原来Kylin的增量构建,大有学问(理解CubeCuboid与Segment的关系)
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了原来Kylin的增量构建,大有学问(理解CubeCuboid与Segment的关系)相关的知识,希望对你有一定的参考价值。
转载自:原来Kylin的增量构建,大有学问!(理解Cube、Cuboid与Segment的关系)
作者:大数据梦想家
本篇博客,博主为大家介绍的是关于Kylin的增量构建的步骤过程,以及其与全量构建的差异对比!看完之后,相信你也一定能够感受到这里面的大学问~
文章目录
Kylin增量构建
应用场景
Kylin在每次Cube的构建都会从Hive中批量读取数据,而对于大多数业务场景来说,Hive中的数据处于不断增长的状态。为了支持Cube中的数据能够不断地得到更新,且无需重复地为已经处理过的历史数据构建Cube,因此对于 Cube引入了增量构建的功能。
理解Cube、Cuboid与Segment的关系
Kylin将Cube划分为多个Segment(对应就是HBase中的一个表),每个Segment用起始时间和结束时间来标志。Segment代表一段时间内源数据的预计算结果。一个Segment的起始时间等于它之前那个Segment的结束时间,同理,它的结束时间等于它后面那个Segment的起始时间。同一个Cube下不同的Segment除了背后的源数据不同之外,其他如结构定义、构建过程、优化方法、存储方式等都完全相同。
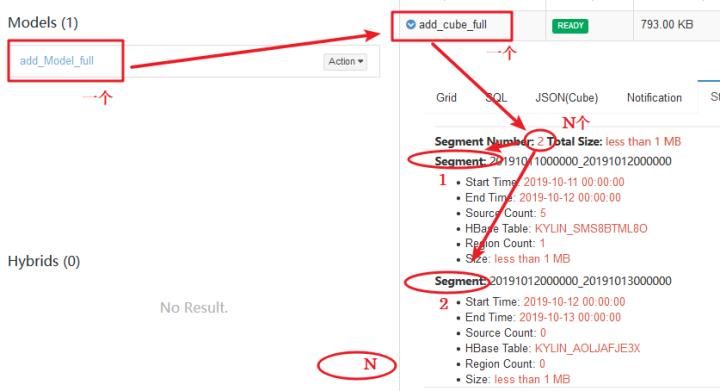
一个Cube,可以包含多个Cuboid,而Segment是指定时间范围的Cube,可以理解为Cube的分区。对应就是HBase中的一张表,该表中包含了所有的Cuboid。
例如:以下为针对某个Cube的Segment
| Segment名称 | 分区时间 | HBase表名 |
|---|---|---|
| 201910110000000-201910120000000 | 20191011 | KYLIN_41Z8123 |
| 201910120000000-201910130000000 | 20191012 | KYLIN_5AB2141 |
| 201910130000000-201910140000000 | 20191013 | KYLIN_7C1151 |
| 201910140000000-201910150000000 | 20191014 | KYLIN_811680 |
| 201910150000000-201910160000000 | 20191015 | KYLIN_A11AD1 |
全量构建与增量构建
全量构建
在全量构建中,Cube中只存在唯一的一个Segment,该Segment没有分割时间的概念,也就没有起始时间和结束时间。全量构建和增量构建各有其适用的场景,用户可以根据自己的业务场景灵活地进行切换。对于全量构建来说,每当需要更新Cube数据的时候,它不会区分历史数据和新加入的数据,也就是说,在构建的时候会导入并处理所有的原始数据。

增量构建
增量构建只会导入新Segment指定的时间区间内的原始数据,并只对这部分原始数据进行预计算。
全量构建和增量构建的对比
| 全量构建 | 增量构建 |
|---|---|
| 每次更新时都需要更新整个数据集 | 每次只对需要更新的时间范围进行更新,因此离线计算量相对较小 |
| 查询时不需要合并不同Segment的结果 | 查询时需要合并不同Segment的结果,因此查询性能会受影响 |
| 不需要后续的Segment合并 | 累计一定量的Segment之后,需要进行合并 |
| 适合小数据量或全表更新的Cube | 适合大数据量的Cube |
全量构建与增量构建的Cube查询方式对比:
- 全量构建Cube
■ 查询引擎只需向存储引擎访问单个Segment所对应的数据,无需进行Segment之间的聚合
■ 为了加强性能,单个Segment的数据也有可能被分片存储到引擎的多个分区上,查询引擎可能仍然需要对单个Segment不同分区的数据做进一步的聚合
- 增量构建Cube
■ 由于不同时间的数据分布在不同的Segment之中,查询引擎需要向存储引擎请求读取各个Segment的数据
■ 增量构建的Cube上的查询会比全量构建的做更多的运行时聚合,通常来说增量构建的Cube上的查询会比全量构建的Cube上的查询要慢一些。
对于小数据量的Cube,或者经常需要全表更新Cube,使用全量构建需要更少的运维精力,以少量的重复计算降低生产环境中的维护复杂度。而对于大数据量的Cube,例如,对于一个包含两年历史数据的Cube,如果需要每天更新,那么每天为了新数据而去重复计算过去两年的数据就会变得非常浪费,在这种情况下需要考虑使用增量构建。

增量构建Cube过程
1、指定分割时间列
增量构建Cube的定义必须包含一个时间维度,用来分割不同的Segment,这样的维度称为分割时间列(Partition Date Column)。
2、增量构建过程
- 在进行增量构建时,将增量部分的起始时间和结束时间作为增量构建请求的一部分提交给Kylin的任务引擎
- 任务引擎会根据起始时间和结束时间从Hive中抽取相应时间的数据,并对这部分数据做预计算处理
- 将预计算的结果封装成为一个新的Segment,并将相应的信息保存到元数据和存储引擎中。一般来说,增量部分的起始时间等于Cube中最后一个Segment的结束时间。
增量Cube的创建
创建增量Cube的过程和创建普通Cube的过程基本类似,只是增量Cube会有一些额外的配置要求
1、配置Model
增量构建的Cube需要指定分割时间列。例如:将日期分区字段添加到维度列中
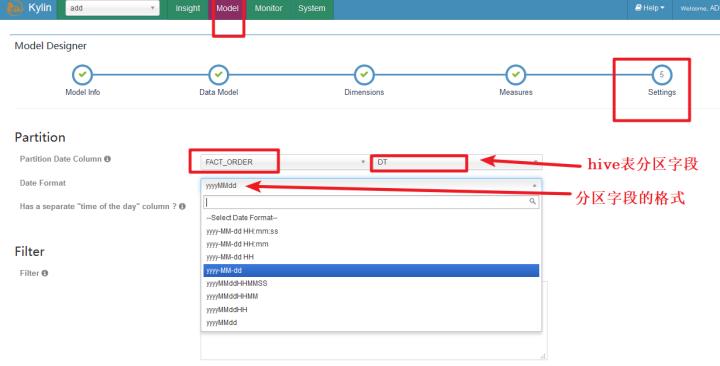
2、 设置日期范围
创建cube结束后,在build时设置计算数据的日期

注意事项
注意构建Cube时,选择的分区时间为,起始时间(包含)、结束时间(不保存),对应了从Hive从获取数据源的条件
3、查看Segment
第一天同步成功

接着我们想再计算下一个日期的数据

第二天同步成功
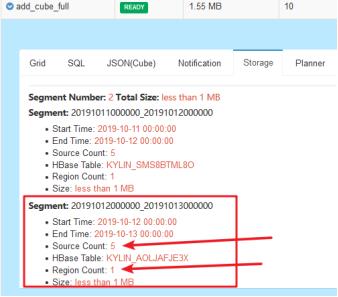
根据层量同步方案,得出一个结论
每天生成一个Segment,一年就有365个Segment。当用户查询时,系统不知道数据在哪个Segment中,所以需要扫描所有的Segment(扫描356个表),扫描多个表/多个Segment会降低数据查询效率。【增量方案带来的问题】
补充:文件越多效率越慢。
1个文件10G和10000个文件共10G 读取一个文件更快(寻址开销、频繁发开关闭)
一个文件夹内的文件特别多,这个文件夹打开的时间就会特别长。
当系统越来越慢,越来越慢,越来越慢,越来越慢,有可能是某一个目录中的数据没有及时的清空或删除。
[关于Cube碎片管理,你需要知道这些!](https://alice.blog.csdn.net/article/details/106165065)
总结
本篇博客为大家介绍了Kylin的增量构建与全量构建的差异与适用场景分析,并为演示了如何进行kylin的增量构建。
以上是关于原来Kylin的增量构建,大有学问(理解CubeCuboid与Segment的关系)的主要内容,如果未能解决你的问题,请参考以下文章