[人工智能-深度学习-69]:数据集 - 目标检测常见公开数据集之PASCAL VOC
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-69]:数据集 - 目标检测常见公开数据集之PASCAL VOC相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122165644
目录
前言:
无论是利用神经网络做目标检测方面的任务还是参加公开的比赛,不可避免需要用到大量的训练数据,这就需要用到公开数据集。本文将简单介绍目前在目标检测中比较有名的常见大型数据集,这些数据集包括:PASCAL VOC, MS COCO, ImageNet。
第1章 PASCAL VOC
1.1 PASCAL VOC概述
Pascal VOC网址:The PASCAL Visual Object Classes Homepage
PASCAL:Pattern Analysis, Statistical Modeling and Computational Learning.
VOC: Visual Object Classes, 计算机视觉对象分类
PASCAL VOC挑战赛是计算机视觉对象的分类识别和坚持的一个基准测试提供了检测算法和学习性能评估系统。从2005年至今,该组织每年都会提供一些列类别的、带标签的图片,挑战者通过设计各种精妙的算法,仅根据分析图片内容来将器人类,最终通过准确率、召回率、效率等指标一绝高下。如今该挑战赛使用的数据集已经成为对象检测领域普遍接受的一种标准。
因此,再进一步学习目标检测前,有必要了解一下该数据集。
1.2 PASCAL VOC数据集概述
PASCAL VOC数据集有两个主要的版本,2007年和2012年版本。这两个版本并非相互包含的关系,而是互斥、相互补充关系,因此,他们之间是交叉使用的。如下是一些常见的组合:
- 07+12: 使用 VOC2007 和 VOC2012 的 train+val(16551) 上训练,然后使用 VOC2007 的 test(4952) 测试
- 07++12: 使用 VOC2007 的 train+val+test(9963) 和 VOC2012的 train+val(11540) 训练,然后使用 VOC2012 的 test 测试。
- 07+12+COCO: 先在 MS COCO 的 trainval 上 预训练,再使用 VOC2007 和 VOC2012 的 train+val 微调训练,然后使用 VOC2007 的 test 测试。
- 07++12+COCO: 先在 MS COCO 的 trainval 上预训练,再使用 VOC2007的 train+val+test 和 VOC2012 的 train+val微调训练,然后使用 VOC2012 的 test 测试
1.3 PASCAL VOC数据集中对象的类别
PASCAL VOC 2007 和 2012 数据集总共分 4 个大类:vehicle(交通工具)、household(家居)、animal(动物)、person(人)。总共 20 个小类(加背景 21 类),预测的时候是只输出下图中黑色粗体的子类的类别。

各种类别的组成如下图所示:

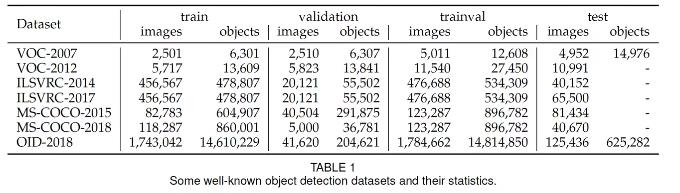
1.4 数据集中图片与目标的数量
VOC2007 和 VOC2012 目标检测任务中的训练、验证和测试数据统计如下表所示,具体每一类的数据分布见 PASCAL VOC2007 Database Statistics 和 PASCAL VOC2012 Database Statistics

备注:
- 一张图片中可以包含多少目标,因此目标的数量通常远大于图片的数量。
- 数据集分为训练集train、验证集val、测试集test。
 https://blog.csdn.net/u013832707/article/details/host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
https://blog.csdn.net/u013832707/article/details/host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar第2章 数据集的文件组织
2.1 主要的文件目录:
.
├── JPEGImages目录: 存放 原始的.jpg 格式的图片文件
├── Annotations目录:存放detection 任务时的标签文件,xml 形式,文件名与图片名一一对应
├── ImageSets目录:包含三个子文件夹 Layout、Main、Segmentation,其中 Main 存放的是分类和检测的数据集分割文件,Layout布局文件,Segmentation分割文件。
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── SegmentationClass目录:存放按照 class 分割的图片
└── SegmentationObject目录:存放按照 object 分割的图片
├── Main:数据集的配置文件,访问数据集的入口,指定哪些图片用于训练集,哪些图片用于测试集。
│ ├── train.txt: 指定用于训练的图片名称, 共 2501 个
│ ├── val.txt : 指定用于验证的图片名称,共 2510 个
│ ├── trainval.txt:指定train与val的合集。共 5011 个
│ ├── test.txt : 指定用于测试的图片名称,共 4952 个
第3章 目标检测的标签文件格式
3.1 标签的标准
3.2 内容解析
标注信息是用 xml 文件组织的如下:
<annotation> # 标签标识
<folder>VOC2007</folder> # 标签所在的目录
<filename>000001.jpg</filename> # 标签对应的图片
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>341012865</flickrid>
</source>
<owner>
<flickrid>Fried Camels</flickrid>
<name>Jinky the Fruit Bat</name>
</owner>
<size> # 图像尺寸
<width>353</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented> # 是否用于分割
<object> # 对象1
<name>dog</name> # 物体类别名称
<pose>Left</pose> # 拍摄角度:front, rear, left, right, unspecified
<truncated>1</truncated> # 目标是否被截断(比如在图片之外),或者被遮挡(超过15%)
<difficult>0</difficult> # 检测难易程度,这个主要是根据目标的大小,光照变化,图片质量来判断
<bndbox> # 目标对象的位置
<xmin>48</xmin> # x1
<ymin>240</ymin> # y1
<xmax>195</xmax> # x2
<ymax>371</ymax> # y2
</bndbox>
</object>
<object> # 对象2
<name>person</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>8</xmin>
<ymin>12</ymin>
<xmax>352</xmax>
<ymax>498</ymax>
</bndbox>
</object>
</annotation>
(1)一张图片,对应一个xml的标签文件
(2)一个标签文件,包括包含多个对象。
(3)一个对象,包含:
- 位置信息
- 分类信息
- 拍摄的角度信息
- truncated:是否是完整图片
- difficult:检测的难易程度
3.3 标签的创建
xml格式的标签,并不是通过手工生成的,而是通过工具生成的,有大量的标签生成的工具,常见的可视化标签的工具有:
- Labelimg
- Labeme
第4章 输出格式
4.1 分类任务:Classification Task
每一类都有一个 对应的txt 文件
每一行对应测试集中的一张图片,每行的内容:
- 前面一列是图片名称
- 后面一列为把该图片预测为该类别的分数(可能性大小)
# comp1_cls_test_car.txt, 内容如下
000004 0.702732
000006 0.870849
000008 0.532489
000018 0.477167
000019 0.112426
4.2 目标检测任务:Detection Task
每一类都有一个 txt 文件,主要内容为:
里面每一行都是测试集中的一张图片
每行的格式为:
<image identifier>:图片的名称标识<confidence> :检测为给分类的置信度,来mAP表示<left> <top> <right> <bottom>:(x1,y), (x2,y2)
# comp3_det_test_car.txt,内容如下
# comp3:只允许用所给训练数据,comp4:允许使用外部数据
000004 0.702732 89 112 516 466
000006 0.870849 373 168 488 229
000006 0.852346 407 157 500 213
000006 0.914587 2 161 55 221
000008 0.532489 175 184 232 201
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122165644
以上是关于[人工智能-深度学习-69]:数据集 - 目标检测常见公开数据集之PASCAL VOC的主要内容,如果未能解决你的问题,请参考以下文章
深度学习目标检测:YOLOv5实现车辆检测(含车辆检测数据集+训练代码)
深度学习目标检测:YOLOv5实现车辆检测(含车辆检测数据集+训练代码)