gpt-2 中文注释 对gpt-2代码进行了梳理
Posted _刘文凯_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了gpt-2 中文注释 对gpt-2代码进行了梳理相关的知识,希望对你有一定的参考价值。
查了一下 关于原生GPT-2的资料比较少,而且源代码注释比较少,我就自己读了一遍代码并且用中文注释起来了。在这里记录一下。
GPT-2简介:
GPT-2是openAI开发的一个基于transform的开源深度学习架构,它只使用了transform的deconding部分。源代码:https://github.com/openai/gpt-2
GPT-2使用:
1、下载下来gpt-2之后,首先下载与训练模型,使用download_model.py, 在终端运行:
python3 download_model.py 124M
下载124M的模型,还有其它可选项,M就是大小MB
这个是下载下来的模型:
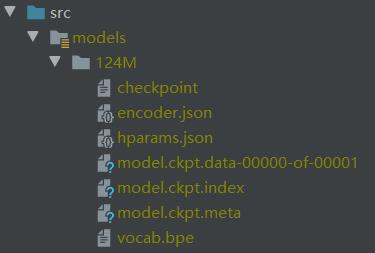
encoder.py 会使用一下文件:
encoder.json: 文字编码
vocab.bpe: BPE编码
超参数:
hparams.json
预训练模型:
checkpoint
model.ckpt.data-0000-of-00001
model.ckpt.index # 存放权重
model.ckpt.meta # 存放图结构
2、在/gpt-2/src/中找到interactive_conditional_samples.py,直接运行,即可使用。
GPT-2代码注释:
以interactive_conditional_samples.py为例:
interactive_conditional_samples.py
#!/usr/bin/env python3
import fire
import json
import os
import numpy as np
import tensorflow as tf
import model, sample, encoder
def interact_model(
model_name='124M',
seed=None,
nsamples=2,
batch_size=2,
length=None,
temperature=1, # 随机度 越大越随机
top_k=0, # 取第几个概率值
top_p=1, #
models_dir='models',
):
"""
Interactively run the model
:model_name=124M : String, which model to use
:seed=None : Integer seed for random number generators, fix seed to reproduce
results
:nsamples=1 : Number of samples to return total
:batch_size=1 : Number of batches (only affects speed/memory). Must divide nsamples.
:length=None : Number of tokens in generated text, if None (default), is
determined by model hyperparameters
:temperature=1 : Float value controlling randomness in boltzmann
distribution. Lower temperature results in less random completions. As the
temperature approaches zero, the model will become deterministic and
repetitive. Higher temperature results in more random completions.
:top_k=0 : Integer value controlling diversity. 1 means only 1 word is
considered for each step (token), resulting in deterministic completions,
while 40 means 40 words are considered at each step. 0 (default) is a
special setting meaning no restrictions. 40 generally is a good value.
:models_dir : path to parent folder containing model subfolders
(i.e. contains the <model_name> folder)
"""
models_dir = os.path.expanduser(os.path.expandvars(models_dir))
if batch_size is None:
batch_size = 1
assert nsamples % batch_size == 0
enc = encoder.get_encoder(model_name, models_dir) # (encode, BPE)
hparams = model.default_hparams()
with open(os.path.join(models_dir, model_name, 'hparams.json')) as f:
hparams.override_from_dict(json.load(f)) # Hparams可以用于超参数调优
if length is None: # length 标记的数量
length = hparams.n_ctx // 2
elif length > hparams.n_ctx:
raise ValueError("Can't get samples longer than window size: %s" % hparams.n_ctx)
with tf.Session(graph=tf.Graph()) as sess:
context = tf.placeholder(tf.int32, [batch_size, None])
np.random.seed(seed)
tf.set_random_seed(seed)
output = sample.sample_sequence(
hparams=hparams, length=length,
context=context,
batch_size=batch_size,
temperature=temperature, top_k=top_k, top_p=top_p
)
saver = tf.train.Saver() # 保存和读取模型的
ckpt = tf.train.latest_checkpoint(os.path.join(models_dir, model_name)) # 读取模型
saver.restore(sess, ckpt)
while True:
raw_text = input("Model prompt >>> ")
while not raw_text:
print('Prompt should not be empty!')
raw_text = input("Model prompt >>> ")
context_tokens = enc.encode(raw_text) # 文本编码
generated = 0
for _ in range(nsamples // batch_size):
out = sess.run(output, feed_dict=
context: [context_tokens for _ in range(batch_size)]
)[:, len(context_tokens):] # 通过run绑定原有模型和现在的图
for i in range(batch_size):
generated += 1
text = enc.decode(out[i])
print("=" * 40 + " SAMPLE " + str(generated) + " " + "=" * 40)
print(text)
print("=" * 80)
if __name__ == '__main__':
fire.Fire(interact_model)
sample.py
import tensorflow as tf
import model
def top_k_logits(logits, k): ## 计算top_k
if k == 0:
# no truncation
return logits
def _top_k():
values, _ = tf.nn.top_k(logits, k=k)
min_values = values[:, -1, tf.newaxis]
return tf.where(
logits < min_values,
tf.ones_like(logits, dtype=logits.dtype) * -1e10,
logits
)
return tf.cond(
tf.equal(k, 0),
lambda: logits,
lambda: _top_k(),
)
def top_p_logits(logits, p): ### 计算top_p, 等于1时相当于没计算
"""Nucleus sampling"""
batch, _ = logits.shape.as_list()
sorted_logits = tf.sort(logits, direction='DESCENDING', axis=-1)
cumulative_probs = tf.cumsum(tf.nn.softmax(sorted_logits, axis=-1), axis=-1)
indices = tf.stack([
tf.range(0, batch),
# number of indices to include
tf.maximum(tf.reduce_sum(tf.cast(cumulative_probs <= p, tf.int32), axis=-1) - 1, 0),
], axis=-1)
min_values = tf.gather_nd(sorted_logits, indices) # 按照indices的格式从sorted_logits中抽取切片
return tf.where( # 若condition=True,则返回对应X的值,False则返回对应的Y值。
logits < min_values,
tf.ones_like(logits) * -1e10,
logits,
)
def sample_sequence(*, hparams, length, start_token=None, batch_size=None, context=None, temperature=1, top_k=0, top_p=1):
if start_token is None:
assert context is not None, 'Specify exactly one of start_token and context!'
else:
assert context is None, 'Specify exactly one of start_token and context!'
context = tf.fill([batch_size, 1], start_token) # 填充
def step(hparams, tokens, past=None):
lm_output = model.model(hparams=hparams, X=tokens, past=past, reuse=tf.AUTO_REUSE) # tf.AUTO_REUSE共享变量作用域 节省内存空间
logits = lm_output['logits'][:, :, :hparams.n_vocab]
presents = lm_output['present']
presents.set_shape(model.past_shape(hparams=hparams, batch_size=batch_size))
return
'logits': logits,
'presents': presents,
with tf.name_scope('sample_sequence'):
def body(past, prev, output):
next_outputs = step(hparams, prev, past=past) # shape=(1, ?, 50257)
logits = next_outputs['logits'][:, -1, :] / tf.to_float(temperature) ## 只要最后一个输出的值(可能值的概率向量)
logits = top_k_logits(logits, k=top_k)
logits = top_p_logits(logits, p=top_p) ## [00,00,0.2,00,1,] 概率
samples = tf.multinomial(logits, num_samples=1, output_dtype=tf.int32) ### 这里限制了仅仅采样一个值
return [
next_outputs['presents'] if past is None else tf.concat([past, next_outputs['presents']], axis=-2), # present 是每一层的[k,v]
samples,
tf.concat([output, samples], axis=1)
]
past, prev, output = body(None, context, context)
def cond(*args):
return True
_, _, tokens = tf.while_loop( # 循环 loop_vars既是输出值也是下次循环的输入值
cond=cond, body=body,
maximum_iterations=length - 1,
loop_vars=[
past,
prev,
output
],
shape_invariants=[
tf.TensorShape(model.past_shape(hparams=hparams, batch_size=batch_size)),
tf.TensorShape([batch_size, None]),
tf.TensorShape([batch_size, None]),
],
back_prop=False,
)
return tokens
model.py
import numpy as np
import tensorflow as tf
from tensorflow.contrib.training import HParams
def default_hparams():
return HParams(
n_vocab=0,
n_ctx=1024,
n_embd=768,
n_head=12,
n_layer=12,
)
def shape_list(x):
"""Deal with dynamic shape in tensorflow cleanly."""
static = x.shape.as_list()
dynamic = tf.shape(x)
return [dynamic[i] if s is None else s for i, s in enumerate(static)] # 有值的返回,没有值的待定
def softmax(x, axis=-1):
x = x - tf.reduce_max(x, axis=axis, keepdims=True)
ex = tf.exp(x)
return ex / tf.reduce_sum(ex, axis=axis, keepdims=True)
def gelu(x):
return 0.5*x*(1+tf.tanh(np.sqrt(2/np.pi)*(x+0.044715*tf.pow(x, 3))))
def norm(x, scope, *, axis=-1, epsilon=1e-5): ## norm层
"""Normalize to mean = 0, std = 1, then do a diagonal affine transform."""
with tf.variable_scope(scope):
n_state = x.shape[-1].value
g = tf.get_variable('g', [n_state], initializer=tf.constant_initializer(1))
b = tf.get_variable('b', [n_state], initializer=tf.constant_initializer(0))
u = tf.reduce_mean(x, axis=axis, keepdims=True)
s = tf.reduce_mean(tf.square(x-u), axis=axis, keepdims=True)
x = (x - u) * tf.rsqrt(s + epsilon)
x = x*g + b
return x
def split_states(x, n):
"""Reshape the last dimension of x into [n, x.shape[-1]/n]."""
*start, m = shape_list(x) # *start 接受返回的除最后一个以外的值
return tf.reshape(x, start + [n, m//n]) # 准备多头
def merge_states(x):
"""Smash the last two dimensions of x into a single dimension."""
*start, a, b = shape_list(x)
return tf.reshape(x, start + [a*b])
def conv1d(x, scope, nf, *, w_init_stdev=0.02):
with tf.variable_scope(scope):
*start, nx = shape_list(x)
w = tf.get_variable('w', [1, nx, nf], initializer=tf.random_normal_initializer(stddev=w_init_stdev))
b = tf.get_variable('b', [nf], initializer=tf.constant_initializer(0))
c = tf.reshape(tf.matmul(tf.reshape(x, [-1, nx]), tf.reshape(w, [-1, nf]))+b, start+[nf])
return c
def attention_mask(nd, ns, *, dtype):
"""1's in the lower triangle, counting from the lower right corner.
Same as tf.matrix_band_part(tf.ones([nd, ns]), -1, ns-nd), but doesn't produce garbage on TPUs.
"""
i = tf.range(nd)[:,None]
j = tf.range(ns)
m = i >= j - ns + nd
return tf.cast(m, dtype)
def attn(x, scope, n_state, *, past, hparams): # 注意力decodinig的实现
assert x.shape.ndims == 3 # Should be [batch, sequence, features]
assert n_state % hparams.n_head == 0
if past is not None:
assert past.shape.ndims == 5 # Should be [batch, 2, heads, sequence, features], where 2 is [k, v]
def split_heads(x):
# From [batch, sequence, features] to [batch, heads, sequence, features]
return tf.transpose(split_states(x, hparams.n_head), [0, 2, 1, 3]) # tf.transpose(input, [dimension_1, dimenaion_2,…,dimension_n]):这个函数主要适用于交换输入张量的不同维度用的
def merge_heads(x):
# Reverse of split_heads
return merge_states(tf.transpose(x, [0, 2, 1, 3]))
def mask_attn_weights(w):
# w has shape [batch, heads, dst_sequence, src_sequence], where information flows from src to dst.
_, _, nd, ns = shape_list(w)
b = attention_mask(nd, ns, dtype=w.dtype)
b = tf.reshape(b, [1, 1, nd, ns])
w = w*b - tf.cast(1e10, w.dtype)*(1-b)
return w
def multihead_attn(q, k, v):
# q, k, v have shape [batch, heads, sequence, features]
w = tf.matmul(q, k, transpose_b=True) # 这里k转置
w = w * tf.rsqrt(tf.cast(v.shape[-1].value, w.dtype))
w = mask_attn_weights(w)
w = softmax(w)
a = tf.matmul(w, v) ## 如果past不为None 这一步之后 又回到了原来矩阵的shap
return a
with tf.variable_scope(scope):
c = conv1d(x, 'c_attn', n_state*3) # shape=(?, ?, 2304) 扩大 tf.split(c, 3, 2) 又分开了
q, k, v = map(split_heads, tf.split(c, 3, axis=2)) # list(map(square, [1,2,3,4,5])) -> [1, 4, 9, 16, 25]
present = tf.stack([k, v], axis=1)
if past is not None:
pk, pv = tf.unstack(past, axis=1)
k = tf.concat([pk, k], axis=-2)
v = tf.concat([pv, v], axis=-2)
a = multihead_attn(q, k, v) # a shape=(?, 12, ?, 64)
a = merge_heads(a) ## 合并多头
a = conv1d(a, 'c_proj', n_state) # 再次卷积
return a, present ## 预测的值, 每次的[k,v]
def mlp(x, scope, n_state, *, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value
h = gelu(conv1d(x, 'c_fc', n_state))
h2 = conv1d(h, 'c_proj', nx)
return h2
def block(x, scope, *, past, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value ## shape [None, None, 768]
a, present = attn(norm(x, 'ln_1'), 'attn', nx, past=past, hparams=hparams)
x = x + a
m = mlp(norm(x, 'ln_2'), 'mlp', nx*4, hparams=hparams) # MLP多层感知机
x = x + m
return x, present
def past_shape(*, hparams, batch_size=None, sequence=None):
return [batch_size, hparams.n_layer, 2, hparams.n_head, sequence, hparams.n_embd // hparams.n_head]
def expand_tile(value, size):
"""Add a new axis of given size."""
value = tf.convert_to_tensor(value, name='value')
ndims = value.shape.ndims # 维数
return tf.tile(tf.expand_dims(value, axis=0), [size] + [1]*ndims) # 这里+代表的是合并; tf.expand_dims增加一个维度 tf.tile用来对张量(Tensor)进行扩展的,其特点是对当前张量内的数据进行一定规则的复制。最终的输出张量维度不变。
def positions_for(tokens, past_length): ## 最终相对输出位置矩阵
batch_size = tf.shape(tokens)[0] # 将矩阵的维度输出为一个维度矩阵
nsteps = tf.shape(tokens)[1]
return expand_tile(past_length + tf.range(nsteps), batch_size) # tf.range(limit, delta=1, dtype=None, name='range');
def model(hparams, X, past=None, scope='model', reuse=False):
with tf.variable_scope(scope, reuse=reuse): # 共享变量model
results =
batch, sequence = shape_list(X) ## 这里会根据X的shape进行调整
wpe = tf.get_variable('wpe', [hparams.n_ctx, hparams.n_embd], # 位置编码权重 []
initializer=tf.random_normal_initializer(stddev=0.01)) # 如果已经定义了则不重复定义
wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd], # 编码权重
initializer=tf.random_normal_initializer(stddev=0.02))
past_length = 0 if past is None else tf.shape(past)[-2]
h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length)) # tf.gather(params,indices,axis=0 ) 从params的axis维根据indices的参数值获取切片
# Transformer
presents = []
pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer # 对矩阵进行分解
assert len(pasts) == hparams.n_layer
for layer, past in enumerate(pasts):
h, present = block(h, 'h%d' % layer, past=past, hparams=hparams)
presents.append(present)
results['present'] = tf.stack(presents, axis=1)
h = norm(h, 'ln_f') # shape=(?, ?, 768)
# Language model loss. Do tokens <n predict token n?
h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd])
logits = tf.matmul(h_flat, wte, transpose_b=True) ## 解码 返回:获得每个词的概率[[0.1,0.001,0.3...*5万]*输入的单词个数]*bs
logits = tf.reshape(logits, [batch, sequence, hparams.n_vocab]) ## 重新回batch.
results['logits'] = logits
return results
以上是关于gpt-2 中文注释 对gpt-2代码进行了梳理的主要内容,如果未能解决你的问题,请参考以下文章