Spark统计每天新增用户
Posted 我爱让机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark统计每天新增用户相关的知识,希望对你有一定的参考价值。
题目要求对已给出的数据使用Spark统计每天的新增的用户。
数据如下:
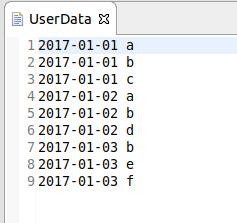
我的思路是:先对数据使用sortByKey算子按照日期进行排序,然后将<日期,用户名>的键值对,键和值的位置互换,即变成<用户名,日期>的键值对,然后使用reduceByKey只保留每个用户名出现的第一条数据(因为一开始已经按照日期对数据进行排序)。最后将<用户名,日期>的键值对互换回去,然后使用groupByKey按照日期进行分组,最后再用sortByKey按照日期排序再输出即可。
代码如下
SparkConf sparkconf = new SparkConf().
setAppName(" ").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(sparkconf);
JavaRDD<String> lines = sc.textFile("文件路径");//原始数据文件路径
JavaPairRDD<String,String>firstClean = lines.mapToPair(f->
return new Tuple2<>(f.split(" ")[0],f.split(" ")[1]);
);//创建键值对
JavaPairRDD<String,String> rdd = firstClean.sortByKey();//按照日期排序
JavaPairRDD<String,String>rdd2 = rdd.mapToPair(f->
return new Tuple2<>(f._2,f._1);
);//键值对位置互换生成新的键值对
JavaPairRDD<String,String> rdd3 = rdd2.reduceByKey((x,y)-> x);//保留用户名出现的第一条数据
JavaPairRDD<String,String>rdd4 = rdd3.mapToPair(f->
return new Tuple2<>(f._2,f._1);
);//键值对位置互换
JavaPairRDD<String, Iterable<String>> rdd5 = rdd4.groupByKey();//按照日期进行分组
JavaPairRDD<String, Iterable<String>> rdd6 = rdd5.sortByKey();//按照日期排序
rdd6.foreach(x -> System.out.println(x));//输出数据变化过程:
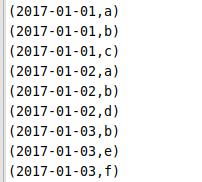





同时我也自己生成了数据进行一个数据清洗的过程,最后我没有使用那个数据,但是大致流程也是一样的。
数据生成代码如下:
public class GenerateData
public static void main(String[] args) throws IOException
// TODO Auto-generated method stub
Random r = new Random();
FileWriter fw = new FileWriter("生成的数据存放的位置及其名称");
int x = r.nextInt(1100000)-100000;//生成的数据范围
for(int y = 1;y <= x;y++)
int year = r.nextInt(7)+2015;//年份15-21
int month = r.nextInt(13);//月份0-12
int day = r.nextInt(32);//日期0-31
int n = r.nextInt(10);//用户名长度0-10
String username = getRandomString(n);
System.out.println(username);
fw.write(y + " " + year + "-" + month + "-" + day + " "+ username + "\\r\\n" );
fw.flush();//刷新缓冲区
/*随机生成字符*/
public static String getRandomString(int length)
String str="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Random random=new Random();
StringBuffer sb=new StringBuffer();
for(int i=0;i<length;i++)
int number=random.nextInt(62);
sb.append(str.charAt(number));
return sb.toString();
生成数据如下:

因为前面生成数据时不够严谨,生成的数据有些问题。比如用户名缺失,0月份,0日期,每个月都有31日这种问题,所以只有用Spark来数据清洗了。
代码如下:
SparkConf sparkconf = new SparkConf().
setAppName(" ").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(sparkconf);
JavaRDD<String> lines = sc.textFile("数据路径");
JavaRDD<String> firstClean1 = lines.filter(f->
return Findnull(f);
);//过滤掉用户名缺失的数据
JavaPairRDD<String,String>firstClean2 = firstClean1.mapToPair(f->
return new Tuple2<>(f.split(" ")[1],f.split(" ")[2]);
);
long counts = firstClean2.count();//统计还剩多少条数据
JavaPairRDD<Tuple2<Tuple2<Integer,Integer>,Integer>, String> secondClean1 = firstClean2.mapToPair( f ->
return new Tuple2<Tuple2<Tuple2<Integer,Integer>,Integer>, String>(
new Tuple2<Tuple2<Integer,Integer>,Integer>(
new Tuple2<Integer, Integer>(Integer.valueOf(f._1.split("-")[1]),Integer.valueOf(f._1.split("-")[2])),
Integer.valueOf(f._1.split("-")[0])),f._2);
);//键值对疯狂套娃hhh,变成<<<月,日>,年>,用户名> 形式的键值对,这样就能对日期比较好操作
JavaPairRDD<Tuple2<Tuple2<Integer,Integer>,Integer>, String> secondClean2 =
secondClean1.filter(f ->
if(f._1._1._1() != 0)
if(f._1._1._2() != 0)
return true;
return false;
);//过滤调月份和日期为0的数据
JavaPairRDD<Tuple2<Tuple2<Integer,Integer>,Integer>, String> secondClean3 =
secondClean2.filter(f ->
if (f._1._1._1()<=7) //月份小于等于7时
if (f._1._1._1()%2==0 && f._1._1._1() !=2 )
if (f._1._1._2() != 31) //过滤掉偶数月的31日
return true;
else if(f._1._1._1() == 2 ) //月份为2时
if(f._1._2()%4==0&&f._1._2()%100!=0||f._1._2()%400==0) //根据闰年平年判断2月是否保留29日
if (f._1._1._2() != 30 && f._1._1._2() != 31 && f._1._1._2() != 0)
return true;
else
if (f._1._1._2() != 30 && f._1._1._2() != 31 && f._1._1._2() != 29 && f._1._1._2() != 0)
return true;
else
return true;
else //月份大于7时
if (f._1._1._1()%2==1)
if (f._1._1._2() != 31 ) //过滤奇数月的31日
return true;
else
return true;
return false;
);
long counts2 = secondClean3.count();过滤第三列为空值的数据方法:
public static Boolean Findnull(String a) throws Exception
// TODO Auto-generated method stub
String []arr = a.split(" ");
String x = arr[0];
String y = arr[1];
try
String z = arr[2];
catch(Exception e)
return false;
return true;
闲着无聊又写了一个数据查询的代码,当然要把数据套娃成<<<月,日>,年>,用户名>才可以用。(这一段代码本来不是接在刚才的代码上的,所以参数名有点不一样,将其修改即可)
Scanner A = new Scanner(System.in);
System.out.println("请输入需要查询的日期:");
System.out.println("请输入年份:");
int year = A.nextInt();
System.out.println("请输入月份:");
int month = A.nextInt();
System.out.println("请输入日期:");
int day = A.nextInt();
JavaPairRDD<Tuple2<Tuple2<Integer,Integer>,Integer>, Iterable<String>> secondClean3 =
secondClean2.filter(f ->
if (month<13&&month>0)
if(day<32&&day>0)
if (f._1._2()==year && f._1._1._1()==month && f._1._1._2()==day)
return true;
else
return false;
else
if (f._1._2()==year && f._1._1._1()==month)
return true;
else
return false;
else
if (f._1._2()==year)
return true;
else
return false;
);
secondClean3.foreach(x -> System.out.println(x));
System.out.println("是否需要保存?(保存请输入“1”)");
int x = A.nextInt();
if (x == 1)
System.out.println("请输入新建的文件夹名:");
String add = A.next();
secondClean3.saveAsTextFile("\\""+add+"\\"");
不足之处欢迎指正。hhh
以上是关于Spark统计每天新增用户的主要内容,如果未能解决你的问题,请参考以下文章