经过七年演进,Serverless流行起来了吗?
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经过七年演进,Serverless流行起来了吗?相关的知识,希望对你有一定的参考价值。
2009 年,加州大学伯克利分校发布了一篇论文《The Berkeley View on Cloud Computing》,正确预测了接下来十年的云计算演进和普及。2019 年,伯克利又发布了一篇有着相同命名风格的论文《A Berkeley View on Serverless Computing》,再次预言未来“无服务器计算将会发展成为未来云计算的主要形式”。无服务器被寄予厚望,但同时也存在一些争议。如今,距离 2014 年 Amazon Lambda 首次发布已有七年时间,我们回头去看,当初那些无服务器的承诺都能兑现了吗?
1.无服务器的承诺和争议
“无服务器”术语最早出现在 2012 年左右的一篇文章里,作者 Ken Fromm 对它的解释是:
“无服务器”一词并不意味着不再涉及服务器,它只是意味着开发人员不再需要考虑那么多的物理容量或其他基础设施资源管理责任。通过消除后端基础设施的复杂性,无服务器让开发人员将注意力从服务器级别转移到任务级别。
虽然不少技术先知认为无服务器架构是“一项重大创新并将很快流行起来”,但这个概念在提出当时并没有得到很好的反响。
真正让无服务器得到广泛关注的事件是亚马逊云科技于 2014 年推出 Amazon Lambda 服务。之后, 随着谷歌和微软等企业的服务进入市场,“无服务器”才逐渐成为行业“热词”。
相较于“传统服务”,无服务器计算的优势主要有几点:
- 在无服务器平台上,无需用户自身去维护操作系统。开发人员只需要编写云函数,选择触发云函数运行的事件就可以完成工作。例如加载一个镜像到云存储中,或者向数据库添加一个很小的图片,让无服务器系统本身来处理其他所有系统管理的操作,如选择实例、部署、容错、监控、日志、安全补丁等等。
- 更好的自动扩缩容方式,理论上能应对突发的从“零”到“无穷大”的需求峰值。有关扩展的决定由云提供商按需提供,开发人员不再需要编写自动扩展策略或定义机器级别资源(CPU、内存等)的使用规则。
- 传统云计算按照预留的资源收费,而无服务器按照函数执行时间收费。这也意味着更加细粒度的管理方式。在无服务器框架上使用资源只需为实际运行时间付费。这与传统云计算收费方式形成了鲜明对比,后者用户需要为有闲置时间的计算机付费。
作为云计算的下一个迭代,无服务器计算让开发者可以更关注于构建产品中的应用,而不需要管理和维护底层堆栈,且比传统云计算更为便宜,因此无服务器被誉为“开发新应用最快速的方式,同时也是总成本最低的方式”。
“伯克利观点”甚至认为,无服务器计算提供了一个接口,极大地简化了云编程,这种转变类似于“从汇编语言迁移到高级编程语言”。
从诞生开始,“无服务器”就被寄予了厚望,但在发展过程中也免不了会存在争议,之前涉及到的一些问题有:
- 编程语言受限。大多数无服务器平台仅支持运行特定语言编写的应用。
- 供应商锁定风险。在“函数”的编写、部署和管理方式上,几乎不存在跨平台的标准。这意味着将“函数”从一个特定于供应商的平台迁移到另一个平台非常耗时费劲。
- 性能问题如冷启动。如果某个“函数”之前未在特定平台上运行过,或是在一段时间内未运行,那么就需要耗费一些时间做初始化。
2019 年被认为是无服务器有重大发展的一年。在这一年的年底,亚马逊云科技发布了 Amazon Lambda 的“预置并发(Provisioned Concurrency)”功能,它允许亚马逊云科技无服务器计算用户使其函数保持“已初始化并准备好在两位数毫秒内响应”的状态,这意味着“冷启动”问题成为过去,行业达到一个成熟点。
虽然这项技术仍然有较长的路要走,但随着越来越多的公司,包括亚马逊云科技、谷歌、微软在这项技术上的投资,我们看到了无服务器采用率在持续增长。据 Datadog 2021 年发布的无服务器状态报告,开发人员正加速采用无服务器架构:2019 年之后 Amazon Lambda 的使用率显著增加,2021 年初,Amazon Lambda 函数的平均每天调用频率是两年前的 3.5 倍,且半数 Amazon Web Services 新用户已采用 Amazon Lambda。虽然微软和谷歌的份额有所上升,但作为无服务器技术的先驱,Amazon Lambda 在采用率方面一直保持领先地位,有一半的函数即服务(FaaS)用户在使用亚马逊云科技的服务。据 Amazon Web Services 公布的数据显示,已有数十万家客户在用 Amazon Lambda 来构建他们的服务。
2.通过 Amazon Lambda 看无服务器技术的演进
Amazon Lambda 是一种事件驱动的计算引擎,亚马逊云科技在 2014 年 11 月的亚马逊云科技 re:Invent 大会上发布了该功能的预览版本。这马上引起了竞争对手的跟进,不少企业纷纷开始在云上提供类似服务,谷歌于次年 2 月发布了 Cloud Functions, IBM 也于同月发布了 Bluemix OpenWhisk,微软于次年 3 月份发布预览版 Azure Functions,等等。
在 Amazon Web Services 的产品页面上,亚马逊云科技给 Amazon Lambda 下的定义是:“用户无需预置或管理基础设施即可运行代码。只需编写代码并将其作为 .zip 文件或容器镜像上传即可。”
一个简单的用例是,西雅图时报使用无服务器技术自动调整移动、平板电脑和桌面设备显示所需的图像大小,每当图像被上传到 Amazon Simple Storage Service (S3) ,就会触发 Amazon Lambda 函数调用执行调整图像大小的功能。西雅图时报仅在调整图像大小后才向 Amazon Web Services 付费。
Amazon Lambda 的关键进展
对于要探索无服务器技术的团队来说,了解 Amazon Lambda 至关重要。无服务器虽然不等于 Amazon Lambda,但自 2014 年发布以来,Amazon Lambda 几乎已成为 Amazon Serverless 服务的代名词。实际上,Amazon Lambda 需要和其它工具一起才能形成一套完整的无服务器架构,比如通过 Amazon API Gateway 发送 HTTP 请求,或调用 Amazon S3 存储桶、Amazon DynamoDB 表或 Amazon Kinesis 流中的资源。
在发布早期,还只有 Amazon S3、Amazon DynamoDB 和 Amazon Kinesis 可用于 Amazon Lambda 函数。但自那之后,亚马逊云科技又逐步为 Amazon Lambda 函数集成了许多其它服务,例如 Amazon Cognito 认证、Amazon API Gateway、Amazon SNS 、Amazon SQS、Amazon CloudFormation 和 Amazon CloudWatch 等等。
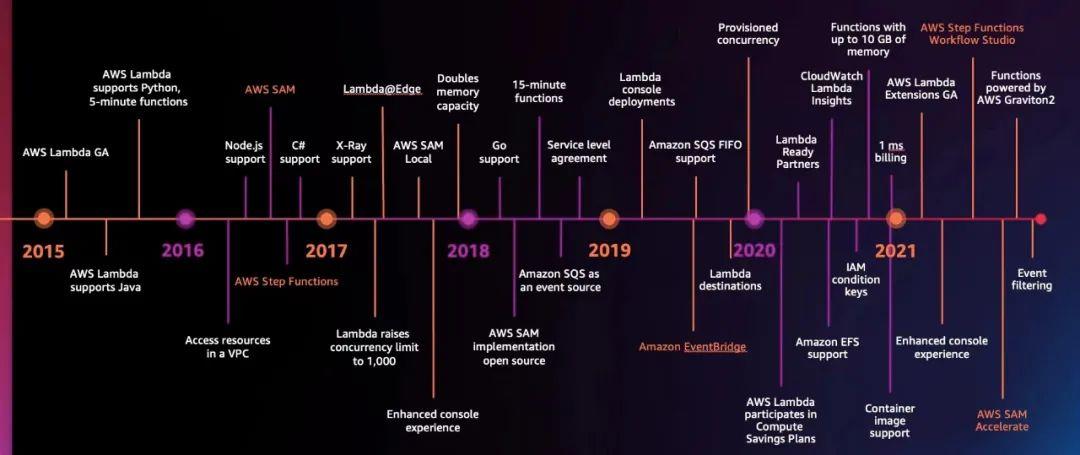
在 2014 年推出时,Amazon Lambda 只支持 Node.js,2015 年底,Amazon Lambda 中添加了 Java 支持,2016 年的时候又添加了 Python 支持。到现在,Amazon Lambda 原生支持 Java、Go、PowerShell、Node.js、C#、Python 和 Ruby 代码,并提供 Runtime API,允许用户使用任何其它编程语言来编写函数。
使用 Amazon Lambda ,用户除上传代码(或在 Amazon Lambda 控制台中构建代码)外,还需要选择内存、超时时间来创建函数。
最开始 Amazon Lambda 函数超时时长为 30 秒,后来被延长为 5 分钟。2018 年 10 月,Amazon Web Services 将超时时长设置为了 15 分钟,从此用户可以运行时间更长的函数,更加轻松地执行大数据分析、批量数据转换、批量事件处理和统计计算等任务。
Amazon Lambda 函数会根据配置的内存量线性分配 CPU 和其他资源。2020 年底,Amazon Lambda 函数的内存上限调整为了 10 GB ,与之前相比增加了 3 倍多,这也意味着用户可以在每个执行环境中访问多达 6 个 vCPU,可以让用户的多线程和多进程程序运行得更快。
在发布至今这七年里,Amazon Serverless 服务各方面都在不断改进:
2016 年,亚马逊云科技发布了 Amazon Step Functions,可以组合调用多个 Amazon Lambda 函数和其它 Amazon 服务,将复杂的业务逻辑可视化地表达为低代码、事件驱动的工作流。
2017 年,Amazon Lambda 的默认并发数提升到了 1000,并提供了分布式跟踪工具 X-Ray。
2018 年,亚马逊云科技发布了 Amazon Aurora Serverless v1 版本,正式宣告更复杂的关系型数据库(RDBMS)也能具备 Serverless 的特性,实现了云数据库基于负载的自动启停与弹性扩展。随着云服务的演化,亚马逊云科技相继发布了五项 Serverless 数据库服务,包括 Amazon Aurora Serverless、Amazon DynamoDB、Amazon Timestream(一种时间序列数据库服务)、Amazon Keyspaces(兼容 Apache Cassandra 的托管数据库服务)和 Amazon QLDB(一种全托管的分类账数据库)。目前,Amazon Aurora Serverless 已从 v1 版进化到 v2 版,Aurora Serverless v2 可以在一秒内将数据库工作负载从数百个事务扩展到数十万个事务,与为峰值负载配置容量的成本相比,最多可节省 90% 的数据库成本。
2019 年,亚马逊云科技发布了 Amazon EventBridge,它是一种无服务器事件总线服务,作为集中式枢纽连接到 Amazon Web Services 服务、自定义应用程序和 SaaS 应用程序,提供从事件源到目标对象(例如 Amazon Lambda 和其他 SaaS 应用程序)的实时数据流。现在 Amazon Lambda 可与 200 多种 Amazon Web Services 服务和 SaaS 应用程序相集成。
同年,亚马逊云科技还推出了 Amazon S3 Glacier Deep Archive,进一步按读写冷热程度完善了 S3 存储服务的智能收费档次。
2021 年 Amazon Lambda 计费功能调整为了 1ms 级别,并且还提供了容器镜像支持,以及 Amazon Graviton2 处理器支持,与基于 x86 的同类产品相比,Amazon Graviton2 性价比最高可提升 34%。
冷启动和厂商锁定
“冷启动”的性能改善算得上是一次标志性事件。FaaS 平台初始化函数实例需要一些时间。即使对于同一个特定的功能,不同的平台之间这种启动延迟可能会有很大差异,从几毫秒到几秒不等,取决于使用的库、函数配置的算力等大量因素。以 Amazon Lambda 为例,Amazon Lambda 函数的初始化要么是“热启动”,要么是“冷启动”。“热启动”是从前一个事件中重用 Amazon Lambda 函数的实例及其宿主容器,“冷启动”需要创建一个新的容器实例,启动函数宿主进程。在考虑启动延迟时,“冷启动”更受关注。
亚马逊云科技在 2019 年提供了一项名为“预置并发(Provisioned Concurrency)” 的重要新功能,通过让函数保持初始化状态,从而更精确地控制启动延迟。用户需要做的就是设置一个值,指定平台需要为特定功能配置多少个实例,Amazon Lambda 服务本身将确保始终有该数量的预热实例等待工作。“冷启动”无疑是无服务器技术批评者指出的最大问题,而亚马逊云科技这项功能的出现,代表着关于“冷启动”的争议已经结束。
除此之外,“厂商锁定”也是一个极具争议的地方。几年前,作为无服务器技术的反对方,CoreOS 首席执行官 Alex Polvi 称 Amazon Lambda 无服务器产品“是我们在人类历史上见过的最糟糕的专有锁定形式之一”。而为 MongoDB 工作的 Matt Asay 撰文反驳他说,“完全避免锁定的方法是自己编写所有底层软件(事件模型、部署模型等)”。
总之,作为支持方,很多人认为“锁定”并不是一件非黑即白的事情,而是本身需要反复权衡的一种架构选择。还有技术专家表示,可以采用将应用程序和平台分离的设计方式,以及标准化技术的方法最小化迁移成本:如果使用标准化的 HTTP,那么可以使用 Amazon API Gateway 将 HTTP 请求转换为 Amazon Lambda 事件格式;如果使用标准化的 SQL,那么使用与 mysql 兼容 Amazon Aurora Serverless,可以自然地简化数据库的迁移路径…
最佳实践案例
发展到现在,用户在哪些场景下会使用无服务器计算?实际上,每年的亚马逊云科技 re:Invent 大会都会有一些团队给大家分享实践经验,其中不乏具有代表性的案例。
在 2017 年的亚马逊云科技 re:Invent 会议上,美国电信 Verizon 的 Revvel 团队介绍了他们如何使用 Amazon Lambda 和 Amazon S3 进行视频不同格式的转码。早先团队使用的是 EC2 实例,如果视频长达 2 小时或大到几百 G,问题就变得很棘手,高清转换可能需要 4-6 个小时,而转换工作中途一旦停止或中断就意味着前功尽弃。所以,Revvel 团队采用的新方法是将视频分为 5M 的小块分别存储在 Amazon S3 存储桶中,然后用 Amazon Lambda 启用上千实例并行计算,完成转码后再合并成一个完整的视频,整个过程缩短到不足 10 分钟,费用也降低到了原来的十分之一。
在 2020 年的亚马逊云科技 re:Invent 会议上,Coca-Cola 的 Freestyle 设备创新团队分享了他们的非接触式售卖机解决方案:使用 Amazon Lambda 和 Amazon API Gateway 构建后端托管服务,前端使用 Amazon CloudFront ,从而可以在一周内推出原型,并在三个月内将 Web 应用程序从原型扩展到 10000 台机器,进而在疫情期间快速占领市场。
在今年的亚马逊云科技 re:Invent 会议主题演讲里,Werner Vogels 博士讲述了 New World Game 多人游戏中的无服务器解决方案。这是一款非常复杂的大规模分布式实时游戏,可处理 30 次 /s 的动作或状态,重绘和计算需要大量的 CPU 资源。它通过每 30 秒 80 万次写入将用户的状态存储在 Amazon DynamoDB 中,这样用户即使意外中断游戏也能及时恢复到之前的游戏状态。同时通过日志记录用户操作,然后使用 Amazon Kinesis 传输日志事件,速度可达 2300 万事件 / 分钟,随后将事件流推送到 Amazon S3 中,再用 Amazon Athena 进行分析处理。利用该数据流,团队可即时预测游戏用户行为和更改游戏中的策略。游戏环境中的运营,比如登录、交易、通知等操作事件,都是通过 Amazon Lambda 无服务器计算来实现的。
无服务器在这款多人游戏中发挥了非常重要的作用,但这种大型架构也对无服务器的性能提出了非常大的挑战。Amazon Lambda 达到了每分钟 1.5 亿次的调用频率,这比行业里的平均水准高出数倍。

3.无服务器的未来
在今年年底,亚马逊云科技一口气推出了五款无服务器产品:
Amazon Redshift Serverless,可自动配置计算资源,使用 SQL 跨数据仓库、运营数据库和数据湖分析结构化和非结构化数据。
Amazon EMR Serverless(预览版),是 Amazon EMR 中的一个新选项,让数据工程师和分析师能够借助开源分析框架,例如 Apache Spark、Hive 和 Presto,在云中运行 PB 级数据分析。
Amazon MSK Serverless(公开预览版),全新类型的 Amazon MSK 集群,完全兼容 Apache Kafka,且无需管理 Kafka 的容量,服务会自动预置和扩展计算及存储资源。
Amazon Kinesis On-demand,用于大规模实时流数据处理,服务会自动按需扩展和缩减。
Amazon SageMaker Serverless Inference(预览版),让开发者无需配置或管理底层基础设施即可部署机器学习模型进行推理,按执行时间和处理的数据量付费。
由此,我们可以看到云上的 Serverless 服务越来越多,无服务器计算的能力已经从计算、存储、数据库服务扩展到数据分析,以及机器学习的推理。以前机器学习的推理需要启动大量的资源来支撑峰值请求。如果使用 EC2 推理节点,空闲资源会推高成本,而使用 Amazon Lambda 服务,就不需要再考虑集群节点管理这些事情,服务会根据 Workload 自动预置、扩展和关闭计算容量,只为执行时间和处理的数据量付费,相比之下能节省很多。
Amazon Serverless 服务在不断进化的同时,计算架构也在不断改进,比如用户可以将原来的 Intel x86 处理器,通过平台提供的选项配置为 Amazon Graviton2 ARM 处理器,性能更快且能便宜 20%。有技术专家认为,平台也会朝着更智能的方向发展,“现在需要用户改配置选择更便宜的 ARM 处理器,未来服务完全可以做到自动选择计算平台。”
作为云计算的一种演进方式,无服务器的愿景必定会改变我们对编写软件的看法。以前从来没有一种方法可以像云计算这样考虑如何使用数百万个处理器内核和 PB 级内存进行设计,而现在无服务器已经进入到通用和可用的阶段,用户无需考虑如何管理这些资源。
就像 Werner Vogels 博士在主题演讲里讲的那样:“如果不用云计算,这些大型架构根本无法实现。所以现在,用属于 21 世纪的架构去随心构建你梦想的系统吧(Build systems the way you always wanted to,but never could)。”
以上是关于经过七年演进,Serverless流行起来了吗?的主要内容,如果未能解决你的问题,请参考以下文章