电商风控赛事亚军方案分享!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了电商风控赛事亚军方案分享!相关的知识,希望对你有一定的参考价值。
Datawhale干货
作者:许汝超,广州大学,Datawhale成员
本次 Apache Flink 极客挑战赛暨 AAIG CUP——电商推荐“抱大腿”攻击识别 赛题以电商推荐反作弊为背景,要求选手在少样本、半监督、隐私保护的场景下搭建风控模型来实时预测用户点击商品的行为是否恶意,实现对恶意流量的实时识别。下面分享一下我们队伍对本次比赛的理解和详细方案。
代码开源地址:
https://github.com/rickyxume/TianChi_RecSys_AntiSpam
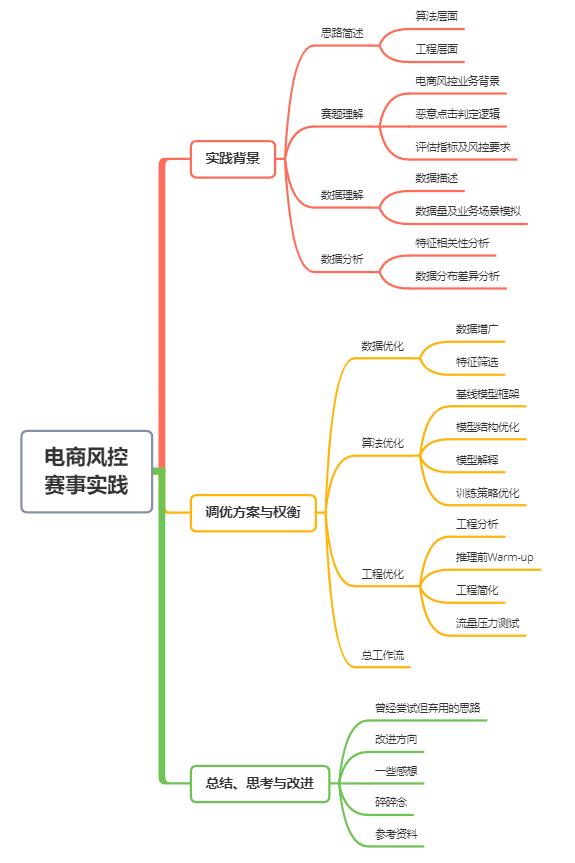
实践背景
1.1 思路简述
本赛题属于结构化数据二分类任务,虽然是风控竞赛,但思考方向不局限于欺诈检测或异常检测,还可以参考推荐系统里的CTR预估、交互序列建模和图建模等方向,可能会有更多启发。Apache Flink 极客挑战赛毕竟是个算法和工程并重的比赛,所涉及到的技术点也主要是在算法和工程两个方面。
算法上涉及数据增广、降噪、类别不平衡、半监督学习、增量训练、模型剪枝、压缩和加速等。
工程上涉及写 FlinkSQL 在线特征工程、Flink 性能调优、Ai Flow 工作流定义、Occlum 搭建TEE、Analytics Zoo Cluster Serving 分布式推理调用、模型pb文件冻结和 Docker 的使用等。
1.2 赛题理解
电商风控业务背景
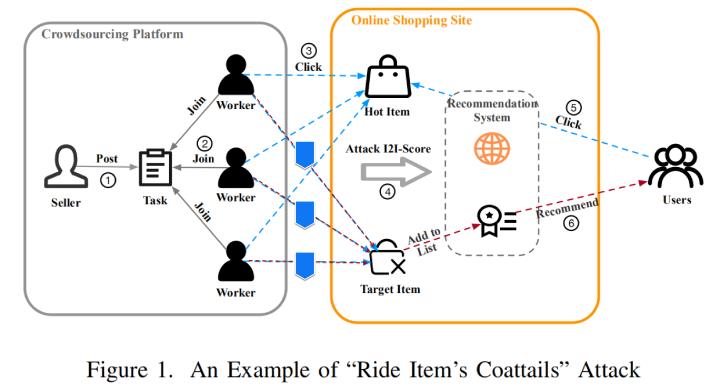
众所周知,电商平台会基于用户点击商品的行为来做个性化推荐,而一些不怀好意的商家可能想要推销自己的低质量商品,就在黑产市场买一个提高商品流量曝光的服务,具体操作就是雇佣一批黑产用户(可能是机器,也可能是肉鸡)去协同点击目标商品(即商家想要提升曝光度的商品)和爆款商品来提高电商平台推荐系统中两商品间的I2I关联分,用大白话来说就是“蹭流量”,通过这种方式干扰推荐系统来给恶意商家的商品更多曝光,极易误导消费者以爆款心理购买到劣质商品,影响平台治理,有损用户利益,所以需要风控系统去实时识别用户行为来过滤恶意流量。
恶意点击判定逻辑
理解打标签的逻辑对于理解赛题数据至关重要。
对于本赛题中的数据标签,仅当 user 和 item 满足均为恶意的条件,即恶意用户点击恶意商家的商品时,该点击行为才是恶意的,也就是图例中间三条红线才是恶意点击(label = 1),而其余情况,包括图中剩下的三条蓝线,都不算恶意点击(label = 0)。
评估指标及风控要求
本赛题对风控系统的安全和性能都有较高要求,需要在保证模型和数据安全的前提下,及时并准确地拦截恶意流量,实现实时风控。
环境要求:Occlum HW 模式(即在TEE下运行)
技术组件要求:必须使用 AI Flow 定义整个工作流,预测过程必须使用 Flink 作为实时计算引擎,其核心预测过程使用 Cluster Serving 完成。
时间限制:第一阶段训练推理时间不限,第二阶段训练推理限时15min,总时长不超过2h。
评估指标:,即两阶段F1得分与延迟符合要求(500ms以内)的数据占比的乘积之和
1.3 数据理解
数据描述
赛方提供匿名处理后的结构化数据,以供选手程序用于离线训练和在线推理,包含uuid、用户访问商品时间、用户id、商品id、商品及用户属性特征和标签,各字段描述如下:
| 字段 | 含义 |
|---|---|
| uuid | 数据集中唯一确认每条数据的id。 |
| visit_time | 该条行为数据的发生时间。实时预测过程中提供的数据的该值基本是单调递增的。 |
| user_id | 该条数据对应的用户的id |
| item_id | 该条数据对应的商品的id |
| features | 该数据的特征,复赛中,包含152个用空格分隔的浮点数。其中,第1 ~ 72个数字代表商品的特征,第73 ~ 152个数字代表用户的特征。 |
| label | 值为0、1或-1,1代表该数据为恶意行为数据,0为正常,-1则表示数据未标注。 |
数据量及业务场景模拟
为模拟实际业务中的模型迭代场景,工作流分为两个阶段。
第一阶段可以使用100w条数据,其中10w条有标签用于离线训练,5w条测试数据用于实时推理;
第二阶段可以使用第一阶段所有数据以及100w条新增数据,其中1w条有标签,5w条测试数据。
1.4 数据分析
特征相关性分析
首先,对给定的152维匿名的商品和用户的属性特征做拆分,其中商品特征为前72维,用户特征为后80维,分别对其按字母前缀和序号逐个命名,做特征相关性可视化分析。

可以发现,特征相关系数矩阵热力图中有很多深色方块,表明其存在多重共线性特征,特征冗余较多,商品特征热力图的颜色大体上更深,说明商品特征与行为标签更相关(侧面表明商品可以表征商家),而在用户特征中(观察右图中空白处)存在三列全部值都一样的无效特征(u77、u78、u79)。
数据分布差异分析
选取前面得到的与目标相关性较高的12个特征,分别绘制其在第一阶段的训练集、测试集和全部数据上的密度分布曲线,图中红色的曲线是测试集的,可以明显发现分布差异。
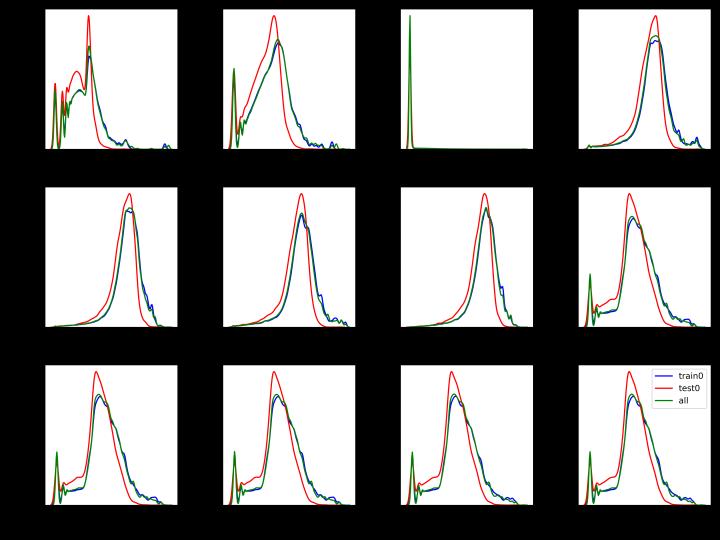 目标相关性top12特征在各集合上的数据密度分布曲线
目标相关性top12特征在各集合上的数据密度分布曲线
进一步地,我们简单使用 CatBoost 模型去区分训练集和测试集,在训练集和测试集中随机采样部分数据,逐个去除特征重要性高的特征,反复试验做对抗验证。
 对抗验证模型ROC曲线与基线对比图
对抗验证模型ROC曲线与基线对比图
我们发现,逐个去除u80、i69、i70、i72、i5、i16、i71、i17、i18、i62、i61、i58、i57、i43、i64、i31、i32、i36、i39等较多特征之后,模型仍然有一定的区分能力,说明存在较多分布差异大的特征。
另外,我们通过对用户冷启动的分析发现,在线下已知的所有数据中,存在约28%的重复样本,重复样本较多,训练集与测试集中都出现的老用户数和总用户数之比仅为 769/351744 ,也就是说,只有不到0.22%的用户是老用户,测试集几乎全是新用户。由此可以判断出数据样本量过小以至于样本构成十分不稳定。
在数据分析期间,我们还做了许多新特征的衍生和构建,发现了一些能有效涨点的历史统计特征和交叉特征,如历史滑窗点击次数和恶意点击率、多次点击的时间差和标准差、商品历史独立访客数和熵等,考虑到 FlinkSQL 实现麻烦和延迟较高等问题,在特征挖掘方向的探索止步于此。
至此,经过前面的数据分析可以发现存在三个问题:
数据数量上,有标签的数据量较少,重复样本较多
数据质量上,特征冗余较多,存在3个无效特征
测试集和训练集的数据分布差异大
后续思考方案可以对这些问题做针对性的优化改进。
调优方案与权衡
根据对赛题和数据的深入理解,可以了解到风控系统对算法和工程要求都很高,要快要准又要安全,而本赛题的数据标签少、特征冗余多、数据分布差异又大,所以我们的总体调优方案分成四部分,分别是对数据、算法、工程和策略的优化。策略优化在各个步骤之中体现。

2.1 数据优化
第一大方向是数据优化,包括用黑白名单做数据增广和用特征切片做特征筛选,提高数据的数量和质量。
2.1.1 数据增广
受到风控策略中对用户分级分类建立黑白灰名单的启发,将黑白名单引入数据增广策略之中。
根据前面对打标签逻辑的理解,可以将原先的单一点击行为标签细化到用户和商品(商家)上,针对已有标签的样本,对其行为关联的用户和商品两两建立黑白名单,通过已知样本的标签推理出未知样本的标签。
 黑白名单策略示意图
黑白名单策略示意图
黑白名单策略如图所示,具体步骤如下:
① 对于label=1的样本,用户和商品都是恶意的,将其标记为1得到两个黑名单;
② 对于label=0的样本,结合黑名单中标记过的id,只要用户或商品其中一个标签是恶意的,那么另一个大概率是正常的,将其标记为0,由此可又以得到两个白名单;
③ 对于label=-1的样本,通过黑白名单判断(label = user_label * item_label)得到最终的行为标签。
根据黑白名单的方法我们可以将原先10w的标签数据扩充到30w+,数据量增加了两倍,可以缓解数据量少的问题。
2.1.2 特征筛选
考虑到赛方提供的数据都是匿名特征,可能是embedding或标准化后的数据,所有特征对于深度神经网络来说可能都有用,所以我们并没有筛掉很多特征,仅筛掉前面数据分析时发现的3个全部值都一样的无效特征。
考虑到工程实现的简洁性,直接在模型内实现一个预处理层,输入时以特征切片的形式把3个无效特征切掉,将剩余的有效特征合并,再传入模型做后续计算,提高数据质量的同时模型复杂度也随之减小,还省去了写FlinkSQL。
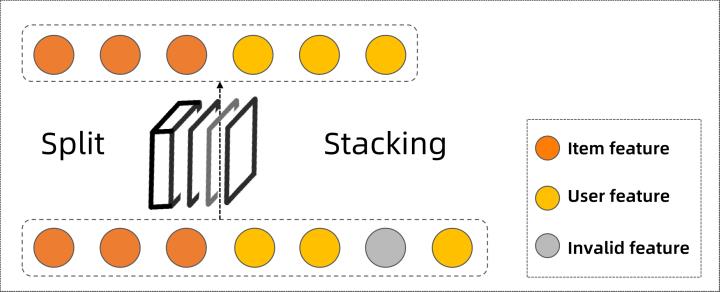
特征切片预处理层示意图
class SplitUI(Layer):
# 忽略无效特征
def __init__(self, **kwargs):
super(SplitUI, self).__init__(**kwargs)
def call(self, inputs):
# 按第二个维度对tensor进行切片,返回一个list
in_dim = K.int_shape(inputs)[-1]
assert in_dim == 152
# 忽略掉149,150,151
return [inputs[:, :72], inputs[:, 72:72+76], inputs[:, 148+3:152]]
def compute_output_shape(self, input_shape):
return [(None, 72), (None, 76), (None, 1)]2.2 算法优化
第二大方向是算法优化,包括模型结构和训练策略的优化,提高模型训练效率和泛化能力。
2.2.1 基线模型框架
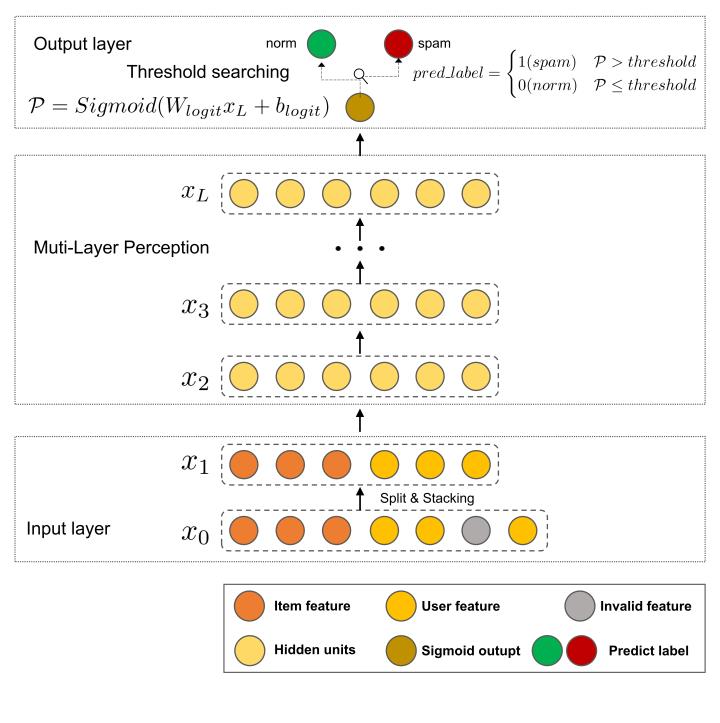
基线模型框架图
暂时不管模型参数设置,我们先构建一个基线模型的框架,类似汉堡的结构。
输入层就是前面说的预处理层,中间层是最朴素的MLP,最后一层是阈值层,阈值层里的阈值搜索和以往那些评估F1的竞赛大体上一样,就是多一步,搜完最佳阈值要加进模型里。
本赛题中使用阈值搜索的具体步骤如下:
① 先训练并保存一个输出为Sigmoid的模型;
② 读取保存的模型,在验证集上做阈值搜索,找到最高F1所在的最佳阈值;
③ 将最佳阈值追加至模型最后一层把Sigmoid的输出变成01标签。
④ 保存并冻结模型
中间的MLP虽然很快但缺点也很明显,表达能力受限,所以我们考虑换用复杂一点的模型。
一开始也是直接套模型,魔改网络,双塔结构、加注意力、加专家网络等等,曾经尝试过推荐系统里的CTR模型,比如说,Wide&Deep、AutoInt、DCN-Mix、deepFM等等,要么复杂度极高训练极慢,要么训练蛮快的但效果一般。直到复赛结束的前几天我们也还在尝试各种复杂模型,结果表明,不理解数据和模型就生搬硬套纯属浪费时间。我们的问题可能在于没有考虑到数据分布差异和特征冗余的情况,所以我们决定就在最简单的MLP上不断叠加buff,来缓解或解决这些问题。
2.2.2 模型结构优化
针对数据冗余问题,我们设计了一个简单高效的深度白化残差网络 DeepWRN (Deep Whitening Residual Networks),把基线模型框架里的MLP替换成了我们设计的 DeepWRN。
 深度白化残差网络模型框架图
深度白化残差网络模型框架图
思路很简单,用于降噪的“白化”可以消除数据冗余,类似集成学习的“残差”可以提升模型性能。
实现也很简单,深度白化残差网络在MLP基础上仅需组合 BatchNorm、Dropout 和 Add 这三个简单操作即可实现。简单来说就是,把每一个BN层后面都加上Dropout,然后经过ReLU激活再把Dropout后的值加到原先的输入上。(其实残差部分优化空间很大,由于时间问题还没有仔细实验)
展示一下MLP改进前后线上的得分情况,F1基本上有3个百分点的提升,总分提高了6.77%。
 线上得分情况对比
线上得分情况对比
2.2.3 模型解释
为什么简单的MLP经过改进也可以有这么大的性能提升?
下面分别讲一下白化层和Dropout残差结构的设计思路、原理和作用。
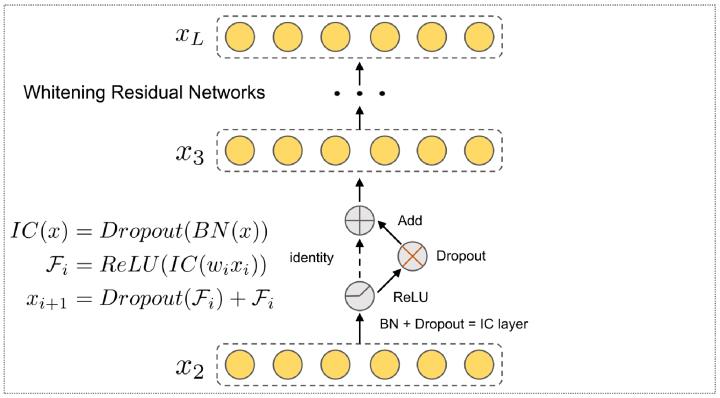 深度白化残差网络结构
深度白化残差网络结构
① 白化层(IC层)
由于前面数据分析时发现输入的数据特征冗余较多,所以我们要考虑设计一个可以消除数据冗余的网络结构,如果不是流计算,平时批处理一般都是直接用 PCA 做特征去相关性,但是考虑到线上环境比较难实现预处理,就思考能不能将这个操作内置到模型中,查阅大量文献后发现 IC 层就可以实现这个功能。
白化层(IC层)中的 IC 源于独立成分分析(Independent Component Analysis)[4] 中前两个单词首字母的缩写。
独立成分分析(ICA)起源于“鸡尾酒会问题”,在嘈杂的鸡尾酒会上,许多人在同时交谈,可能还有背景音乐,但人耳却能准确而清晰的听到对方的话语。这种可以从混合声音中选择自己感兴趣的声音而忽略其他声音的现象称为“鸡尾酒会效应”。ICA 就是从盲源分离技术发展而来的一种数据驱动的信号处理方法,是一种基于高阶统计特性的分析方法。它利用统计原理,通过线性变换把数据或信号分离成统计独立的非高斯的信号源的线性组合[5]。
简而言之,ICA 就是用来降噪的。
要注意到的一点就是,ICA白化前需要做预处理,对输入数据做标准化。在传统用法里,ICA白化的计算量很大,但如今已经出现了很多内置在深度学习框架里被深度优化过的操作,比如 BatchNorm 和 Dropout,计算量很小,能否用这些操作替代或近似ICA白化呢?有研究团队就发现 BatchNorm+Dropout 可以实现近似 ICA 的效果[6]。本次比赛没有完全照搬论文,代码实现大概就是下面这样。
deep = Dense(units, use_bias=False)(deep)
deep = BatchNormalization()(deep)
deep = Dropout(deep_dropout_rate)(deep)下面分别解释一下 BatchNorm 和 Dropout 这两个操作的用法。
① BatchNorm 使得输入变量具有零均值和单位方差[7],这恰好就和白化前的标准化一样,可以将其替换掉白化前的预处理操作。
② Dropout 以某个概率随机失活部分神经元[8]。对于 BatchNorm 后高斯分布下的数据,独立性和不相关性互为充要条件,去相关就等价于独立,而 Dropout 可以消除特征间的相关性,使得输入神经元的数据是统计独立的,学习这些特征的各神经元在统计上也变得彼此独立。
经过以上分析,BatchNorm+Dropout组合后就得到的 IC层就可以近似 ICA 白化。
以一个神经科学研究得出的结论作为理论基础,神经网络的表达能力随独立神经元的数量增加而线性增加[9],由此可知,使用 IC层的神经网络的表达能力会随着独立神经元的数量增多而提高。
与此同时,BatchNorm 和 Dropout 都有缓解过拟合的作用,BatchNorm 还有加速收敛、防止梯度弥散等作用。
② Dropout 残差结构
这里的残差没有用标准的残差结构,只是借鉴了残差思想,说成是 Dropout Ensemble 也行,将通过IC层后的特征向量再次进行一次 Dropout,和原来的输入(恒等映射)进行简单的 Add 操作。
deep = ReLU()(deep)
deep_res = Dropout(deep_dropout_rate)(deep)
deep = add([deep_res, deep])当时设计网络时没有考虑太多,只想着尽量保证模型复杂度和MLP一致的情况下提高模型泛化,其实后面实验时发现,如果把IC层加进标准的残差单元里,虽然参数量会翻倍,但效果会好上不少。
对于kaiming大神的 ResNet[10]大家众说纷纭,我们也不能很好的解释其发挥效用的真实原因,下面是直觉上我们认为 Dropout 残差结构发挥的作用:
在残差单元内使用 Dropout,进一步提高各神经元的独立性,增强模型表达能力。
残差相加的操作类似于模型内的集成学习[11],可以提高模型鲁棒性。
显式修改网络结构,加入残差通路,让网络更容易学习到恒等映射[12],模型更容易训练,同时确保模型效果不会因网络变深而越来越差。
最后,组合白化层和 Dropout 残差结构就得到了我们设计的深度白化残差网络,实现简单且性能强劲。

线下消融实验
因为当时我们提前发现了线上环境第一阶段推理进程不结束的问题,给官方反映了 issue ,这个被问题解决后又出现了新问题,恰好那时我们俩都比较忙,没剩多少时间改了,所以直接不考虑第二阶段了。
这里MLP的隐层设置为[256,128,32,8],可以发现在原始的4层MLP上增加IC层和Dropout残差结构,在参数量和计算量几乎没变的情况下,分数都有很大提升。

2.2.4 训练策略优化
因为数据量比较少,针对类别不平衡问题,我们优先考虑在损失函数上下功夫,对于时间限制等问题考虑使用更高效的训练方式和定制化的训练配置。
Focal loss + 自适应学习率衰减
一开始尝试过直接调交叉熵的 Class weight,也有一点效果,但是当我们尝试使用 Focal loss 后发现,模型验证阶段的 Precision 一下子就提了上来。也尝试过 Combo loss,就是把各种 Loss 加在一起,发现调各个 Loss 的权重十分麻烦,所以后面一直都是用的固定参数的 Focal loss。
import tensorflow.keras.backend as K
from tensorflow.keras.losses import binary_crossentropy
def FocalLoss(y_true, y_pred, alpha=0.75, gamma=2.0):
BCE = binary_crossentropy(y_true, y_pred)
BCE_EXP = K.exp(-BCE)
focal_loss = K.mean(alpha * K.pow((1-BCE_EXP), gamma) * BCE)
return focal_loss自适应学习率衰减就是callbacks里的这个ReduceLROnPlateau,监控的指标变化不大时,到指定轮数,调度器就会把学习率乘一个衰减系数,这里是直接减半了。
from tensorflow.keras.callbacks import ReduceLROnPlateau
ReduceLROnPlateau(monitor='val_loss', factor=0.5,patience=6, verbose=1, mode='auto',epsilon=1e-6, cooldown=1, min_lr=1e-7)在模型训练前期,使用较大学习率可以加速模型收敛,在后期,使用小学习率在小批量训练情况下容易发挥 Focal loss 的作用,明显提高模型精确度。Focal loss使得网络不会被大量的负例带偏,自适应学习率衰减可以保证训练时长合适,不会一直在一个鞍点打转,训练更高效。
交叉训练
数据集去重后打乱并对半划分,训练集和验证集交叉使用,第一次训练结束后,加载最佳模型,使用验证集再继续训练。
说实话,这个比较玄学...我们的理解是,这种训练方式可以充分利用已有标签数据,数据利用最大化的同时防止模型过拟合,提高模型泛化能力。具体用法可以看 Github。
自定义回调函数
实现了自定义保存 checkpoint 的开始轮数、停止训练的最大轮数和最长时间等功能,结合合适的自适应学习率早停可以省下更多时间,确保线上训练不超时。具体实现可以看 Github。
2.3 工程优化
第三大方向是工程优化,包括推理前 Warm-up 和工程简化,保证安全的同时尽量降低推理延迟。
工程分析
因为在排行榜中发现好多人虽然第一阶段延迟分没有满分,但是第二阶段居然一直是满分,所以我们尝试探究其中的原因,debug 过程中发现,在复赛基础镜像版本中,Cluster serving 在进行第一次推理的时候,CPU的内核级进程占用会非常高,在htop中会体现出半红半绿的情况,其中,红色表示内核级进程,绿色表示用户级。
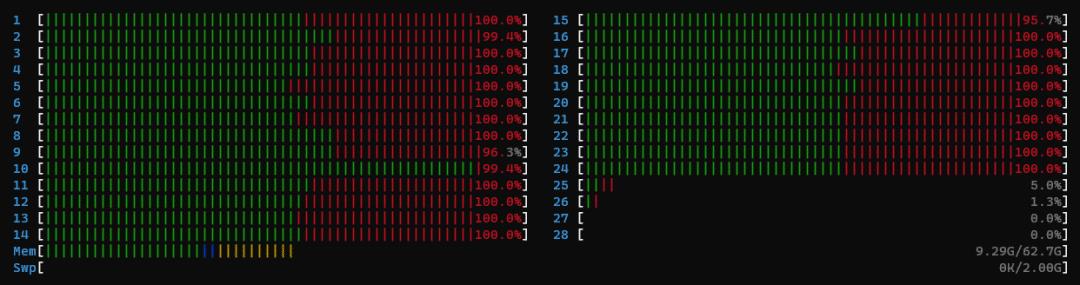 第一阶段进程占用
第一阶段进程占用

第二阶段进程占用
第一阶段,kernel级的进程占用率大概是一半,然而在第二次推理的时候,绿色条会占满,几乎都是用户级进程。对比两个阶段的推理延迟我们发现,第二阶段的推理延迟比第一阶段低非常多。所以我们怀疑基础版本镜像中的第一阶段的 Cluster serving 只用了CPU一半的算力(绿色部分),另一半的内核级进程(红色部分)在处理其他任务。
经过上面的分析,可以明确的一点就是,如果在第一阶段前再加一个“第零阶段”,也就是 Warm-up,可以让工作流在进入第一阶段推理时用户级进程占用处于“满血”状态,最大化 Cluster serving 的性能。
推理前 Warm-up
由于要保证数据安全,我们不能提前读取赛方提供的数据,于是我们通过构造2w条随机数据来模拟数据流,提前触发推理模型部署,预热 Flink 的推理进程以实现线上推理能够发挥出CPU的性能极致。
至于为什么是2w条而不是2k条,我们也是将延迟可视化后发现的,如果只用很少的数据去预热,第一阶段正式推理时会有一部分数据超时,而用2w条就好很多,线下实验了几次之后才决定使用2w条数据预热,可以保证第一阶段不会出现延迟超时。
用尽量更少的数据,花更少的时间去预热。

充分预热后的两个阶段延迟情况
具体做法就是直接把官方提供的 workflow_utils.py 复制一份命名为 warmup_util.py,改一改里面的 push_kafka 函数,在 run_bash.sh 里加上一行去调用它。预热时push速度比第一阶段稍慢,以防止 Flink 消费不掉 Kafka 生产的消息,一直都压不下去,具体实现可以看 Github。
/opt/python-occlum/bin/python3.7 warmup_util.py --server localhost:9092 --input_topic tianchi_input_$time --output_topic tianchi_output_$time工程简化
工程简化,其实就是弃用在线特征工程。因为在写 FlinkSQL 做滑窗统计特征时发现,虽然新特征能有效涨点,但 Warm-up 后居然延迟分不能拿满,可能由于 Flink 水位线机制的存在或者其他什么原因,暂时还没有深挖。经多次尝试后,我们决定在数据和工程上做权衡,简化工程,降低难度,避免FlinkSQL在实时数据流上做特征工程时带来的延迟影响。
流量压力测试

我们使用DeepWRN在线下用比线上稍差的测评环境(线上环境的第三代 Intel® CPU是有深度学习算子加速优化的),做了多次压力测试实验,通过调整 Kafka 发送数据流的间隔来模拟不同大小的流量,表格中第一行是线上的测评结果,其余的是线下的测评结果,多次结果取平均后绘制成柱状图。
线下非 Occlum 环境下,当 Kafka 发送数据的时间间隔为4ms时,预热后可以保证平均延迟仅3ms,而当发送时间间隔降到原来的20倍时,仍然可以全部通过。线上 Occlum 环境下,实测也全部通过,平均延迟仅14ms。说明我们的模型足够简单,预热策略也足够好,可以承受更大的流量。
2.4 总工作流

经过上面各种策略一套下来,总的工作流就是:
在第一阶段训练前,通过黑白名单扩充数据,然后去重,交叉训练,得到并保存最佳模型,搜索最佳阈值后更新模型,然后冻结成pb文件供 Cluster Serving 调用;
在第一阶段推理前,用自己构造的随机数据通过 Kafka 来模拟数据流提前触发 Flink,对 Cluster Serving 进行预热,之后再进入第一阶段做正式推理;
第二阶段也是重复第一阶段的操作,更新黑白名单,限时继续训练并推理,因为暂时没解决第二阶段的问题,所以不预热,直接推理。
总结、思考与改进

曾经尝试但弃用的思路
前面一直在关注让模型更快更小更容易落地,但实际上我们尝试过很多思路,结果都不太好才妥协到现在的方案。
一个是特征工程+伪标签的思路。
初赛时,完全按照传统数据挖掘题来做,针对业务背景和数据特点做了细致的特征工程,第一次接触 Flink,然后发现 FlinkSQL 不懂实现,就放弃了,复赛时不想浪费之前仔细挖掘的特征,打算回收再利用。
先是特征工程后训练树模型,给无标签样本根据置信度打上伪标签,再做有监督学习,由于线上用的是CPU,训练时间太长了,而且 Occlum 会莫名卡住,接着就考虑用深度学习模型给它自己打标签,感觉效果不太好,又浪费时间,就战略性放弃了。
再就是去学了下 FlinkSQL,考虑做一些简单的滑窗特征,结果在线下没开 Occlum 的情况下,Warm-up 之后延迟还是很大,就又战略性放弃了。
另一个是表征学习的思路。
对历史交互序列做 Embedding 或者构建二部图做 Embedding,但为了避免线上 Occlum 环境引入 bug,用的一直是 TF1,得到 Embedding 要一段时间,构建 vlookup 表会特别久,模型参数量会剧增,存在模型参数量过大而加载十分缓慢的问题,就弃用了。(可能是我们embedding的打开方式不对?)
最后答辩发现大家的模型其实差不多都是MLP,应该是尝试过各种模型却发现都没有MLP效果好才这样做的,中途我们尝试过推荐系统里的CTR模型还有一些异常检测的模型,一些最近比较火的对比学习、半监督学习、多任务学习用TF1实现比较麻烦,时间也比较紧就没用,总之很多模型的效果都一般,甚至不如MLP,由于复赛没剩几天时间了就放弃探索,与其套用各种fancy的网络结构,不如直接在MLP上慢慢叠buff。
改进方向
竞赛后续:
尝试用GNN之类的半监督图算法
图建模实现反欺诈图算法(如 FRAUDAR[13]、RICD[14] 等),离线扩充数据再做有监督学习
BTW,RICD[14]就是本次赛题出处的论文,有点像标签传播,可以再仔细看一下。
真实业务:
可以考虑做更细致的数据埋点和特征挖掘提高数据质量
引入联邦学习、知识图谱等技术扩充数据样本或特征
Flink AI Flow 和 Occlum 配适图深度学习框架或图计算框架,优化大规模图的实时构建和处理流程
一些感想
和队友合得来真的很重要,虽然我俩时间上都有冲突,各种DDL,一边是实验室导师的连环push,一边是秋招接连不断的笔试面试,但是,不到最后一天DDL战士绝不认输!工程和算法互补完成最后逆袭。
深刻理解数据和模型原理真的很重要,如果一开始就选定合适的最终模型,后面就可以直接调参上分了,不至于像这次这样一顿乱套各种模型,最后一天的下午才开始调参。
想当算法工程师,工程能力必不可少,算法再吊炸天,工程上遇到问题不会debug,代码都提交不上,前面全是白费,很多人估计在工程这一步给拒之门外,是困难也是机遇,其他人退缩的同时也让给了我们更多的机会。
碎碎念
从9月到12月,慢慢爬到 rank 2/4537,能苟到这个成绩还蛮意外的,其实自己那时候还是一个刚接触竞赛没多久的风控小白(其实想着考研来着呜呜呜我这个菜鸡),一切只因 Datawhale 开源分享的 baseline 进的坑,后面抱着学习的心态边秋招边打比赛,最终拿到了反欺诈方向的offer,也拿到了这个风控比赛的亚军,十分感谢这段时间里给力队友的无缝协作、老师的支持帮助和工作人员的无私解答。
参考
[1] Analytics Zoo Github Repo https://github.com/intel-analytics/analytics-zoo[2] Flink AI Flow Github Wiki https://github.com/flink-extended/dl-on-flink/wiki
[3] Occlum Github Repo https://github.com/occlum/occlum
[4] Oja, H. and Nordhausen, K. "Independent component analysis." Encyclopedia of Environmetrics, 2006.
[5] 线性特征降维——ICA https://leoncuhk.gitbooks.io/feature-engineering/content/feature-extracting04.html
[6] Chen, G. , et al. "Rethinking the Usage of Batch Normalization and Dropout in the Training of Deep Neural Networks." arXiv, 2019.
[7] Ioffe, Sergey , et al. "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift." JMLR, 2015.
[8] Srivastava, Nitish , et al. "Dropout: a simple way to prevent neural networks from overfitting." JMLR, 2014.
[9] Moreno-Bote, et al. "Information-limiting correlations." Nature neuroscience, 2014.
[10] He, K. , et al. "Deep Residual Learning for Image Recognition." CVPR, 2016.
[11] Veit A , et al. "Residual Networks Behave Like Ensembles of Relatively Shallow Networks." NeurIPS, 2016.
[12] He, K. , et al. "Identity Mappings in Deep Residual Networks." ECCV, 2016.
[13] Hooi, Bryan , et al. "FRAUDAR: Bounding Graph Fraud in the Face of Camouflage." KDD, 2016.[14] Li J, Li Z, Huang J, et al. "Large-scale Fake Click Detection for E-commerce Recommendation Systems." ICDE, 2021.

整理不易,点赞三连↓
以上是关于电商风控赛事亚军方案分享!的主要内容,如果未能解决你的问题,请参考以下文章