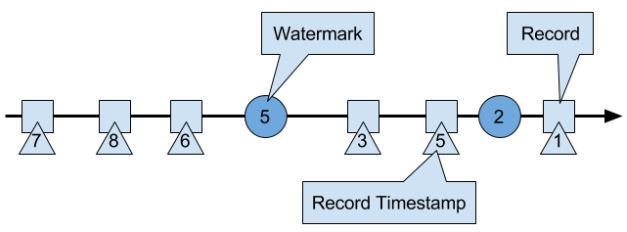
Watermarks and Event Time
WM在Flink是一种特殊的record,它会被operator tasks接收和释放。
tasks有时间服务来维持timers(timers注册到时间服务上),在time-window task中,timers分别记录了各个window的结束时间。当任务获得一个watermark时,task会根据这个watermark的timestamp更新内部的event-time clock。任务内部的时间服务确定所有timers时间是否小于watermark的timestamp,如果大于则触发call-back算子来释放记录并返回结果。最后task还会将更新的event-time clock的WM进行广播。(结合下图理解)
只有ProcessFunction可以读取和修改timestamp或者watermark(The ProcessFunction can read the timestamp of a currently processed record, request the current event-time of the operator, and register timers)。下面是PF的行为。
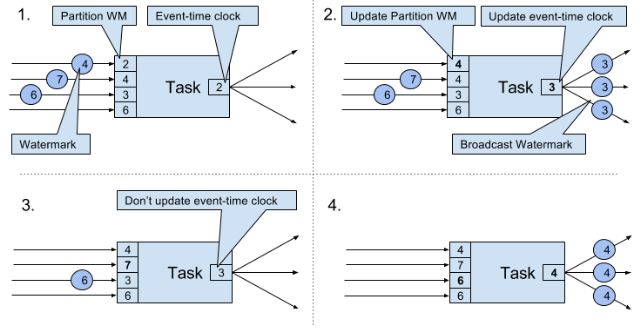
当收到WM大于所有目前拥有的WM,就会把event-time clock更新为所有WM中最小的那个,并广播这个最小的WM。即便是多个streams输入,机制也一样,只是增加Paritition WM数量。这种机制要求获得的WM必须是累加的,而且task必须有新的WM接收,否则clock就不会更新,task的timers就不会被触发。另外,当多个streams输入时,timers会被WM比较离散的stream主导,从而使更密集的stream的state不断积累。
Timestamp Assignment and Watermark Generation
当streaming application消化流时产生。Flink有三种方式产生:
- SourceFunction:产生的record带有timestamp,一些特殊时点产生WM。如果SF暂时不再发送WM,则会被认为是idle。Flink会从接下来的watermark operators中排除由这个SF生产的分区(上图有4个分区),从而解决timer不触发的问题。
-
AssignerWithPeriodicWatermarks提取每条记录的timestamp,并周期性的查询当前WM,即上图的Partition WM。 -
AssignerWithPunctuatedWatermarks可以从每条数据提取WM。
上面两个User-defined timestamp assignment functions通常用在source operator附近,因为stream一经处理就很难把握record的时间顺序了。所以UDF可以修改timestamp和WM,但在数据处理时使用不是一个好主意。
State Management
由任务维护并用于计算函数结果的所有数据都属于任务的state。其实state可以理解为task业务逻辑的本地或实例变量。
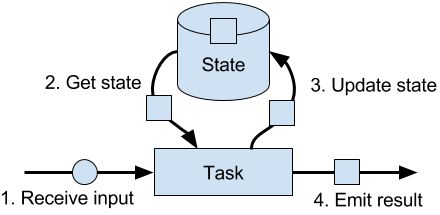
在Flink,state总是和特定的operator关联。operator需要注册它的state,而state有两种类型:
- Operator State:由同一并行任务处理的所有记录都可以访问相同的state,而其他的task或operator不能访问,即一个task专属一个state。这种state有三种primitives
- List State represents state as a list of entries.
- Union List State同上,但在任务失败和作业从savepoint重启的行为不一样
- Broadcast State(v1.5) 同样一个task专属一个state,但state都是一样的(需要自己注意保持一致,对state更新时,实际上只对当前task的state进行更新。只有所有task的更新一样时,即输入数据一样(一开始广播所以一样,但数据的顺序可能不一样),对数据的处理一样,才能保证state一样)。这种state只能存储在内存,所以没有RockDB backend。
- Keyed State:相同key的record共享一个state。
- Value State:每个key一个值,这个值可以是复杂的数据结构.
- List State:每个key一个list
- Map State:每个key一个map
上面两种state的存在方式有两种:raw和managed,一般都是用后者,也推荐用后者(更好的内存管理、不需造轮子)。
State Backends
state backend决定了state如何被存储、访问和维持。它的主要职责是本地state管理和checkpoint state到远程。在管理方面,可选择将state存储到内存还是磁盘。checkpoint方面在C8详细介绍。
MemoryStateBackend, FsStateBackend, RocksDBStateBackend适合越来越大的state。都支持异步checkpoint,其中RocksDB还支持incremental的checkpoint。
- 注意:As RocksDB’s JNI bridge API is based on byte[], the maximum supported size per key and per value is 2^31 bytes each. IMPORTANT: states that use merge operations in RocksDB (e.g. ListState) can silently accumulate value sizes > 2^31 bytes and will then fail on their next retrieval. This is currently a limitation of RocksDB JNI.
Scaling Stateful Operators
Flink会根据input rate调整并发度。对于stateful operators有以下4种方式:
keyed state:根据key group来调整,即分为同一组的key-value会被分到相同的task
list state:所有list entries会被收集并重新均匀分布,当增加并发度时,要新建list
union list state:增加并发时,广播整个list,所以rescaling后,所有task都有所有的list state。
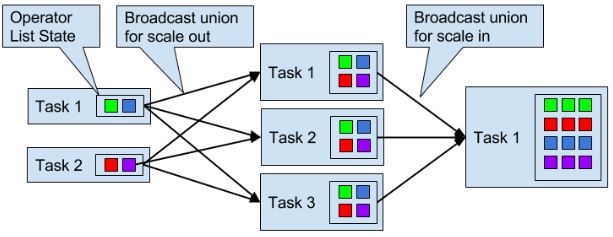
- broadcast state
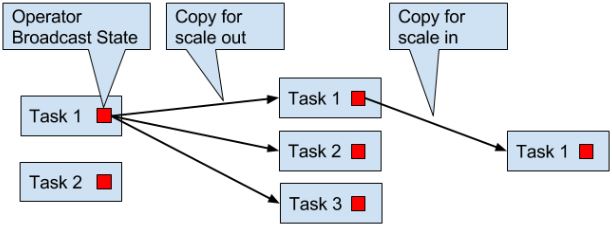
Checkpoints, Savepoints, and State Recovery
Flink’s Lightweight Checkpointing Algorithm
在分布式开照算法Chandy-Lamport的基础上实现。有一种特殊的record叫checkpoint barrier(由JM产生),它带有checkpoint ID来把流进行划分。在CB前面的records会被包含到checkpoint,之后的会被包含在之后的checkpoint。
当source task收到这种信息,就会停止发送recordes,触发state backend对本地state的checkpoint,并广播checkpoint ID到所有下游task。当checkpoint完成时,state backend唤醒source task,后者向JM确定相应的checkpoint ID已经完成任务。
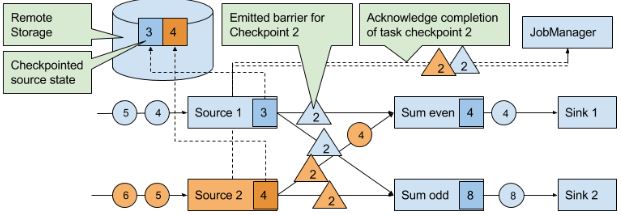
当下游获得其中一个CB时,就会暂停处理这个CB对应的source的数据(完成checkpoint后发送的数据),并将这些数据存到缓冲区,直到其他相同ID的CB都到齐,就会把state(下图的12、8)进行checkpoint,并广播CB到下游。直到所有CB被广播到下游,才开始处理排队在缓冲区的数据。当然,其他没有发送CB的source的数据会继续处理。
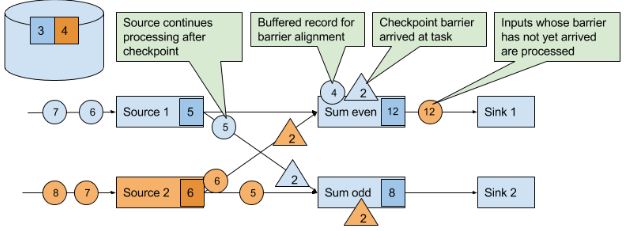
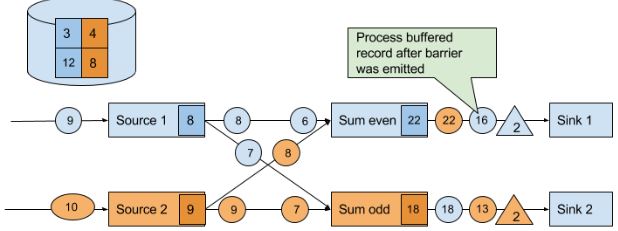
最后,当所有sink会向JM发送BC确定checkpoint已完成。
这种机制还有两个优化:
- 当operator的state很大时,复制整个state并发送到远程storage会很费时。而RocksDB state backend支持asynchronous and incremental的checkpoints。当触发checkpoint时,backend会快照所有本地state的修改(直至上一次checkpoint),然后马上让task继续执行。后台线程异步发送快照到远程storage。
- 在等待其余CB时,已经完成checkpoint的source数据需要排队。但如果使用at-least-once就不需要等了。但当所有CB到齐再checkpoint,存储的state就已经包含了下一次checkpoint才记录的数据。(如果是取最值这种state就无所谓)
Recovery from Consistent Checkpoints
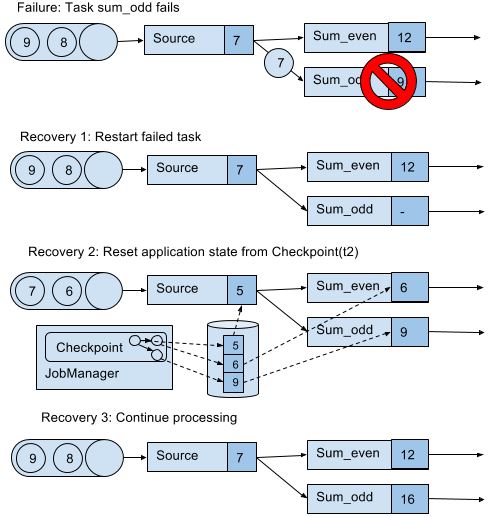
上图队列中的7和6之所以能恢复,取决于数据源是否resettable,如Kafka,不会因为发送信息就把信息删除。这才能实现处理过程的exactly-once state consistency(严格来讲,数据还是被重复处理,但是在读档后重复的)。但是下游系统有可能接收到多个结果。这方面,Flink提供sink算子实现output的exactly-once,例如给checkpoint提交records释放记录。另一个方法是idempotent updates,详细看C7。
Savepoints
checkpoints加上一些额外的元数据,功能也是在checkpoint的基础上丰富。不同于checkpoints,savepoint不会被Flink自动创造(由用户或者外部scheduler触发创造)和销毁。savepoint可以重启不同但兼容的作业,从而:
- 修复bugs进而修复错误的结果,也可用于A/B test或者what-if场景。
- 调整并发度
- 迁移作业到其他集群、新版Flink
也可以用于暂停作业,通过savepoint查看作业情况。
参考Stream Processing with Apache Flink by Vasiliki Kalavri; Fabian Hueske
Flink 应用场景
应用场景
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
接下来我们将介绍 Flink 常见的几类应用并给出相关实例链接。
事件驱动型应用
什么是事件驱动型应用?
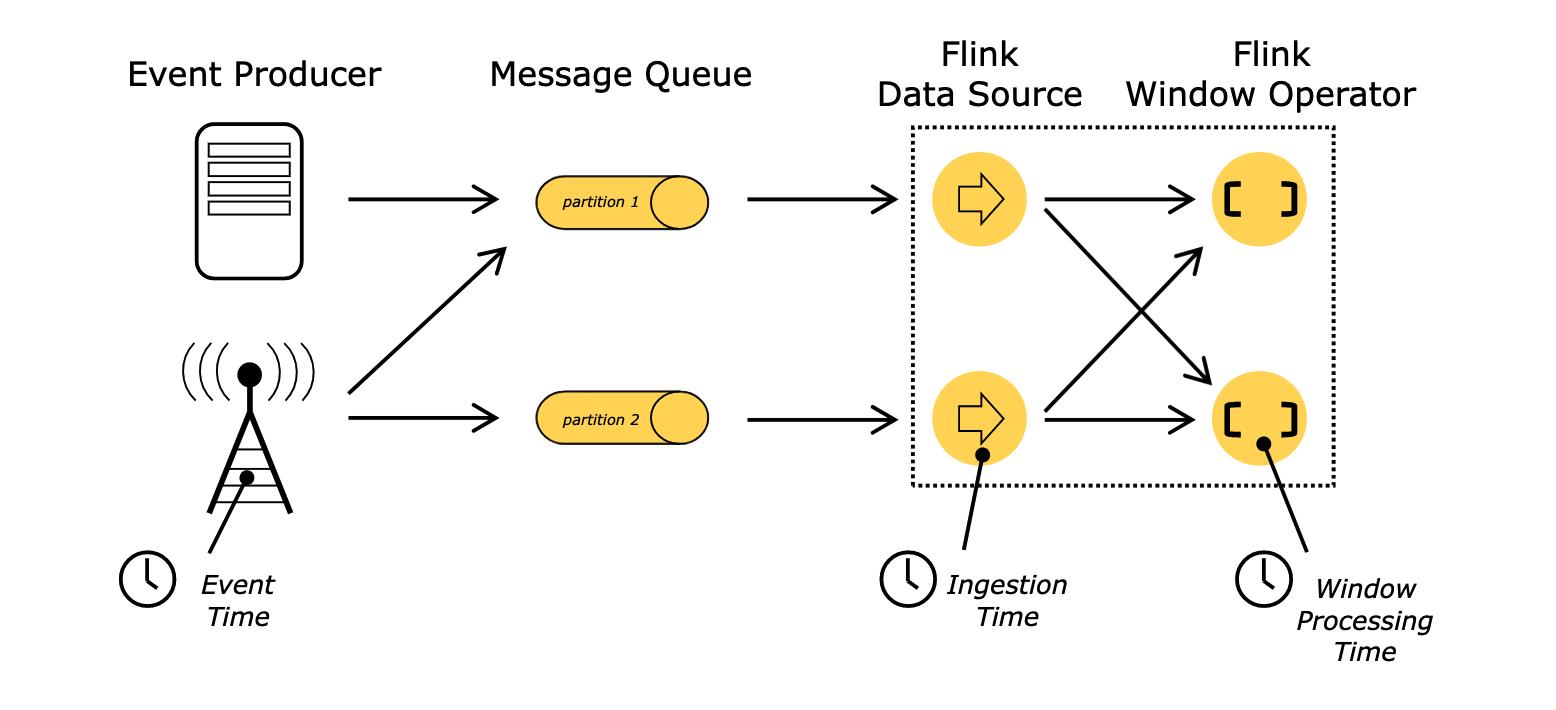
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
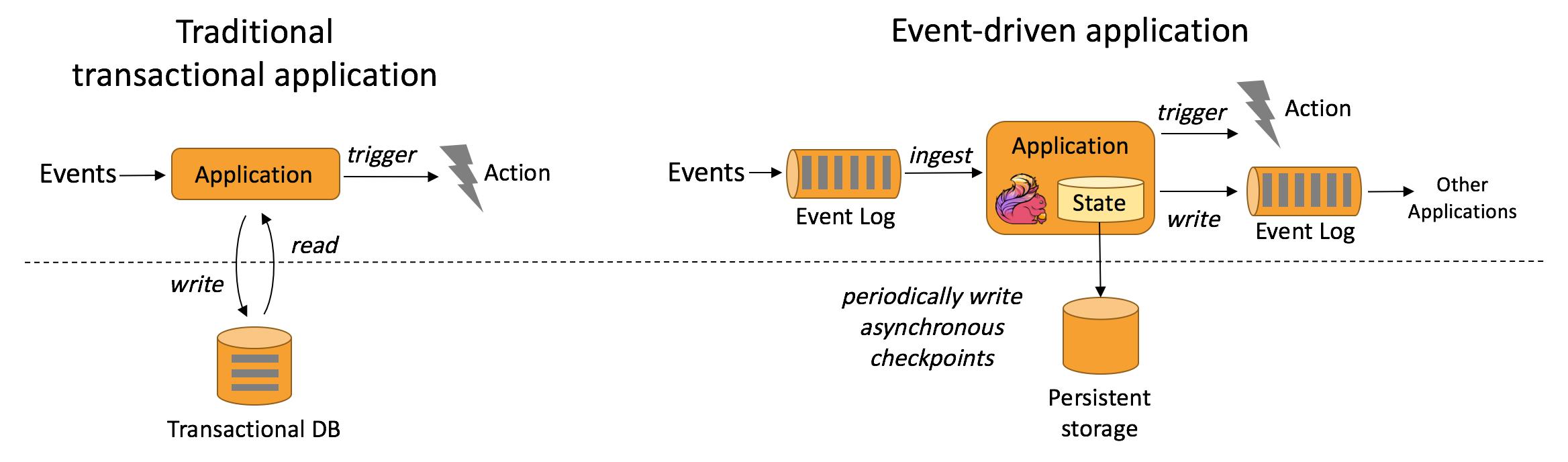
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。在传统架构中,应用需要读写远程事务型数据库。
相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。
事件驱动型应用的优势?
事件驱动型应用无须查询远程数据库,本地数据访问使得它具有更高的吞吐和更低的延迟。而由于定期向远程持久化存储的 checkpoint 工作可以异步、增量式完成,因此对于正常事件处理的影响甚微。事件驱动型应用的优势不仅限于本地数据访问。传统分层架构下,通常多个应用会共享同一个数据库,因而任何对数据库自身的更改(例如:由应用更新或服务扩容导致数据布局发生改变)都需要谨慎协调。反观事件驱动型应用,由于只需考虑自身数据,因此在更改数据表示或服务扩容时所需的协调工作将大大减少。
Flink 如何支持事件驱动型应用?
事件驱动型应用会受制于底层流处理系统对时间和状态的把控能力,Flink 诸多优秀特质都是围绕这些方面来设计的。它提供了一系列丰富的状态操作原语,允许以精确一次的一致性语义合并海量规模(TB 级别)的状态数据。此外,Flink 还支持事件时间和自由度极高的定制化窗口逻辑,而且它内置的 ProcessFunction 支持细粒度时间控制,方便实现一些高级业务逻辑。同时,Flink 还拥有一个复杂事件处理(CEP)类库,可以用来检测数据流中的模式。
Flink 中针对事件驱动应用的明星特性当属 savepoint。Savepoint 是一个一致性的状态映像,它可以用来初始化任意状态兼容的应用。在完成一次 savepoint 后,即可放心对应用升级或扩容,还可以启动多个版本的应用来完成 A/B 测试。
Programs written in the Data Stream API can resume execution from a savepoint以上是关于Flink 极简教程: 架构及原理 Apache Flink® — Stateful Computations over Data Streams的主要内容,如果未能解决你的问题,请参考以下文章