可视化特征的重要性
Posted _WILLPOWER_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可视化特征的重要性相关的知识,希望对你有一定的参考价值。
#feature_importances是模型训练后特征重要性函数的返回值
#title是该图片的标题
#feature_names是模型重要性的名字函数的返回值
def plot_feature_importances(feature_importances,title,feature_names):
# 将重要性值标准化
feature_importances = 100.0*(feature_importances/max(feature_importances))
# index_sorted = np.flipud(np.argsort(feature_importances)) #上短下长
#index_sorted装的是从小到大,排列的下标
index_sorted = np.argsort(feature_importances)# 上长下短
# 让X坐标轴上的标签居中显示
bar_width = 1
# 相当于y坐标
pos = np.arange(len(feature_importances))+bar_width/2
plt.figure(figsize=(16,4))
# plt.barh(y,x)
plt.barh(pos,feature_importances[index_sorted],align='center')
# 在柱状图上面显示具体数值,ha参数控制参数水平对齐方式,va控制垂直对齐方式
for y, x in enumerate(feature_importances[index_sorted]):
plt.text(x+2, y, '%.4s' %x, ha='center', va='bottom')
plt.yticks(pos,feature_names[index_sorted])
plt.title(title)
plt.show()
调用如下:
plot_feature_importances(fitModel.feature_importances_,name,fitModel.feature_names_in_)
其中的fitModel是训练后的模型,name的值是字符串可以自己加
一些函数讲解
np.argsort
如下
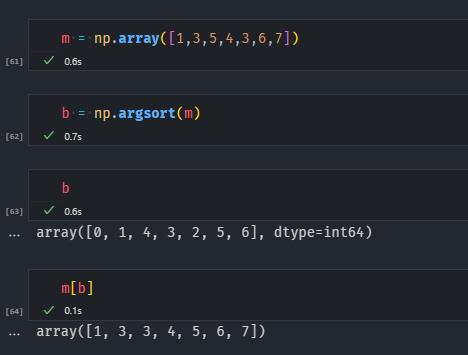 .
.
enumerate
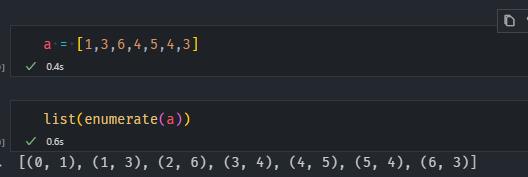
图片
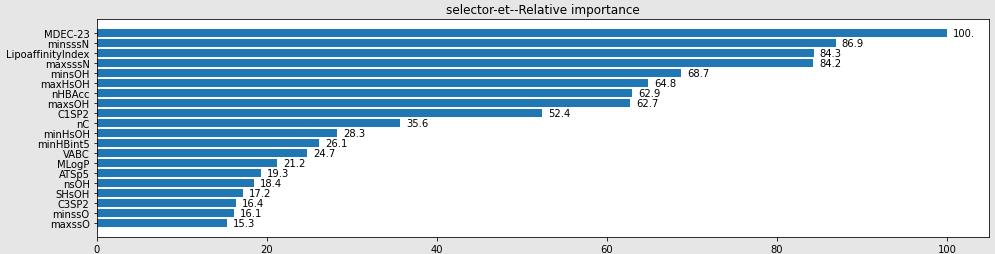
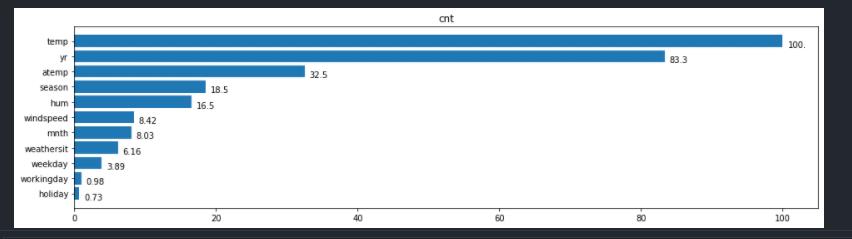
以上是关于可视化特征的重要性的主要内容,如果未能解决你的问题,请参考以下文章