TensorFlow环境搭建总结
Posted 芯青年0
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow环境搭建总结相关的知识,希望对你有一定的参考价值。
说明
从开始决定使用TensorFlow已经好几天了,前前后后也是踩了很多坑,周日中午总算是把所有问题解决,成功调用GPU训练网络,现将遇到的问题,搭建环境的流程,相关的参考博客汇总如下,避免后人采坑。
本人所采用的各个工具版本如下:
显卡:RTX3090
系统:ubuntu20.04
CUDA:11.2
cudnn:v8.1.1
显卡驱动:nvidia-460
通过使用anaconda3搭建环境

NVIDIA-460显卡驱动安装
参考:显卡驱动安装
各个工具版本对应关系
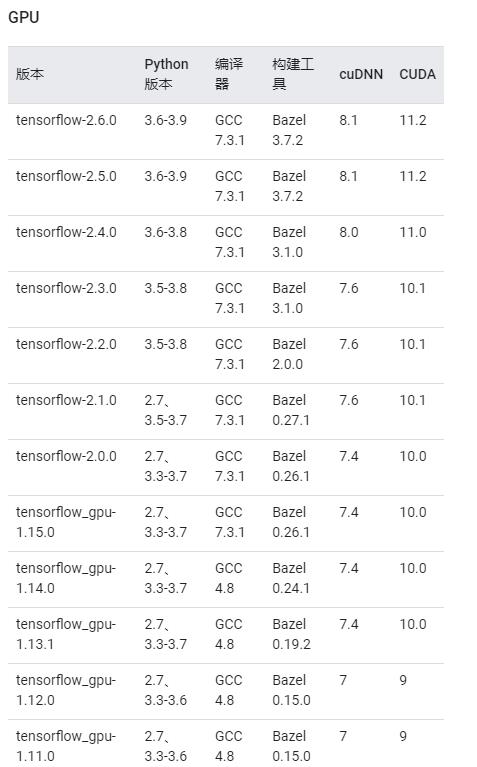
来源:https://www.tensorflow.org/install/source#gpu
CUDA安装
目前大部分3090配置的CUDA版本都是11.2,也有个别使用的是11.0版本,但是在安装过程中出现了各种问题,所以建议安装CUDA11.2版本,安装包的下载和参考博客如下:
验证:
nvcc -V
有:

针对需要安装多个CUDA版本的系统,可采用多版本切换的方式来使用不同版本的CUDA,在安装了多个cuda版本后,可以在/usr/local/目录下查看自己安装的cuda版本,如下图所示:

这里,cuda-11.0和cuda-11.2就是我们安装的两个cuda版本了,而cuda是一个软链接,它指向我们指定的cuda版本(注意在设置环境变量时,使用的是cuda,而不是cuda-11.0和cuda-11.2,这主要是为了方便我们切换cuda版本,可以让我们不用每次都去该环境变量的值)
可以使用stat命令查看当前cuda软链接指向的哪个cuda版本,如下所示:
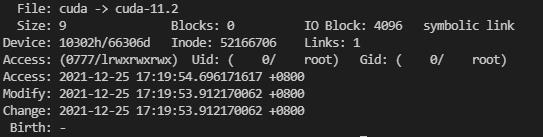
可以看到,文件类型是symbolic link,而指向的目录正是/usr/local/cuda-11.2,当我们想使用cuda-11.0版本时,只需要删除该软链接,然后重新建立指向cuda-11.0版本的软链接即可(注意名称还是cuda,因为要与bashrc文件里设置的保持一致)
sudo rm -rf cuda
sudo ln -s /usr/local/cuda-11.0 /usr/local/cuda
想切换其他版本的cuda,只需要改动建立软链接时cdua的正确路径即可
cudnn安装
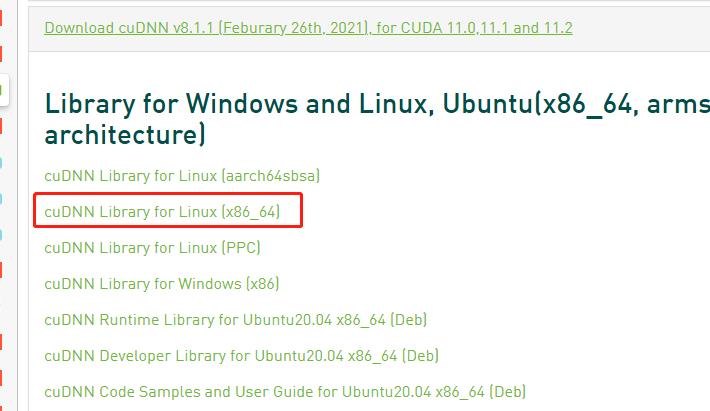
下载其中的v8.1.1版本,解压:
tar -zxvf cudnn-11.2-linux-x64-v8.1.1.33.solitairetheme8
解压后有一个cuda文件夹,将其中的lib64和include文件复制到cuda对应的目录下:
sudo cp cuda/lib64/* /usr/local/cuda/lib64/
sudo cp cuda/include/* /usr/local/cuda/include/
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/li`在这里插入代码片`b64/libcudnn*
使用指令验证:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
结果:

Anaconda3安装
直接官网下载安装包(Anaconda3)使用指令
bash Anaconda3-xxxx.xx-Linux-x86_64.sh
安装Anaconda3,之后在.bashrc中添加环境变量export PATH=$PATH:/home/用户名/anaconda3/bin,注意添加后source下.bashrc文件。
创建conda虚拟环境
创建python版本为3.7的环境:
conda create -n name python=3.7
安装指定版本的TensorFlow-gpu:
pip install tensorflow-gpu==2.5.0 -i http://pypi.douban.com/simple
验证
可使用代码:
import tensorflow as tf
print(tf.__version__)
print('GPU', tf.config.list_physical_devices('GPU'))
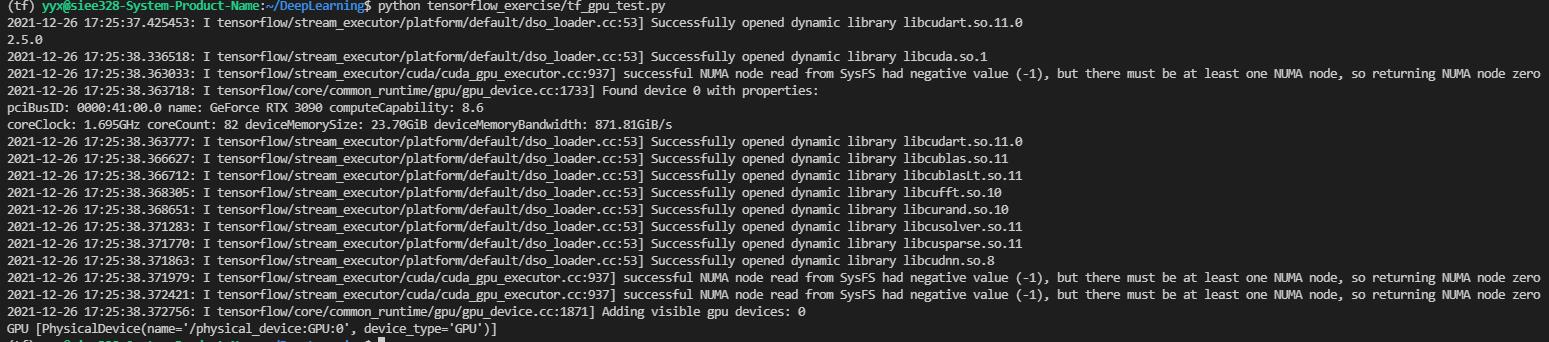
问题说明
- 缺失xxx.so.11等问题
针对训练中出现缺失libcusolver.so.11文件,libcublas.so.11文件等错误,在/usr/local/cuda目录下find -name libcublas.so.11,发现存在于/usr/local/cuda/targets/x86_64-linux/lib目录中,在.bashrc文件中添加:
export LD_LIBRARY_PATH=/usr/local/cuda/targets/x86_64-linux/lib:$LD_LIBRARY_PATH
- NUMA node问题
准对训练中出现的:
successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
因为不会影响代码的运行,没有深究,可以不管。
以上是关于TensorFlow环境搭建总结的主要内容,如果未能解决你的问题,请参考以下文章