NeurIPS 2021 | 图像未必值16x16词:可变序列长度的动态视觉Transformer来了
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NeurIPS 2021 | 图像未必值16x16词:可变序列长度的动态视觉Transformer来了相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
作者 | 王语霖
本文主要介绍刚刚被NeurIPS-2021会议录用的一篇关于动态Transformer的最新工作:Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length,全部代码和预训练模型已经在Github上开源。
论文地址:https://arxiv.org/abs/2105.15075
项目地址:https://github.com/blackfeather-wang/Dynamic-Vision-Transformer
太长不看版:以ViT为代表的视觉Transformer通常将所有输入图像表征为固定数目的tokens(例如16x16和14x14)。这项工作发现采用定长的token序列表征数据集中所有的图像是一种低效且次优的做法,并提出一种可针对每个样本自适应地使用最合适的token数目进行表征的动态ViT模型。该方法在ImageNet上将T2T-ViT的平均推理速度(GPU实测)加快了1.4-1.7倍。其主要思想在于利用级联的ViT模型自动区分“简单”与“困难”样本,实现自适应的样本推理。为了减少级联模型中的冗余计算,文章还提出了特征重用与关系重用的模型设计思路。
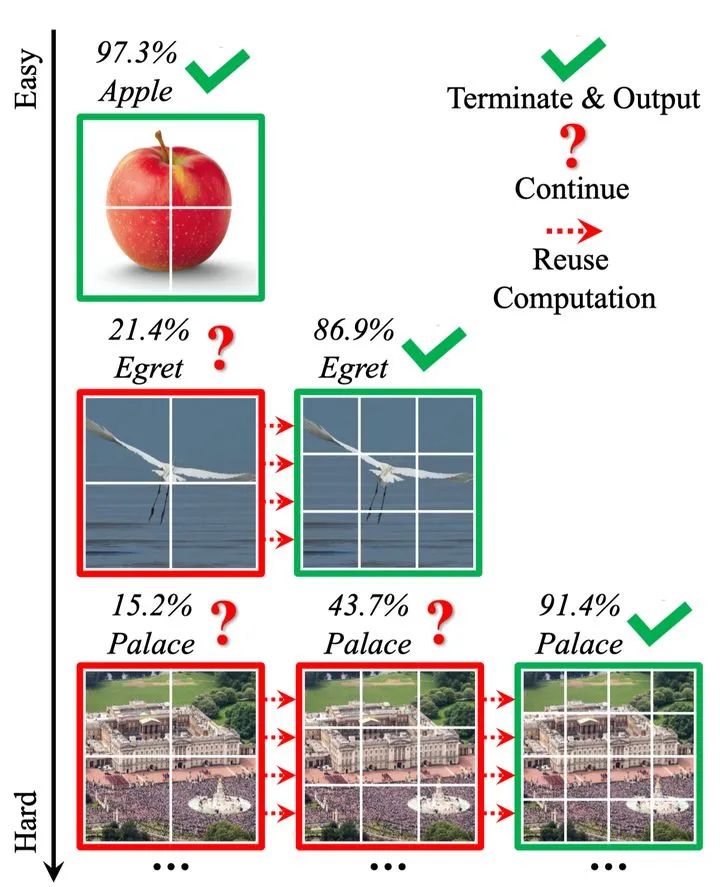 图1 Dynamic Vision Transformer(DVT)示例
图1 Dynamic Vision Transformer(DVT)示例
1
Introduction(研究动机及简介)
近半年来,以Google的工作《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》为代表的Vision Transformer(ViT)系列视觉模型受到了学界的广泛关注,这些模型通常将图像数据划分为固定数目的patch,并将每个patch对应的像素值采用线性映射等方式嵌入为一维的token,作为Transformer模型的输入,示意图如下所示。
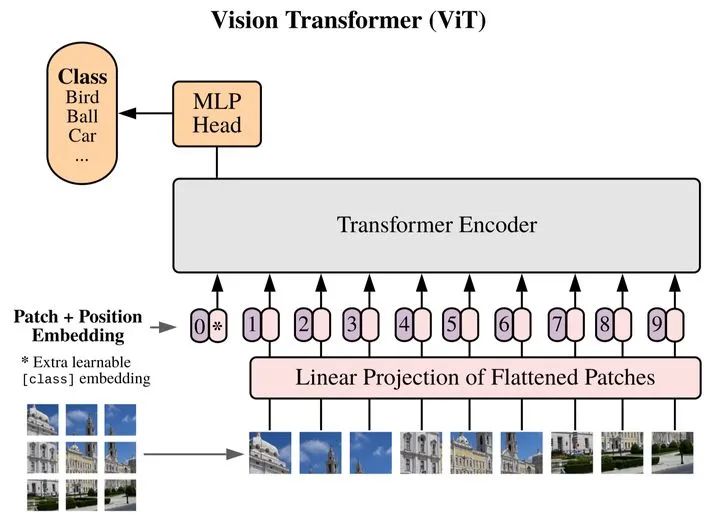
图2 Vision Transformer(ViT)对输入的表征方式
假设模型结构固定,即每个token的维度大小固定,将输入表征为更多的token可以实现对图片更为细粒度的建模,往往可以有效提升模型的测试准确率;然而与此相对,由于Transformer的计算开销随token数目成二次方增长,增多token将导致大量增长的计算开销。为了在精度和效率之间取得一个合适的平衡,现有的ViT模型一般将token数设置为14x14或16x16。
而论文则提出,一个更合适的方法应当是,根据每个输入的具体特征,对每张图片设置对其最合适的token数目。具体而言,不同图片在内容、远近、物体大小、背景、光照等诸多方面均存在较大的差异,将其切分为相同数目和大小的patch没有考虑适应这些要素的变化,因而极有可能是次优的。以下图为例,左侧的苹果图片构图简单且物体尺寸较大,右侧图片则包含复杂的人群、建筑、草坪等内容且物体尺寸均较小。显然,前者只需要少量token就可以有效表征其内容,后者则需要更多的token描述不同构图要素之间的复杂关系。

图3 根据具体输入确定token数目
这一问题对于网络的推理效率是非常关键的。在下表中,文章使用比原文推荐值(14x14)更少的token数目训练了一个T2T-ViT-12模型,并报告了对应的测试精度和计算开销。从结果中可以看到,若将token数目设置为4x4,准确率仅仅下降了15.9%(76.7% v.s. 60.8%),但计算开销下降了8.5倍(1.78G v.s. 0.21G)。这一结果表明,正确识别占数据大多数的较“简单”的样本只需4x4或更少的token,相当多的计算浪费在了使用存在大量冗余的14x14 token表征他们。
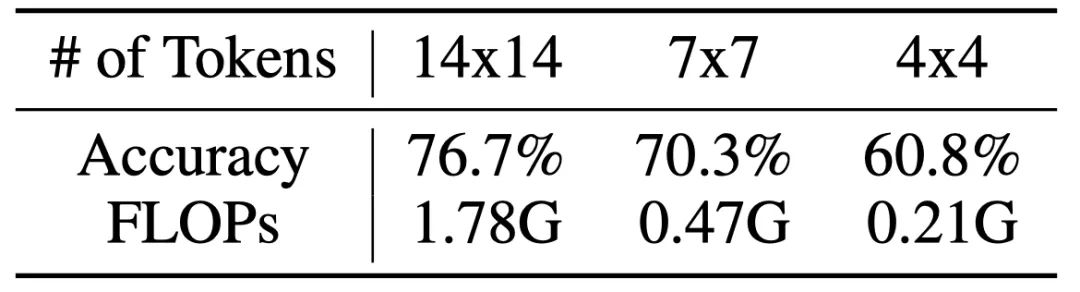
表1 T2T-ViT-12使用更少token时的测试精度和计算开销
2
Method(方法详述)
受到上述现象的启发,论文提出了一个动态视觉Transformer框架(Dynamic Vision Transformer,DVT),意在针对每个样本选择一个合适数目的token来进行表征。
首先介绍DVT的推理过程,如图2所示。论文使用从小到大的token数目训练了一组Transformer模型,他们具有相同的基本结构,但是参数相互独立,以分别适应逐渐增多的token数目。对于任意测试样本,首先将其粗略表征为最小数目的token,输入第一个Transformer,以低计算成本迅速得到初步预测。而后判断预测结果是否可信,若可信,则直接输出当前结果并终止推理;若不可信,则将输入图片表征为更多的token,激活下一个Transformer进行更细粒度、但计算开销更大的的推理,得到结果之后再次判断是否可信,以此类推。论文采用将预测的置信度(confidence)与一个固定阈值进行比较的方式作为准出的判断准则,关于这一方法的细节和其合理性的验证,由于空间有限,请参见paper。
值得注意的是,处于下游的Transformer可以复用先前模型已产生的深度特征和注意力图(attention maps),以尽可能避免进行冗余和重复的计算,关于这一点,将在下文详述。
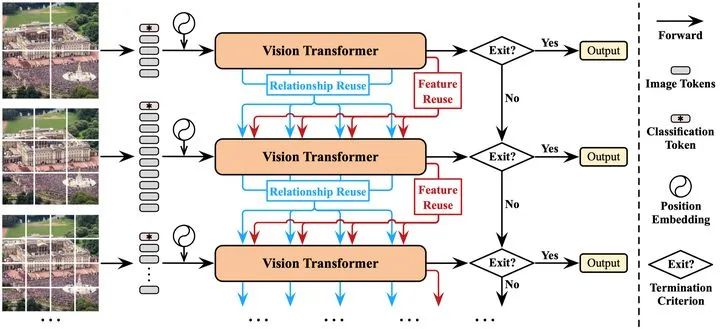
图4 Dynamic Vision Transformer(DVT)
在训练时,论文简单地训练网络在所有出口都取得正确的预测结果,训练目标如下式所示。其中 和
和 分别代表数据和标签,
分别代表数据和标签,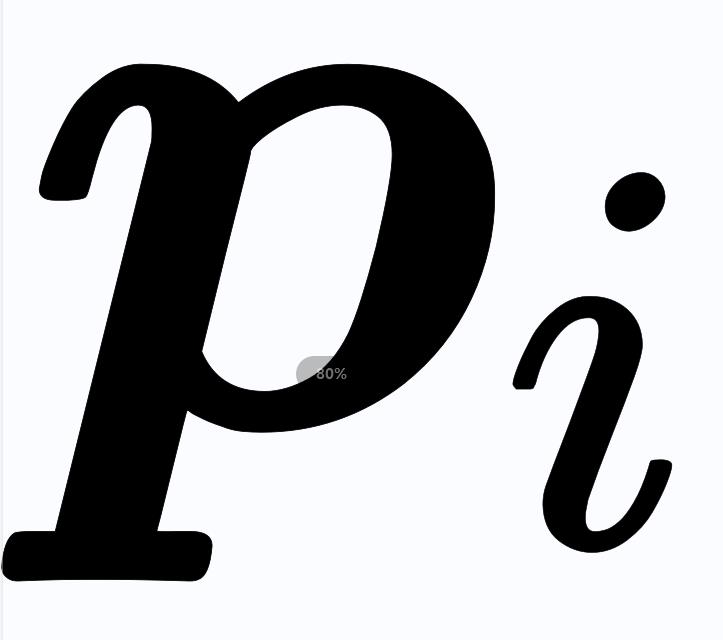 代表第
代表第 个出口的softmax预测概率,
个出口的softmax预测概率, 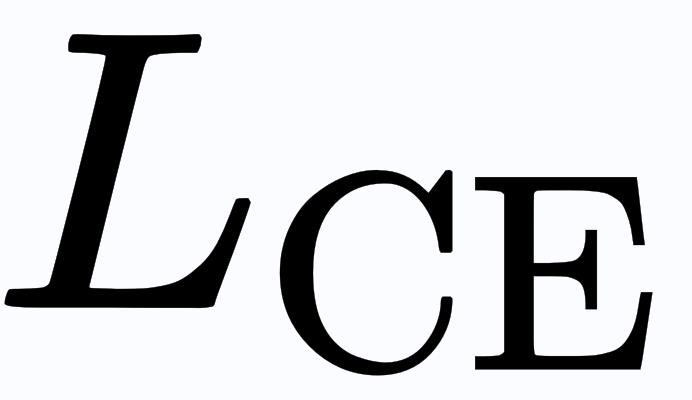 代表交叉熵损失。
代表交叉熵损失。
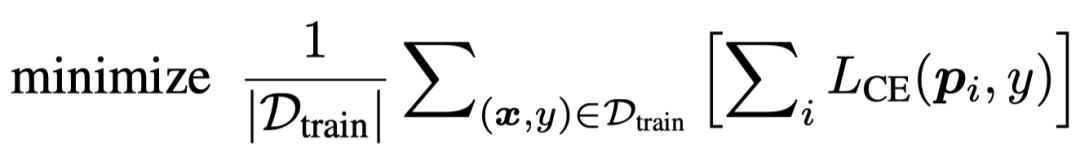
显然,DVT框架中所有的Transformer都具有相同的训练目标。因此当一个处于下游位置的Transformer被激活时,一个显然更为高效的做法是,应当训练其在先前Transformer已提取的特征的基础上进行进一步提升,而非完全从0开始重新提取特征。出于这一点考虑,论文提出了一个特征复用机制,如下图所示。将上游Transformer最后一层输出的特征取出,经MLP变换和上采样(Upsample)后,作为上下文嵌入(Context Embedding)以Concat的方式整合入下游模型每一层的MLP模块中。
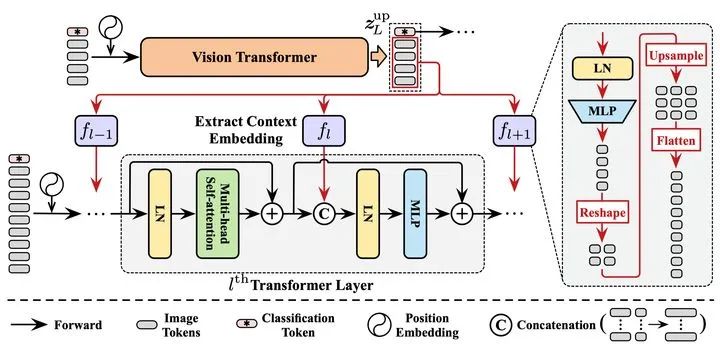
图5 特征复用(Feature Reuse)机制
除特征外,Transformer中还有一个关键的组分,即自注意力机制中的注意力图(attention maps)。视觉Transformer通过这些注意力图建模token之间的关系,从而实现对每个具体的token进行来自全局的信息整合。在论文所提出的DVT框架中,位于下游的模型同样可以借助上游Transformer已经得到的注意力图来进行更准确的全局注意力关系建模,论文称之为关系复用,示意图如下所示。将上游模型的全部注意力图以logits的形式进行整合,经MLP变换和上采样后,加入到下层每个注意力图的logits中。这样,下游模型每一层的attention模块都可灵活复用上游模型不同深度的全部attention信息,且这一复用信息的“强度”可以通过改变MLP的参数自动地调整。
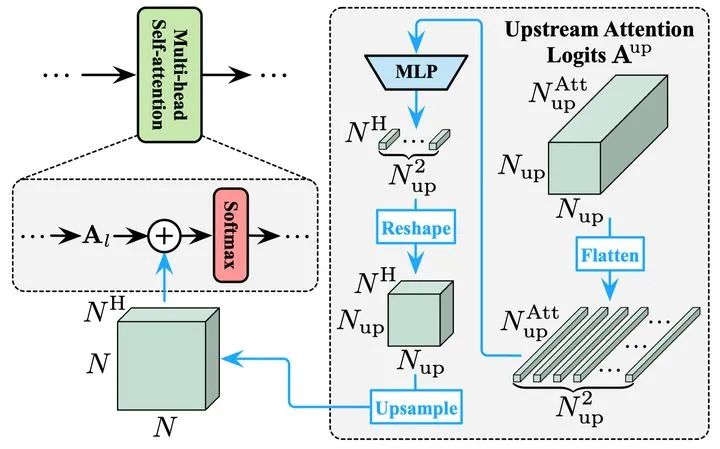
图6 关系复用(Relationship Reuse)机制
值得注意的是,对特征图进行上采样需要对其行或列进行重组后分别完成,以确保其几何关系的对应性,下图给出了一个例子。
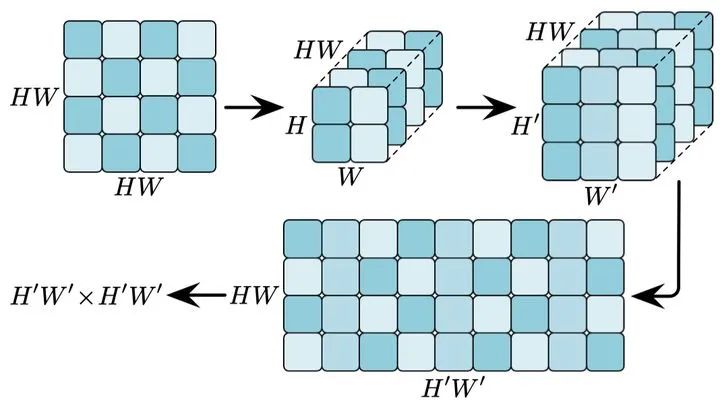
图7 对注意力图进行上采样
由于空间有限,关于DVT的更多细节以及对两种复用机制有效性的验证、结构设计的探究和更进一步的讨论,请参见paper。
3
Experiments(实验结果)
DVT的一个显著优势在于,大多数的视觉Transformer均可作为其的backbone以获得更高的计算效率,在实验中,论文基于T2T-ViT和DeiT测试了所提出的的方法。
DVT(T2T-ViT-12/14)在ImageNet图像识别任务上的计算效率如下,可见该方法对backbone的提速比在1.6-3.6x,对大模型效果尤为明显。
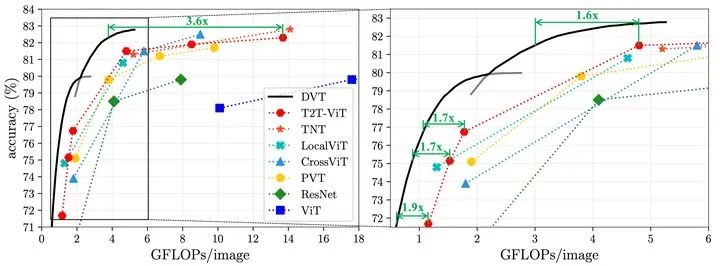
图8 DVT(T2T-ViT)在ImageNet上的计算效率
DVT(T2T-ViT-14)在ImageNet上的实际推理速度如下,基于Nvidia 2080Ti GPU,batch size=128,在每个出口移除终止推理的样本。对于小模型,DVT可以在不减慢速度的前提下显著提升效果;对于大模型,DVT可以在不降低表现的前提下显著提速。
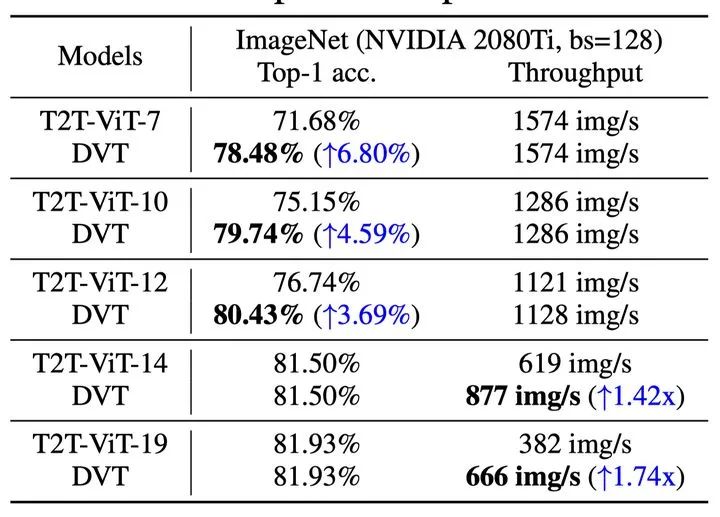
表2 DVT(T2T-ViT)在ImageNet上的实际速度
DVT(T2T-ViT-12/14)在CIFAR图像识别任务上的计算效率如下。

表3 DVT(T2T-ViT)在CIFAR上的计算效率
DVT(DeiT)在ImageNet图像识别任务上的计算效率如下,该方法效果同样明显。
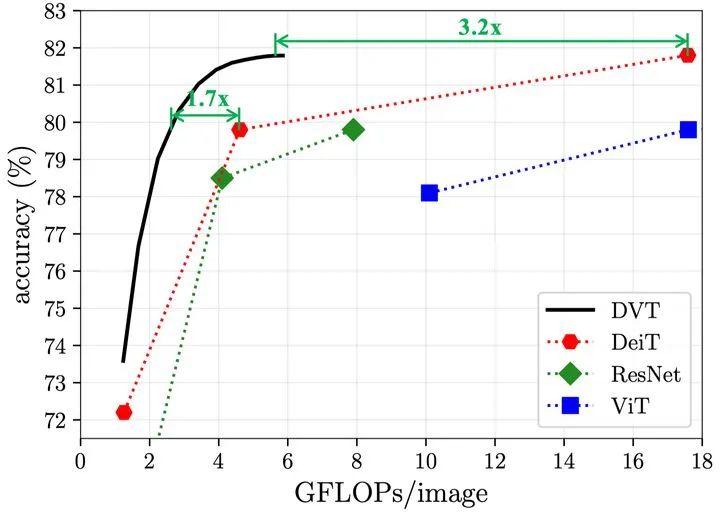
图9 DVT(DeiT)在ImageNet上的计算效率
那么,什么样的样本适合更少的token,什么样的样本适合更多的token呢?下图给出了可视化的结果,“easy”和“hard”分别代表需要少和多的token数目。可见,后者往往包含复杂的场景、较小的物体尺寸、以及一些非常规的姿态和角度。

图10 可视化结果
4
Conclusion(结语)
这篇工作的价值至少体现在两个方面:
(1)针对视觉Transformer提出了一个自然、通用、有效的自适应推理框架,理论和实际效果都比较显著。
(2)提出了一个颇具启发性的思路,即目前大多数视觉Transformer采用的、对全部图片以固定方式划分patch的表征方式,是不够灵活和次优的,一个更合理的策略是,应当根据输入数据动态调整表征方式。这或为开发高效、可解释性强、迁移性好的通用视觉Transformer提供了新方向。
如有任何问题,欢迎留言或者加入迈微微信学习交流群,回复“加群”。
作者主页链接:https://www.rainforest-wang.cool/
本文经授权转载自知乎:rainforest wang
原文:https://zhuanlan.zhihu.com/p/377961269?utm_source=wechat_session&utm_medium=social&utm_oi=774545462739861504&s_r=0
© THE END
投稿或寻求报道微信:MaiweiE_com
更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!尽量 hhh
GitHub中文开源项目《计算机视觉实战演练:算法与应用》,“免费”“全面“”前沿”,以实战为主,编写详细的文档、可在线运行的notebook和源代码。第十七章专门介绍 Transformer。
项目地址 https://github.com/Charmve/computer-vision-in-action
项目主页 https://charmve.github.io/L0CV-web/
推荐阅读
(更多“抠图”最新成果)
迈微AI研习社
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve

如果觉得有用,就请点赞、转发吧!
以上是关于NeurIPS 2021 | 图像未必值16x16词:可变序列长度的动态视觉Transformer来了的主要内容,如果未能解决你的问题,请参考以下文章