python——字符编码
Posted 不想秃头的晨晨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python——字符编码相关的知识,希望对你有一定的参考价值。
python——字符编码

字符编码
字符编码简介
由于计算机内部只识别二进制,但是用户(全球人类)在使用计算机的时候可以看到各式各样的语言,所以这中间必须对不同语言进行‘翻译’,计算机才能识别,这个翻译的标准就是字符编码表,数字和字符一一对应。
‘翻译’过程
- 用户 → 计算机 → 用户
**字符 → 数字 (01二进制)→ 字符**
字符串编码发展史
👉[ASCII](ASCII_百度百科 (baidu.com)
1.ASCII码
计算机最初是由美国人发明的,美国人为了能狗让计算机识别英文字符,发明了ASCII码,里面记录了英文与数字对应关系。如下图:
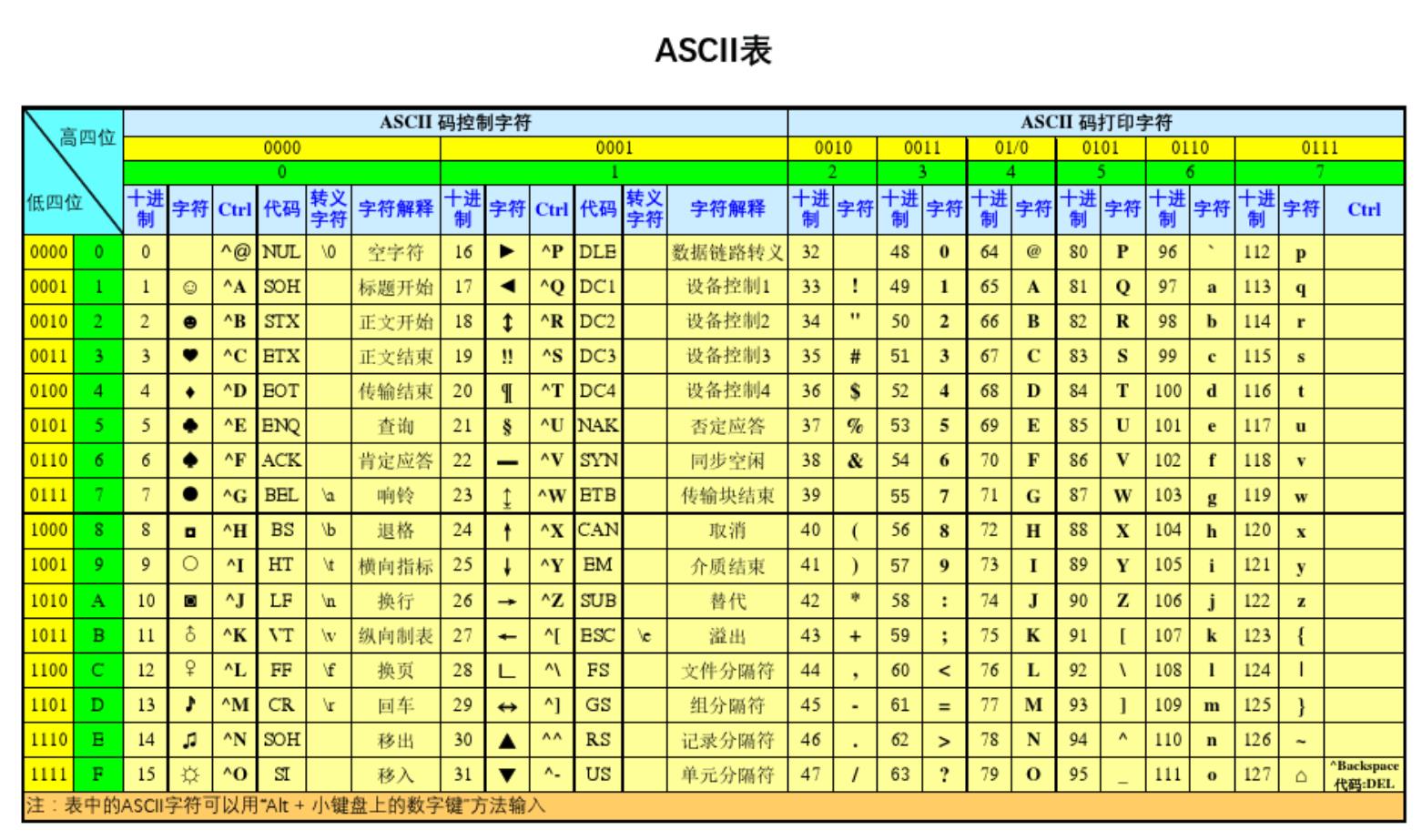
- 所由英文字符和符号加起来不超过127个
- 使用八位表示是为了后续发现新的语言
字符对应关系
- A-Z:65-90
- a-z:97-122
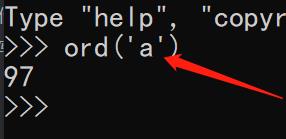
在python中,用ord()方法查看字符对应的数字(十进制)
2.汉字编码 ——GBK
为了让计算机能够识别中文,发明了另外一套编码,GBK
GBK编码表记录了中文英文与数字的对应关系。
- GBK对于英文使用一个字节
- GBK对于中文使用两个甚至更多字节
注:比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号,所以两个字节其实也不够表示出所有的中文,遇到生僻字可能需要更多位来表示。
3.日文编码 ——Shift_JIS
为了让计算机能够识别日文,也需要发明一套编码表,
Shift_JIS编码表记录了日文英文与数字的对应关系。
4.韩文编码 ——EUC-KR
为了能够让计算机识别韩文,需要发明一套编码表,
EUC_KR编码表记录了韩文英文与数字的对应关系。
5.万国码 ——Unicode
Unicode简介
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、TF-16、UTF-32都是将数字转换到程序数据的编码方案,统一使用两个及以上字符记录字符与数字的对应关系。
UTF-8
UTF-8为万国码的优化版本,将英文用一个字节存储,将中文用三个字节或更多版本存储。我们默认使用的编码为UTF-8。
字符编码实操
1、如何解决乱码的情况
#文件当初以什么标准编码,打开的时候就以什么标准解码
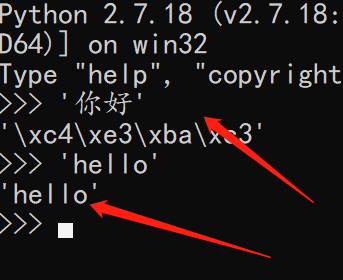
2、python解释器版本不同带来的编码差异
- 由于Python2.X比Unicode发明早,所以内部默认使用ASCII
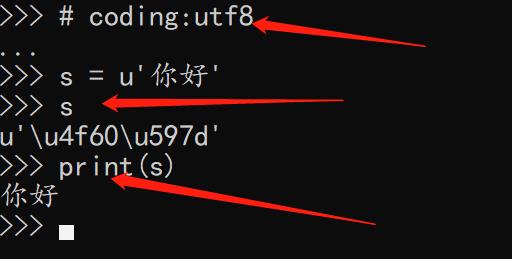
3、在使用python2.x编程时,必须加上文件头。如果定义字符串需要在字符串前加一个小u。
4、python3.X内部使用的是utf-8
5、在pycharm中如何定义文件头模板(python2版本可用)
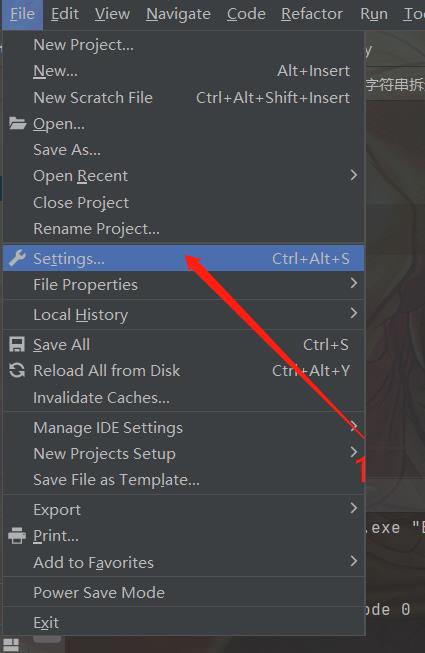
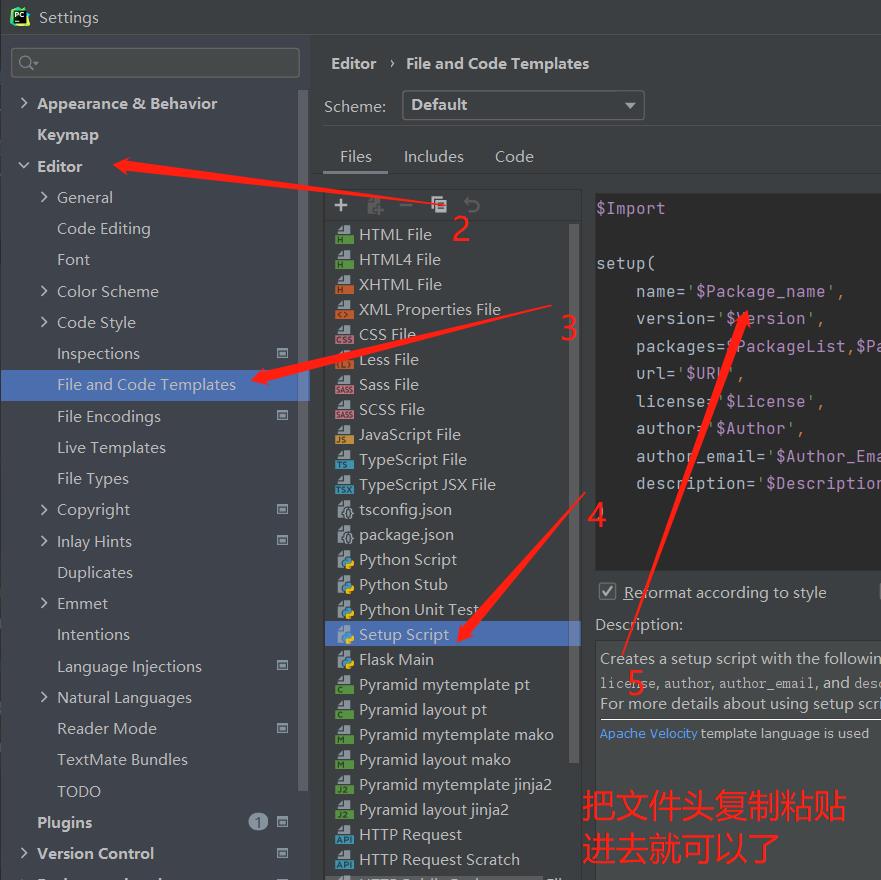
步骤:file>>settings>>Editor>>file and code templates >>python script
代码演练
- 编码与解码的过程
- encode-编码:将人类能够读懂的字符转换成数字
- decode-解码:将数字转换成人类能够读懂的字符
实例如下:
s = '我要坚持学python!'
#编码
res = s.encode('utf8')
print(res,type(res))
#解码
res1 = res.decode('utf8')
print(res1,type(res1))
#结果
b'\\xe6\\x88\\x91\\xe8\\xa6\\x81\\xe5\\x9d\\x9a\\xe6\\x8c\\x81\\xe5\\xad\\xa6python\\xef\\xbc\\x81' <class 'bytes'>
我要坚持学python! <class 'str'>

最后,感谢您的阅读。您的每个点赞、留言、分享都是对我们最大的鼓励,笔芯~
如有疑问,欢迎在评论区一起讨论!
以上是关于python——字符编码的主要内容,如果未能解决你的问题,请参考以下文章