索引/事务bing原理
Posted 鸟随二月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了索引/事务bing原理相关的知识,希望对你有一定的参考价值。
目录标题
索引原理
前言
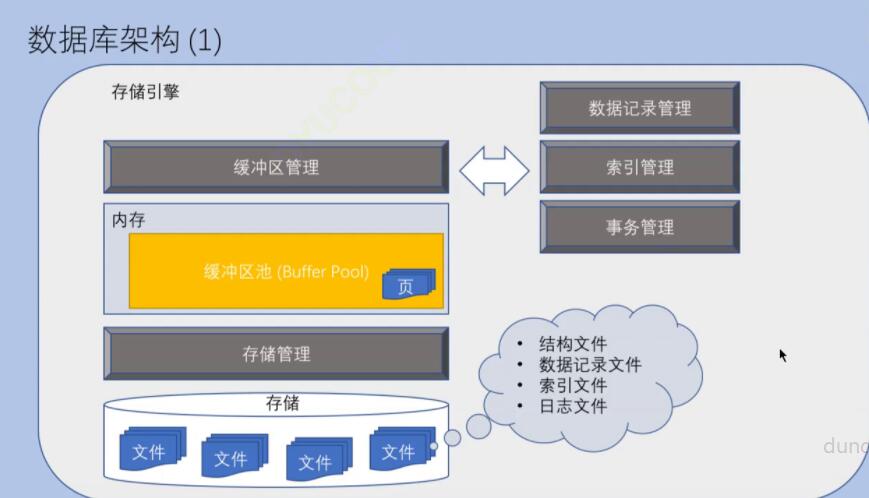

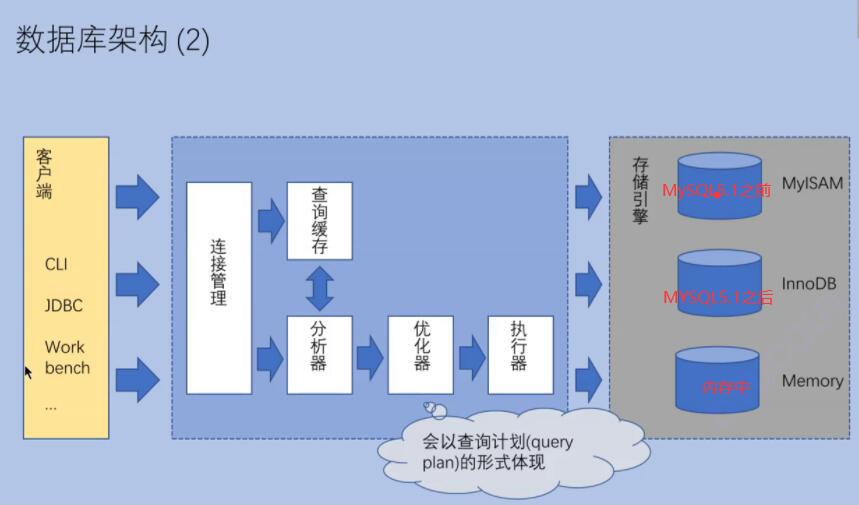

索引
索引独立数据文件(逻辑上),被数据管理系统独立管理的,和表中的数据有关联的,专门的算法设计,目的提高查询效率
索引分类
按照用途分类

按照数据结构分类
哈希索引,搜索树索引(哈希表,平衡二叉树,调表)
按照关联列分

索引的数据结构

哈希表和搜索树实现
哈希表的优点:
1)速度相对来说可以较快(也不是差别很大的快)
2)原理和实现简单——实现线程安全比较容易
平衡搜索树的优点:
1)搜索树中维护的 key是有序的!
2)不会出现哈希冲突剧烈的情况

二叉树搜索树(AVL、红黑树) vB-树系列
AVL树和红黑树在各种场景下,差别极小。
AVL的高度咯<红黑的高度1)查找理论上可以更快一点(差别很少,基本可以忽略不计)
2)调整的速度较慢(基本可以忽路不计)
二叉平衡搜索树和多叉平衡搜索树
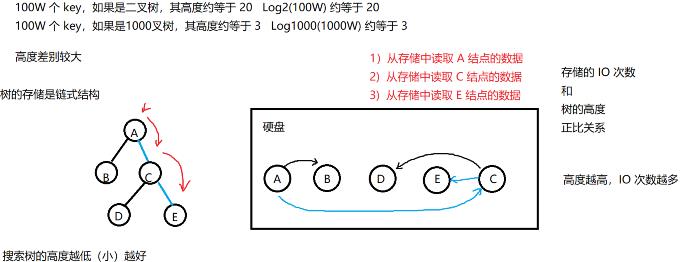
b树和b+树

索引优缺点
优点:
• 极大地提升查询速度
缺点:
• 增加空间使用
• 增加修改成本
• 创建索引也算需要消耗时间的
索引原则
• 在大量数据的表上添加索引
• 不要在服务在线时轻易调整索引
• 在经常作为查询条件或者排序依据
的列上添加索引
• 通过设计 SQL,提高索引的利用率
索引命中规则
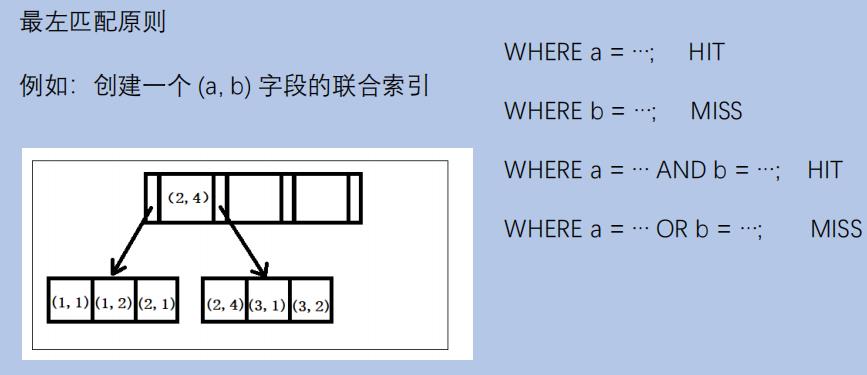
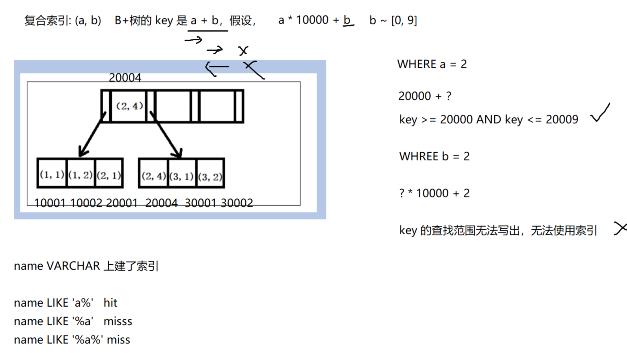
EXPLAIN SQL命令查看查询执行计划,通过这个结果,可以进一步分析查询是否有命中索引!
explain查询SQL;
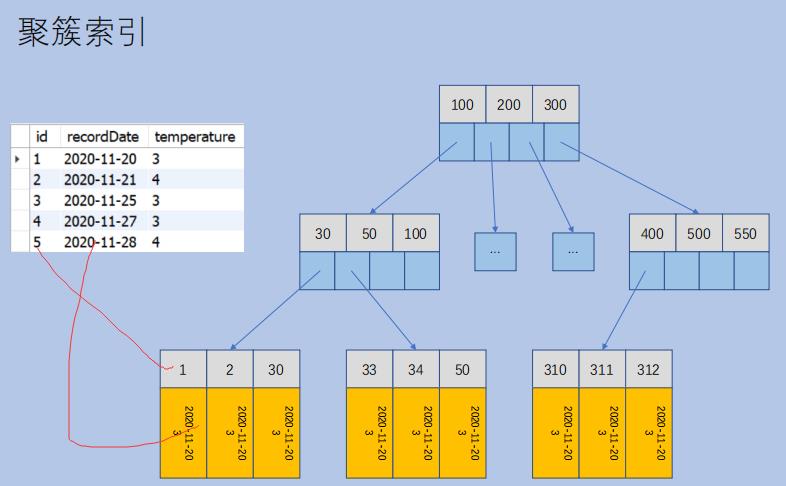
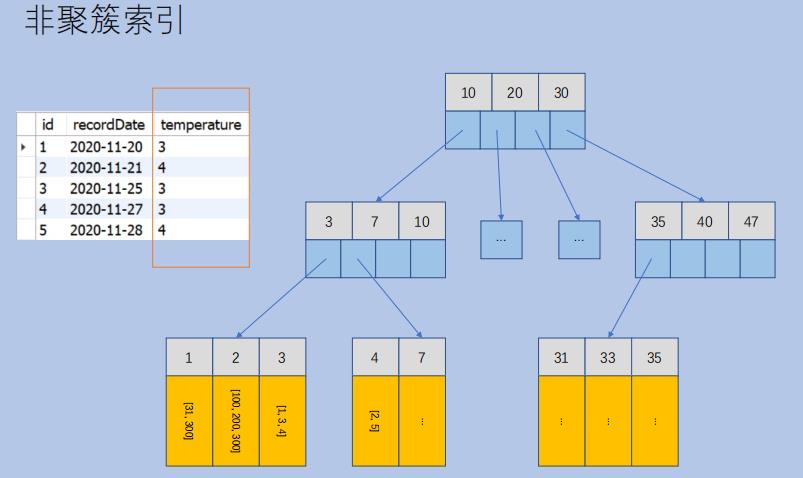
InnoDB 中的 聚簇索引(clustered index) vs 非聚簇索引(b+树)
InnoDB 中,数据记录文件被维护在以主键作为 key 的 B+树中,数据记录作为 B+树 的 value 被维护在叶子结点中。这种数据记录文件又被称为聚簇索引。
与之相对的,其他普通索引文件则被称为非聚簇索引。

事务

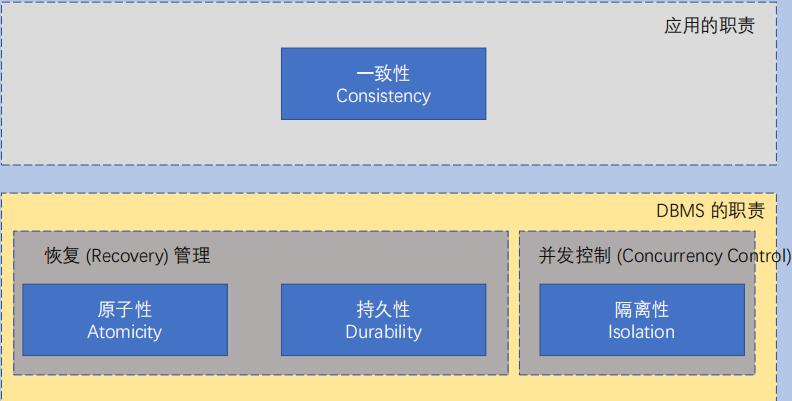
特性
原子性:不涉及并发的场景,一个事务的中的所有SQL(一个或者多个)应该视为一个整体。all or none
持久性:一个事务一旦提交(Commit),修改必须持久化。即使之后出现问题了,需要保证修改仍然生效
隔离性:并发的事务互相之前不可见,也互不影响。——理想目标
—致性:和不同的业务相关的
转账系统:所有人账户的金额总数不变
借书系统:—本书的总量-—本书的存量=这本书的借阅记录和
超越数据的部分,往往需要更复杂的动作去处理,我们暂时不讨论
3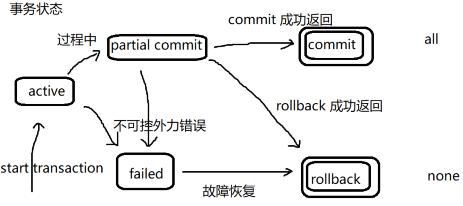
数据库储存策略
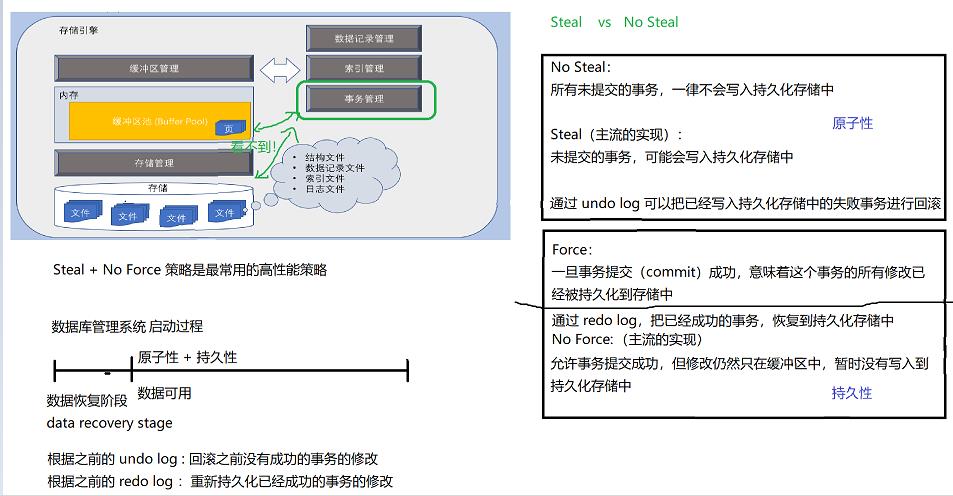
undolog
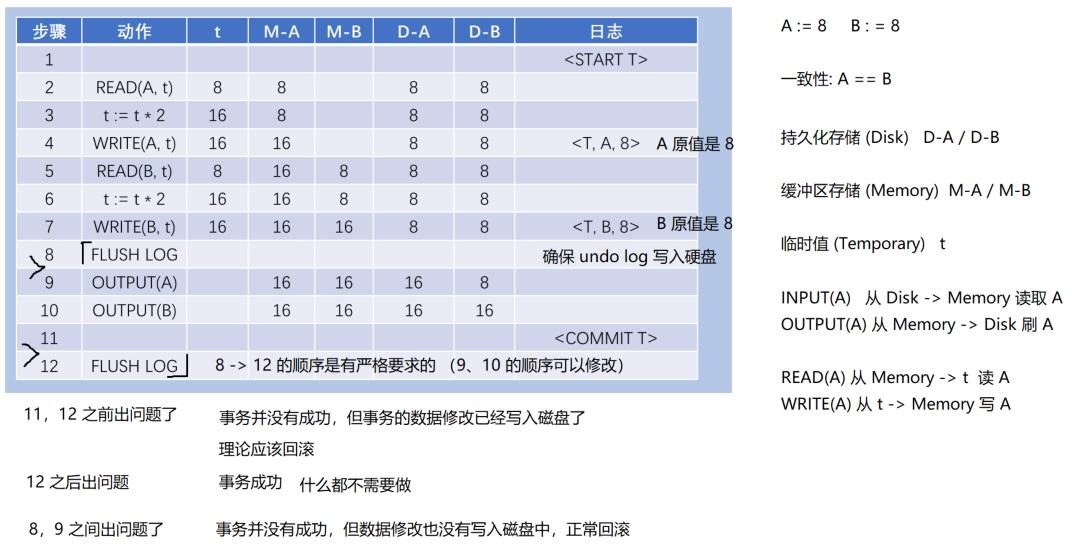
redolog
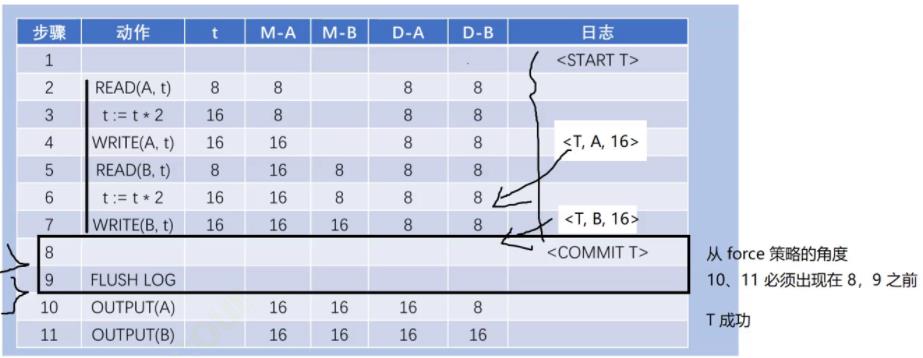
总结:

• 日志的大小远远小于数据记录的大小
• 日志的写入往往是追加(append)的,数据记录的写入则是随机(random)的
事务的实现
隔离级别
并发控制的实现
加锁


两阶段所会出现死锁
时间戳机制

多版本控制

例如:

性能优化
• 轻易不去惹事(在进行设计时,不要引入造成性能下降的设计)

• 遇到事咱也不怕事(有一套方法论来解决问题)

• 知道自己的能力边界,学会去摇人(超出 RDBMS 能力范围的用其他方案)
学会使用大数据(Hadoop、Hive、Spark……)解决问题

以上是关于索引/事务bing原理的主要内容,如果未能解决你的问题,请参考以下文章