NeurIPS | 神经网络如何特征外推?
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NeurIPS | 神经网络如何特征外推?相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :上海交通大学Thinklab
本文介绍被NeurIPS21接收的新工作。我们对一个全新的问题在通用的设定下进行了探索,相关问题定义和方法适用于诸多具体应用。论文和代码链接在文末提供。
论文题目:Towards Open-World Feature Extrapolation: An Inductive Graph Learning Approach
作者信息:Qitian Wu, Chenxiao Yang, Junchi Yan (Shanghai Jiao Tong University)
关键词:图神经网络、特征表示学习、分布外泛化
https://www.zhuanzhi.ai/paper/9a5c65152ea2af851fc7cba33aadd014
动机:特征外推问题的定义与重要性
目前的大多数机器学习任务,通常假设训练数据与测试数据共享一个特征空间。然而在实际场景中,训练好的模型通常需要与一个开放环境进行交互,测试集中就会出现新的特征。例如推荐系统中利用用户的年龄、职业等特征训练好了一个推荐模型,后来公司新发布了某个应用,收集到了新的用户数据,这就需要用新的用户特征进行决策。
下图给出了一个直观的说明,我们考虑训练数据与测试数据的特征维度不一致(后者是前者的扩张),在这种情况下如果我们把训练好的神经网络直接迁移到测试集,由于对应新特征维度的神经元未经过训练,网络的测试性能就会大大下降,而重新在包含新特征的数据集上训练一个神经网络又需要耗费大量的计算资源。本篇论文中,我们提出了一种新的学习方法,基于特征与样本之间的关系所形成的图结构,利用已知的特征表示(embedding)来外推新特征的表示,模型无需重新训练就能泛化到包含新特征的数据上。

我们把第个数据样本表示为,其中表示第个特征的one-hot表示向量(离散特征的常见表示形式,连续特征可先做离散化再表示成one-hot向量),这里共有个特征。下面为开放世界特征外推问题(open-world feature extrapolation)给出数学定义:
给定训练数据其中, ,我们需要训练一个分类器使得它能够泛化到测试数据其中, 。注意到,这里我们假设:1)训练集特征空间包含于测试集特征空间,即;2)训练集与测试集共享同一个输出空间。
重要观察
直接解决上述问题是很困难的,因为训练阶段对测试数据中额外增加的特征信息一无所知(包括特征的数目和分布都不可见)。不过我们有两点重要观察,可以引导我们给出一个合理的解决方案。
首先,神经网络分类器可以分解为两个级联的子模块,分别是特征embedding层和classifier层(如下图(a)所示)。这里的embedding层可以视为一个特征embedding字典,每一行是一个特征的embedding,它对输入向量中每一个非0的特征查找出相应的embedding,而后对所有返回的特征embedding做一个sum pooling聚合,得到中间层的hidden vector,用于接下来classifier层的前馈计算。这里的sum pooling操作对于特征维度是置换不变(permutation-invariant)的。所谓置换不变性,就是指当交换输入各元素的位置,输出保持不变。

其次,如果我们把所有输入的数据(比如训练样本)堆叠起来,形成一个矩阵(维度为样本数特征数),它定义了一个样本-特征的二分图。图中每个样本与每个特征都是节点,连边是样本对特征的隶属关系(即该样本是否包含该特征)。

联合以上两点我们可以发现,如果我们把所有输入数据(或一个batch的数据)视为一张图,再输入神经网络,由于网络embedding层的置换不变性,不论输入的图包含多少特征节点,网络都能灵活处理。这就说明我们能够适当改造神经网络,使它能够处理特征空间的扩张。
方法
下面介绍本文提出的用于特征外推的模型框架(下图显示了模型的前馈过程)。整个模型框架包含输入的数据表示,一个high-level图神经网络(GNN)模型,和一个low-level的backbone模型。GNN模型用于在样本-特征二分图上进行消息传递,通过抽象的信息聚合来推断新特征的embedding。这一过程模拟了人脑的思考过程,即从熟悉的知识概念外推出对新概念的理解。backbone模型就是一个普通的分类器,不过embedding层的参数将由GNN模型的输出替代。

下图是针对上述模型提出的两种训练策略。图(a)中我们采用self-supervised训练,每次将部分特征mask,然后利用其他特征来推断mask的特征。图(b)中我们采用inductive训练方式,每次采样一部分训练集的特征,只利用这部分特征来给出预测结果。此外,GNN和backbone采用异步更新,即每k轮更新backbone后再更新一次GNN。

理论分析
我们对提出的训练方法做了一番理论分析,主要考虑经验风险损失(即部分观测集上的模型预测误差)与期望风险损失(即整体数据分布上的模型预测误差)关于算法随机性的期望差值。这一差值的上界可以由以下定理给出,结论就是泛化误差上界主要与输入特征维度以及采样算法可能产生的特征组合数目有关。

实验结果
在多/二分类数据集上,我们考虑如下评测准则:随机将数据样本划分为6:2:2的train/val/test集,再随机从所有特征中选出部分观测特征;模型在只有观测特征的训练数据上训练,在具有所有特征的测试数据上计算accuracy(多分类)或ROC-AUC(二分类)。对比以下方法:1)Base-NN只用观测特征训练和测试;2)Oracle-NN:使用全部特征训练和测试;3)Average-NN/KNN-NN/Pooling-NN:使用average pooling聚合所有特征embedding/KNN聚合相近特征embedding/不含参数的mean pooling GCN聚合相邻特征embedding来推断新特征的embedding;4)INL-NN先在仅有观测特征的训练数据上训练到饱和再在新特征上局部更新。在6个小数据集上,考虑不同的观测特征比例(从30%到80%),对比结果如下(图中FATE为本文提出的方法)。

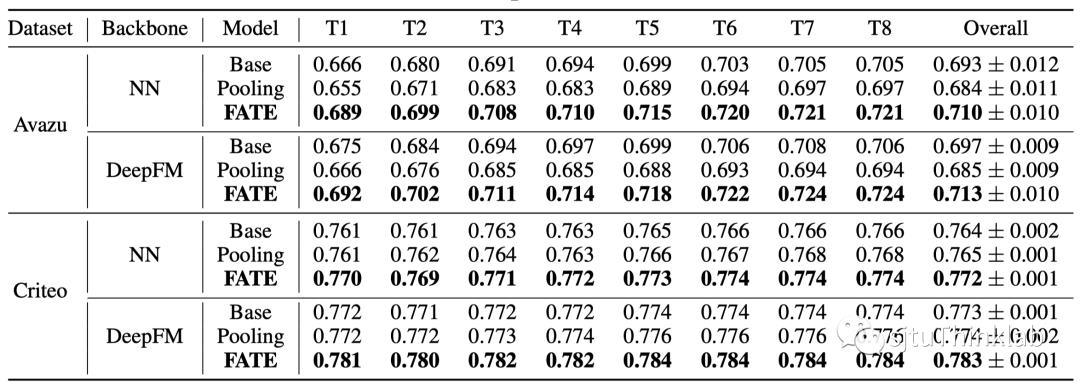
此外,我们还在大规模广告数据集(百万级样本和特征)开展了实验。这里我们采用动态时间划分:将所有样本按时间先后排序,再分为10份,取第一份为训练数据,第二份作为验证集,第三到第十份作为测试集。这样的划分方式天然的在测试集中引入了训练集中未出现的新特征,新旧特征的比例接近1:1。我们分别以DNN和DeepFM作为backbone模型,使用ROC-AUC作为评测指标,结果如下。我们的方法能够取得最优的预测性能。
更多实验结果,例如可扩展性测试(模型的训练计算时间和显存消耗相对于特征数和样本batch size都呈现线性增长趋势)、消融实验、特征可视化结果请参见我们的论文。
更多解释:为什么图学习可以帮助解决外推问题
事实上,当我们利用输入数据将样本与特征表示在一张图上后,通过图结构我们就能得到样本-特征以及特征-特征之间的关系。这里特征-特征的关系由样本作为中间节点,也就是图上的二阶相邻信息给出。基于此,图的建立为我们提供了天然的已观测特征与未观测特征的联系。当模型完成训练后,我们可以得到已观测特征的表示embedding,而后对于在测试阶段引入的新特征,我们就可以利用图结构做信息传递,把已观测特征的embedding信息通过图神经网络计算新特征的embedding,从而实现特征的外推。
未来展望与总结
我们工作的最大贡献在于定义了一个全新的问题框架,即特征空间的外推问题,并且说明了神经网络模型可以胜任此类任务,解决测试阶段新出现的特征。由于本文的重点在于探索一个新的方向,我们采用了较为通用的设定,未来可以对本文的研究问题做进一步的拓展,包括但不限于考虑:
1)持续学习(Continual Learning)中不断到来的新特征;
2)多模态学习(Multi-Modal Learning)或多视角学习(Multi-View Learning)中融合多方数据的表示;
3)联邦学习(Federated Learning)中中心服务器需要处理分布式节点的新特征。此外,本文研究的问题和解决思路也可以被应用到诸多其他领域和场景。欢迎讨论,请发邮件至echo740@sjtu.edu.cn
论文链接:https://proceedings.neurips.cc/paper/2021/file/a1c5aff9679455a233086e26b72b9a06-Paper.pdf
代码链接:https://github.com/qitianwu/FATE
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于NeurIPS | 神经网络如何特征外推?的主要内容,如果未能解决你的问题,请参考以下文章
NeurIPS 2021 Spotlight | 准确快速内存经济,新框架MEST实现边缘设备友好的稀疏训练...
加州伯克利博士:基于隐模型的图神经网络设计 | NeurIPS 2020论文分享
NeurIPS 2021论文接收结果统计:Oral级论文不足3%,图神经网络火到进前三
NeurIPS 2021 Spotlight | 准确快速内存经济,新框架MEST实现边缘设备友好的稀疏训练...