Hyperledger Fabric学习笔记2——超级账本介绍
Posted zqq_2016
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hyperledger Fabric学习笔记2——超级账本介绍相关的知识,希望对你有一定的参考价值。
目录
1. 超级账本介绍
1.1 超级账本简介
超级账本是推动区块链跨行业应用的开源项目的总称,组织成员可以发起新的区块链项目,加
入超级账本项目中,但需要遵循超级账本的生命周期。
超级账本的生命周期分为5个阶段,分别为Proposal(提案)、lncubation(孵化)、Active
(活跃)、Deprecated(过时)、End of Life(结束)。
超级整本的整个生命周期的过程:成员发起新项目时,1)首先发起者撰写草案,草案内容包括
实现的目标、开发过程、代码维护等信息;然后提交给技术指导委员会进行审核,该阶段为提案阶段;
技术指导委员会有三分之二以上代表通过后,则进入孵化阶段;2)在孵化阶段将对项目进行开发、
测试,直到项目完成;3)项目参与者对该项目如果没有疑问,项目将进入活跃阶段;4)经过几年时
间后,随着技术的进步,该项目跟不上时代,将进入过时阶段;5)最后被淘汰,整个生命周期结束。1.2 超级账本组织
超级账本组织分为技术指导委员会(TSC)、董事会(Governing Board)、工作人员
(LF Staffs)三个组织。
1)技术指导委员会:主导社区的开发工作,下设多个工作组,每个工作组负责具体的项目开发;
2)董事会:负责决策社区的所有事务,对社区成员负责;
3)工作人员:为社区提供服务。
Linux基金会通过票选机制,选举出组织的技术指导委员会主席、董事会主席等关键领导角色,
同时公布了10名技术指导委员会成员,以及13名董事会成员。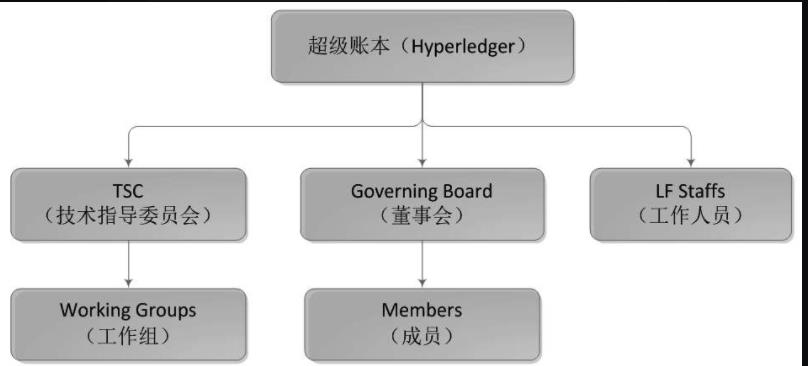
1.3 超级账本项目(重点介绍Fabric)
超级账本项目分框架类(包括:Hyperledger Fabric)和工具类两类。
Hyperledger Fabric:是最早加入超级账本项目中的顶级项目,包括Fabric、Fabric CA、
Fabric SDK(包括Node.js、Go、Python和Java等语言)和Fabric-API等,其目标是区块链的基础
核心平台,支持PBFT等新的共识机制,支持权限管理。2. Fabric介绍
2.1 Fabric简介
Fabric是一个提供模块化分布式账本解决方案的框架,并具备保密性、可伸缩性、灵活性和可
扩展性等特性。Fabric具有可直接插拔启用、相互独立、功能不同的模块,并能适应经济社会中各
种错综复杂的场景。
Fabric也是超级账本中的一个区块链项目,包含一个账本,使用智能合约,并且是一个通过所
有参与者进行管理交易的系统,它与其他区块链系统最大的不同是使用联盟链。与允许未知身份的
参与者加入网络的公有链不同,Fabric通过成员资格服务提供者(Membership Service
Provider,MSP)来登记所有成员。
Fabric提供了建立通道(Channel)的功能,允许参与者为交易新建一个单独的账本,只有在同
一个通道中的参与者,才会拥有该通道中的账本,而其他不在此通道中的参与者则看不到这个账本,
这种通道隔绝技术带来了更高的安全性,也是Fabric最主要的特点。2.2 Fabric架构
2.2.1 总体架构
Fabric总体架构分为网络层、核心层和接口层。核心层有成员服务(Membership
Services)、区块链服务(Blockchain Services)和链码服务(Chaincode Services)3部
分;接口层通过接口及事件(APIs、Events、SDKs)调用身份(IDENTITY)、账本(LEDGER)、
交易(TRANSACTIONS)、智能合约(SMARTCONTRACT)等信息;网络层负责P2P网络的实现,保
证区块链分布式存储的一致性。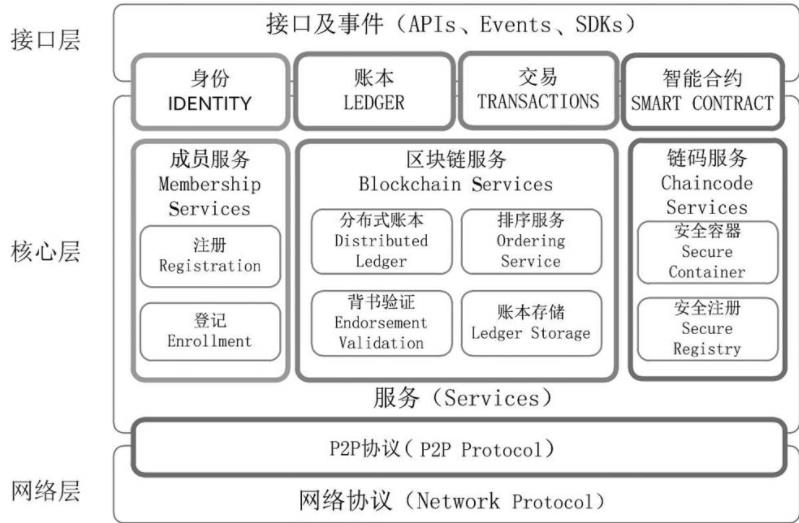
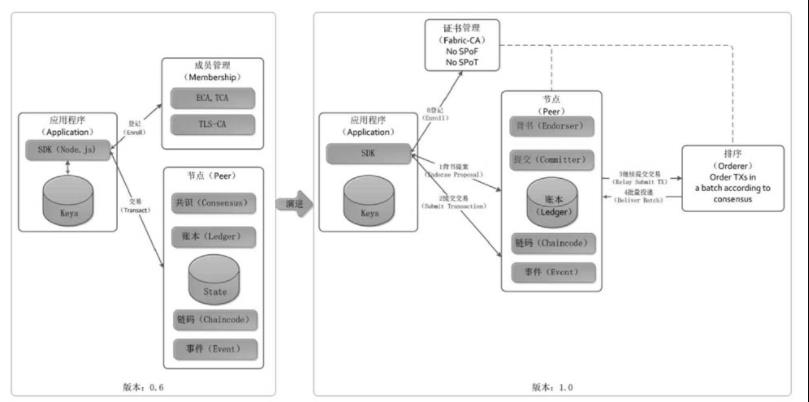
1)成员服务(Membership Services):提供成员服务功能,包括注册、登记、申请证书等功
能。考虑到商业应用对安全、隐私、监管、审计和性能的要求,节点、成员只有获得证书才能加
入区块链网络中,在1.0版本以后单独由可插拔的Fabric CA组件处理。
2)区块链服务(Blockchain Services):负责分布式账本(Distrbuted Ledger)的计算和
存储、节点间的排序服务(Ordering Service)、背书验证管理(Endorsement Validation)
以及账本存储方式(Ledger Storage)等功能的实现,是区块链的核心组成部分,为区块链的
主体功能提供了底层支撑。
3)链码服务(Blockchain Services):负责分布式账本(Distrbuted Ledger)的计算和存
储、节点间的排序服务(Ordering Service)、背书验证管理(Endorsement Validation)
以及账本存储方式(Ledger Storage)等功能的实现,是区块链的核心组成部分,为区块链的
主体功能提供了底层支撑。
4)接口及事件(APIs、Events、SDKs):给第三方应用提供API方式进行调用,方便二次开发,
目前已提供Node.js和Java两种语言接口;可以通过SDK或CLI方式进行安装并测试链码,还可以
实现查询交易状态和数据等功能,同时通过Events监听区块链网络中发生的事件,方便第三方应
用系统调用和处理。
5)网络协议(Network Protocol):实现P2P网络传输,使用gPRC和Gossip协议。2.3 Fabric交易流程
区块链最主要的特性之一是去中心化。没有中心机构的集中处理,又要达成数据的一致性,
就需要网络中全民参与管理,并以某种方法达成共识,所以区块链的交易流程也就是共识的过程。
在Fabric中,本由一个节点处理的过程,在逻辑上被分解为不同的角色,每个角色承担不同
的功能。节点(Peer)分解为背书节点(Endorser Peer)和提交节点(Committer Peer),为了
达到处理的顺序性,提炼出排序(Orderer)角色。
Fabric应用于联盟链的场景,在处理每一笔交易时,每个环节都需要对交易信息进行权限校验。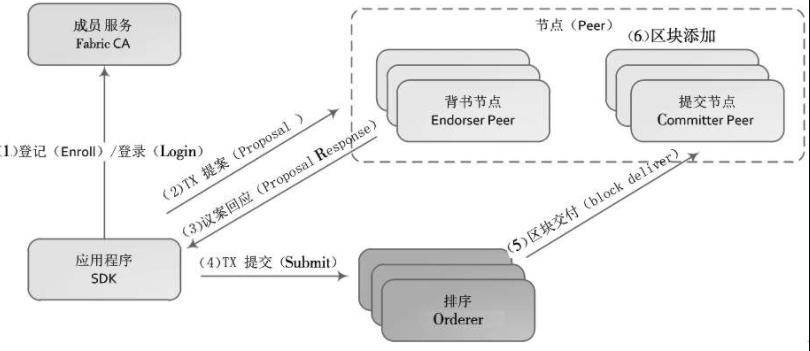
交易的详细流程如下:
1)应用程序客户端通过SDK调用成员服务,进行注册和登记,并获取身份证书。
2)应用程序客户端通过SDK向区块链网络发起一个交易提案(Proposal),交易提案把本次
交易要调用的合约标识、合约方法和参数信息以及客户端签名等信息发送给背书节点。
3)背书节点收到交易提案后,验证签名并确定提交者是否有权执行操作,同时根据背书策略
模拟执行智能合约,并将结果及其各自的CA证书签名返回给应用程序客户端。
4)应用程序客户端收到背书节点返回的信息后,判断提案结果是否一致,以及是否参照指定
的背书策略执行。如果没有足够的背书,则中止处理;否则,应用程序客户端把数据打包到一起,
组成一个交易并签名,发送给排序角色。
5)排序角色对接收到的交易进行共识排序,然后按照区块生成策略,将一批交易打包到一起,
生成新的区块,发送给提交节点。
6)提交节点收到区块后,会对区块中的每笔交易进行校验,检查交易依赖的输入输出是否符
合当前区块链的状态,完成后将区块追加到本地的区块链,并修改世界状态(所有键的最新值)。2.4 Fabric关键技术
Fabric的6种关键技术知识点:
1)账本的结构和存储(账本)
2)智能合约的编写和部署(智能合约)
3)通道的操作(通道)
4)节点的背书和提交(节点)
5)排序的共识(排序)
6)客户端SDK的接口调用(接口)2.4.1 账本
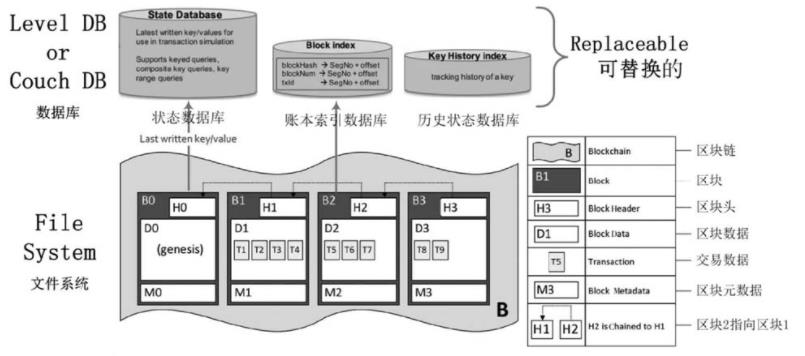
(1)区块链
区块链(Blockchain)基于本地文件系统,将区块存储于文件系统的硬盘中,每个区块中保存区块
头(Block Header)、区块数据(Block Data)、区块元数据(Block Metadata),通过区块头中前一个区块的哈希值指向前一个区块的当前哈希值,连接成区块链。 (2)状态数据库
状态数据库(State Database)存储在交易中出现的所有键值对的最新值,调用链码执行交易
可以改变状态数据。为了高效地执行链码调用,所有数据的最新值都被存放在状态数据库中;状态数
据库被设计为组件,可以通过配置替换数据库。目前有LevelDB和CouchDB两种数据库,LevelDB是
默认的内置数据库。
LevelDB:适用于简单的键值对场景,LevelDB嵌入在Peer进程中。
CouchDB:适用于支持丰富的查询和数据类型的场景,应用系统作为JSON文档存储时,CouchDB
是一个特别合适的选择,支持对链码数据进行丰富的查询。(3)账本索引数据库
区块链保存在文件系统时,会在LevelDB中存储区块交易对应的文件块及其偏移,也就是将
LevelDB作为账本索引(Block Index)数据库。文件形式的区块存储方式如果没有快速定位的索
引,那么查询区块交易信息会非常慢。(4)历史状态数据库
历史状态(History Index)数据库用于查询某个键的历史修改记录,并不存储键具体的值,
该值只记录在某个区块的某个交易里。当某键变动了一次,后续需要查询的时候,则根据变动历史
去查询实际变动的值,这样虽然减少了数据的存储,但增加了查询逻辑的复杂度。2.4.2 智能合约
智能合约(Smart Contract)又称为链码,是在区块链上运行的一段代码,是应用系统与区块链底层交互的中间件。通过智能合约,区块链可以实现各种复杂的应用。
目前支持使用Go、Java或Node.js语言来开发智能合约,支持最好的还是Go语言。
智能合约安装在Peer上,运行在Docker容器中,通过gRPC与Peer进行数据交互,交互步骤(链码与节点消息交互)如下图:

(1)智能合约调用shim.Start()方法后,给Peer发送ChaincodeMessage_REGISTER消息并尝试进行注册,此时,智能合约和Peer的状态为初识的created。
(2)Peer在收到来自智能合约的ChaincodeMessage_REGISTER消息后,会注册到本地的一个handle结构中,返回ChaincodeMessage_REGISTER消息给智能合约,并且更新状态为established,然后会自动发出ChaincodeMessage_READY消息给智能合约,并且更新状态为ready。
(3)智能合约在收到ChaincodeMessage_REGISTER消息之后,先不进行任何操作,只完成注册步骤,并更新状态为established。在收到ChaincodeMessage_READY消息之后再更新状态为ready。
(4)Peer发送ChaincodeMessage_INIT消息给智能合约,对智能合约进行初始化。
(5)智能合约收到ChaincodeMessage_INIT消息之后,调用用户代码Init()方法进行初始化,成功之后,返回ChaincodeMessage_COMPLETED消息。到此,智能合约就可以被调用了。
(6)智能合约被调用的时候,Peer发送ChaincodeMessage_TRANSACTION消息给链码。
(7)智能合约在收到ChaincodeMessage_TRANSACTION消息之后,会调用Invoke()方法,根据Invoke()方法中用户的逻辑,可以发送如下消息给Peer。

(8)Peer在收到这些消息之后,会做相应处理,并回复ChaincodeMessage_RESPONSE消息。最后,智能合约会回复调用完成的消息ChaincodeMessage_COMPLETE至Peer。
(9)上述消息交互过程完成后,Peer和智能合约会定期给对方发送ChaincodeMessage_KEEPALIVE消息,以确保彼此是在线状态。
2.4.3 通道
通道(Channel)是两个Peer或多个Peer之间消息通信的私有空间,在通道内交易的数据与通道外隔绝,保证通道内数据的安全。在网络上的交易都要在某个通道上执行,参与交易的每个成员都通过身份验证和授权,才能在通道上进行处理。
Fabric是多通道设计,系统可以创建多条通道,一个Peer可以加入不同的通道中,在每个通道中有自身的创世区块和实例化智能合约。
每个通道都有属于自己的锚节点,通过锚节点可以与其他通道进行信息交互,但本身通道内的账本不会通过一个通道传到另一个通道上,通道对于账本是分离的。
如下为通道结构图:

通道结构图的说明:
N:Blockchain Network(区块链网络)
C:Channel(通道)
P:Peer(节点)
S:Chaincode(链码)
L:Ledger(账本)
A:Application(客户端)
PA-C:Principal PA communicates via channel C(客户端A与节点P通过通道C进行通信)
2.4.4 节点
节点(Peer)是区块链交易处理和账本维护的主体,主要负责参与共识过程和通过执行链码实现对账本的读写操作。Peer根据功能不同分为背书节点(Endorser Peer)和提交节点(Committer Peer);根据通信不同分为锚节点(Anchor Peer)和主节点(Leading Peer)。
背书节点:负责根据事先设定策略对交易进行签名背书,在链码实例化的时候设置背书策略,指定哪些节点用于背书。当客户端向节点发起交易背书时,该节点才能有背书功能,否则只是普通的记账节点。
提交节点:负责维护状态数据和账本的副本。
锚节点:锚节点是随通道存在的,是能被其他通道发现的节点,每个通道上有一个或多个锚节点。
主节点:负责与Orderer通信,把共识后的区块传输到其他节点。

应用程序与节点交互流程如下:
(1)connect to peer:应用程序成功连接到Peer后,调用链码向Peer进行提案。
(2)invoke chaincode(proposal):应用程序提交提案给Peer,执行智能合约。Peer根据提案信息调用链码。
① peer invokes chaincode with proposal:Peer根据提案调用智能合约。
② chaincode generates query or update proposal response:智能合约进行查询或更新操作,同时返回提案结果。
(3)proposal response:链码进行查询和更新,然后将提案结果返回给应用程序。
(4)request that transaction is ordered:应用程序将交易信息发送给Orderer。
① transactions sent to peers in blocks:Orderer把含有交易信息的区块发送给其他Peer。
② peer updates ledger using transction blocks:Peer把交易区块更新到账本中。
(5)ledger update event:应用程序接收账本更新事件。Orderer把含有交易信息的区块发送给Peer。
2.4.5 排序
排序(Orderer)指对区块链网络中不同通道产生的交易进行排序,并广播给Peer。Orderer是以可插拔组件的方式实现的,目前分为Solo和Kafka两种类型。
Solo:仅有一个Orderer服务节点负责接收交易信息并进行排序,是最简单的排序算法,一般用于测试环境。
Kafka:是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,可以配置多个排序节点集群方式,以便使用在生产环境中。Hyperledger Fabric利用Kafka高吞吐、低延时的特性,对交易信息进行排序处理,实现集群内部支持节点故障容错。
注意:正式环境中需要使用Kafka搭建,保证数据可靠性和安全性,以下介绍基于Kafka集群和Zookeeper集群的排序服务的原理。
(1)Kafka处理流程如下图:
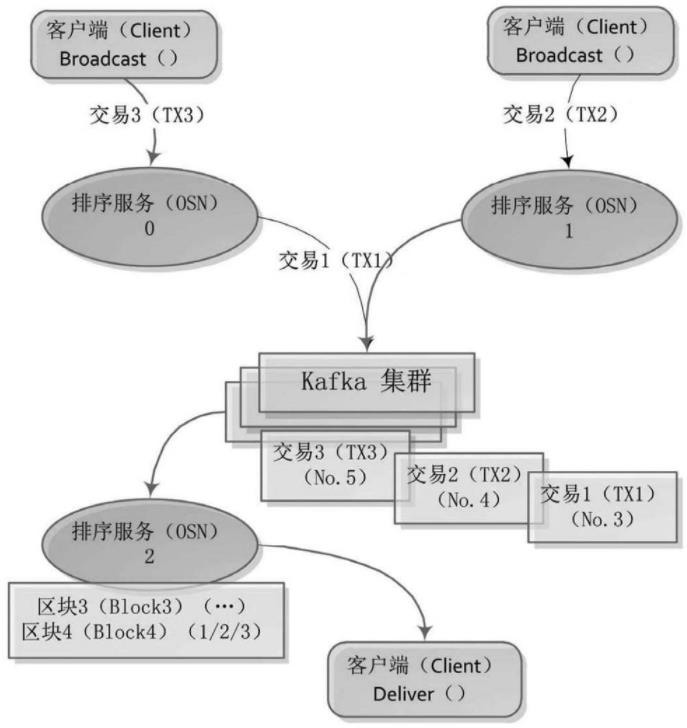
① 排序服务(OSN)1已存在交易1(TX1),并发送到Kafka集群中。
② 客户端(Client)通过Brocadcast(gRPC广播)接口提交交易2(TX2)到排序服务(OSN)1中,随后发送到Kafka集群中。
③ 客户端(Client)通过Brocadcast接口提交交易3(TX3)到排序服务(OSN)0中,随后发送到Kafka集群中。
④ Kafka集群根据交易提交的时间,按序号3~5(No.3至No.5)依次保存三笔交易。
⑤ 客户端(Client)通过(gRPC分发)Deliver接口发送分发请求,从排序服务(OSN)2中获取保存交易1、2、3的区块4(Block4),至此示例流程结束。
(2)Kafka集群和Zookeeper集群的节点数量规定
① Kafka集群节点的最小值为4,是故障容错需要的最小数值。4个Kafka节点使得1个节点崩溃后,所有的通道还可以继续读写且创建通道。
② ZooKeeper可以为3、5或7。它必须是一个奇数以避免分裂(Split-brain)情景,同时选择大于1是为了避免单节点故障,超过7个ZooKeeper节点则是多余的。
(3)排序操作步骤:
① 在网络的创世区块中写入Kafka的相关信息
在生成创世区块时,需要在configtx.yaml文件中配置Kafka的相关信息,如Orderer.OrdererType设置为kafka,Orderer.Kafka.Brokers设置为Kafka集群中的节点IP地址和端口。
② 设置区块最大容量
设置区块最大容量是在configtx.yaml文件中设置Orderer.AbsoluteMaxBytes项的值,以字节为位置,不包括区块头信息大小。
③ 创建创世区块
使用configtxgen工具,根据步骤(1)和步骤(2)中的配置生成创世区块。
④ 配置Kafka集群
1)设置unclean.leader.election.enable为false;
2)设置min.insync.replicas为M(数字),数据提交时会写入至少M个副本,值的范围为1
3)设置default.replication.factor为N(数字),表示在Kafka节点上每个通道都保存N个副本的数据,值的范围为1
4)设置message.max.bytes值,message.max.bytes值应该严格小于socket.request.max.bytes的值,socket.request.max.bytes的值默认被设置为100MB;
5)设置replica.fetch.max.bytes值,为每个通道获取消息的最大字节数。
6)设置log.retention.ms值为-1,关闭基于时间的日志保留方式。
⑤ 所有排序节点都指向创世区块
在orderer.yaml文件中配置General.GenesisFile参数,让排序节点指向步骤(3)中创建的初始区块。
⑥ 调整轮询间隔和超时时间
在orderer.yaml文件中配置Kafka.Retry参数,调整metadata/producer/consumer请求的频率以及Socket的超时时间。
⑦ 设置排序节点和Kafka集群间为SSL 通信
在orderer.yaml文件中配置Kafka.TLS参数,确定是否通过TLS(安全传输层协议)进行通信。
⑧ 集群启动顺序
先启动ZooKeeper集群,然后启动Kafka集群,最后启动排序节点。
2.4.6 接口
Fabric提供调用账本、智能合约、通道、节点、排序等接口(SDK),方便第三方应用程序的开发,大大地扩展了Fabric的应用场景。
Hyperledger Fabric提供了许多SDK来支持各种编程语言,目前正式发布了Node.js和Java两种版本的SDK。
Fabric SDK可以为开发人员提供编写应用程序的多种操作区块链网络的方式。应用程序可以部署或执行智能合约、监听网络中产生的事件、接收块信息、把交易存储到账本等。
以上是关于Hyperledger Fabric学习笔记2——超级账本介绍的主要内容,如果未能解决你的问题,请参考以下文章
《HyperLedger Fabric 2.3 联盟链搭建》 课程学习笔记