开源web框架django知识总结(十七)
Posted 主打Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源web框架django知识总结(十七)相关的知识,希望对你有一定的参考价值。
开源web框架django知识总结(十七)
商品搜索
全文检索方案Elasticsearch
1. 全文检索和搜索引擎原理
商品搜索需求
- 当用户在搜索框输入商品关键字后,我们要为用户提供相关的商品搜索结果。
商品搜索实现
-
可以选择使用模糊查询
like关键字实现。 -
但是 like 关键字的效率极低。
# 模糊查询
# like
# %表示任意多个任意字符
# _表示一个任意字符
SELECT *
FROM users
WHERE username LIKE '%python%' AND is_delete = 0;
- 查询需要在多个字段中进行,使用 like 关键字也不方便。
全文检索方案
- 我们引入全文检索的方案来实现商品搜索。
- 全文检索即在指定的任意字段中进行检索查询。
- 全文检索方案需要配合搜索引擎来实现。
搜索引擎原理
-
搜索引擎进行全文检索时,会对数据库中的数据进行一遍预处理,单独建立起一份索引结构数据。
-
索引结构数据类似新华字典的索引检索页,里面包含了关键词与词条的对应关系,并记录词条的位置。
-
搜索引擎进行全文检索时,将关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。

结论: -
搜索引擎建立索引结构数据,类似新华字典的索引检索页,全文检索时,关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。
2. Elasticsearch介绍
实现全文检索的搜索引擎,首选的是Elasticsearch。
- Elasticsearch 是用 Java 实现的,开源的搜索引擎。
- 它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github等都采用它。
- Elasticsearch 的底层是开源库 Lucene。但是,没法直接使用 Lucene,必须自己写代码去调用它的接口。
分词说明
-
搜索引擎在对数据构建索引时,需要进行分词处理。
-
分词是指将一句话拆解成多个单字 或 词,这些字或词便是这句话的关键词。
-
比如:
我是中国人- 分词后:
我、是、中、国、人、中国等等都可以是这句话的关键字。
- 分词后:
-
Elasticsearch 不支持对中文进行分词建立索引,需要配合扩展
elasticsearch-analysis-ik来实现中文分词处理。
3. 使用Docker安装Elasticsearch
1.获取Elasticsearch-ik镜像
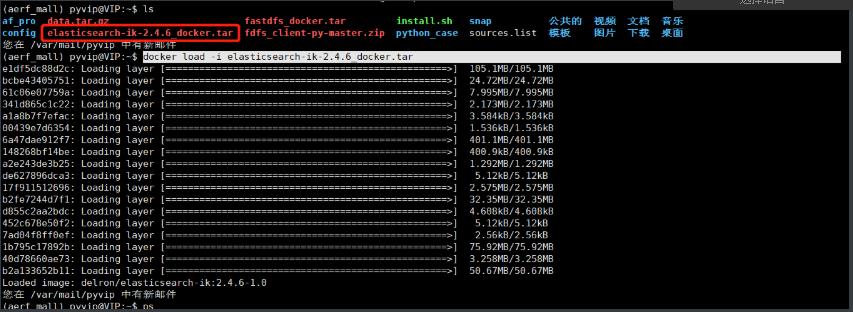
# 从仓库拉取镜像(elasticsearch-ik-2.4.6_docker.tar压缩包,老师课前已发,同学们不用下载)
#$ sudo docker image pull delron/elasticsearch-ik:2.4.6-1.0
# 解压教学资料中本地镜像
$ sudo docker load -i elasticsearch-ik-2.4.6_docker.tar
2.配置Elasticsearch-ik
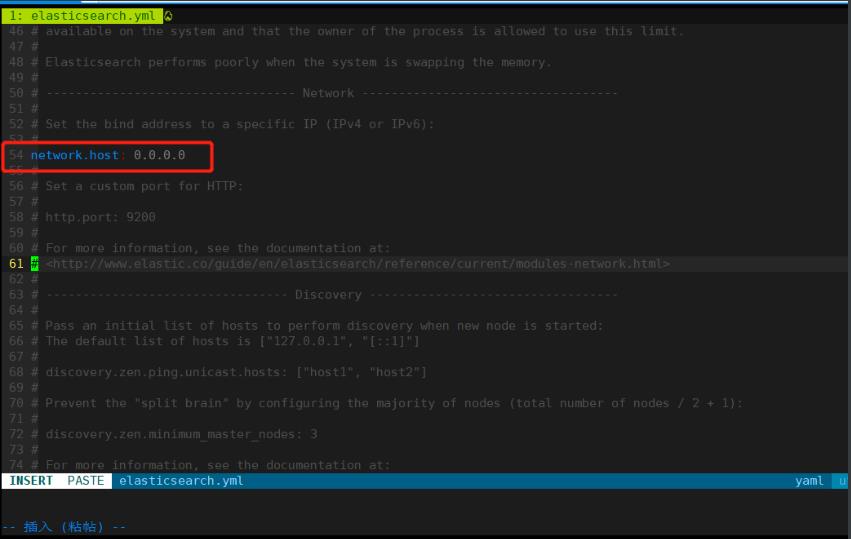
- 将教学资料中的
elasticsearc-2.4.6目录拷贝到home目录下。 - 修改
/home/pyvip/elasticsearc-2.4.6/config/elasticsearch.yml第54行。 - 更改ip地址为本机ip地址。
3.创建Docker容器并运行Elasticsearch-ik
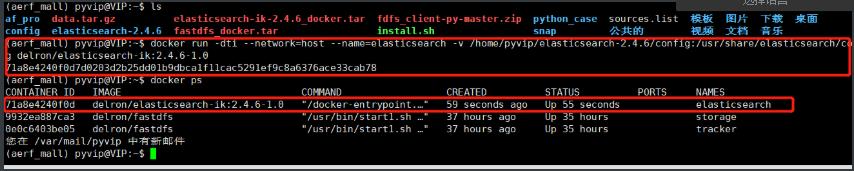
docker run -dti --network=host --name=elasticsearch -v /home/pyvip/elasticsearch-2.4.6/config:/usr/share/elasticsearch/config delron/elasticsearch-ik:2.4.6-1.0
Haystack扩展建立索引
提示:
- Elasticsearch 的底层是开源库 Lucene。但是没法直接使用 Lucene,必须自己写代码去调用它的接口。
思考:
- 我们如何对接 Elasticsearch服务端?
解决方案:
- Haystack
1. Haystack介绍和安装配置
1.Haystack介绍
- Haystack 是在Django中对接搜索引擎的框架,搭建了用户和搜索引擎之间的沟通桥梁。_
- 我们在Django中可以通过使用 Haystack 来调用 Elasticsearch 搜索引擎。
- Haystack 可以在不修改代码的情况下使用不同的搜索后端(比如
Elasticsearch、Whoosh、Solr等等)。
2.Haystack安装
# 进入项目虚拟环境
workon aerf_mall
# 如果安装报错,先初始化 pip3 install setuptools_scm
pip3 install django-haystack
pip3 install elasticsearch==2.4.1
3.Haystack注册应用和路由 在dey.py文件中加入如下配置:
INSTALLED_APPS = [
'haystack', # 全文检索
]
# Haystack
HAYSTACK_CONNECTIONS =
'default':
'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
'URL': 'http://192.168.42.128:9200/', # 此处为elasticsearch运行的服务器ip地址,端口号默认为9200
'INDEX_NAME': 'aerf_mall', # 指定elasticsearch建立的索引库的名称、注意修改数据库名字
,
# 设置每页显示的数据量
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 5
# 当数据库改变时,会自动更新索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
重要提示:
- HAYSTACK_SIGNAL_PROCESSOR 配置项保证了在Django运行起来后,有新的数据产生时,Haystack仍然可以让Elasticsearch实时生成新数据的索引
2. Haystack建立数据索引
1.创建索引类
- 通过创建索引类,来指明让搜索引擎对哪些字段建立索引,也就是可以通过哪些字段的关键字来检索数据。
- 本项目中对SKU信息进行全文检索,所以在
goods应用中新建search_indexes.py文件,用于存放索引类。
"""
注意:模块名字是固定的search_indexes
"""
from haystack import indexes
# SKU是被搜索的数据模型类
from .models import SKU
# 针对ES搜索引擎库定义一个索引模型类
class SKUIndex(indexes.SearchIndex, indexes.Indexable):
# text固定的字段
# document=True表示text字段用户被检索字段
# use_template=True使用模版来指定text字段中包含被检索的数据有哪些
text = indexes.CharField(document=True, use_template=True)
def get_model(self):
# 获取被检索数据的模型类
return SKU
def index_queryset(self, using=None):
# 返回被检索的查询集
return self.get_model().objects.filter(is_launched=True)
索引类SKUIndex说明:
- 在
SKUIndex建立的字段,都可以借助Haystack由Elasticsearch搜索引擎查询。 - 其中
text字段我们声明为document=True,表名该字段是主要进行关键字查询的字段。 text字段的索引值可以由多个数据库模型类字段组成,具体由哪些模型类字段组成,我们用use_template=True表示后续通过模板来指明。
2.创建text字段索引值模板文件
-
在
templates目录中创建text字段使用的模板文件 -
具体在
templates/search/indexes/goods/sku_text.txt文件中定义
object.id
object.name
object.caption
-
模板文件说明:当将关键词通过text参数名传递时
- 此模板指明SKU的
id、name、caption作为text字段的索引值来进行关键字索引查询。
- 此模板指明SKU的
3.手动生成初始索引
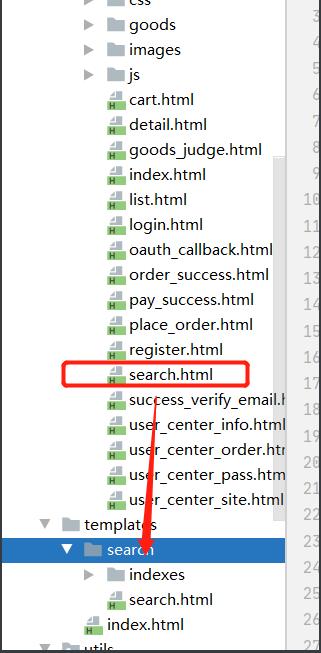
python manage.py rebuild_index
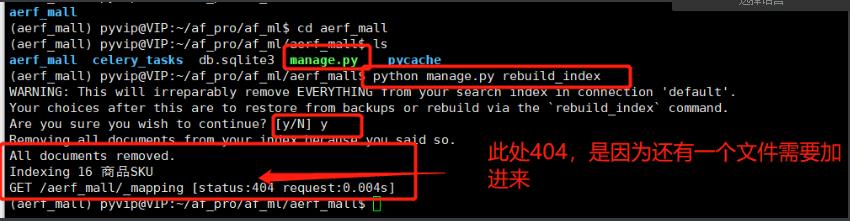
- 错误提示告诉我们在
templates/search/目录中缺少一个search.html文件 - search.html文件作用就是接收和渲染全文检索的结果。
将静态文件search.html文件拷贝到search文件夹下,再生成索引的时候就不会报404错了
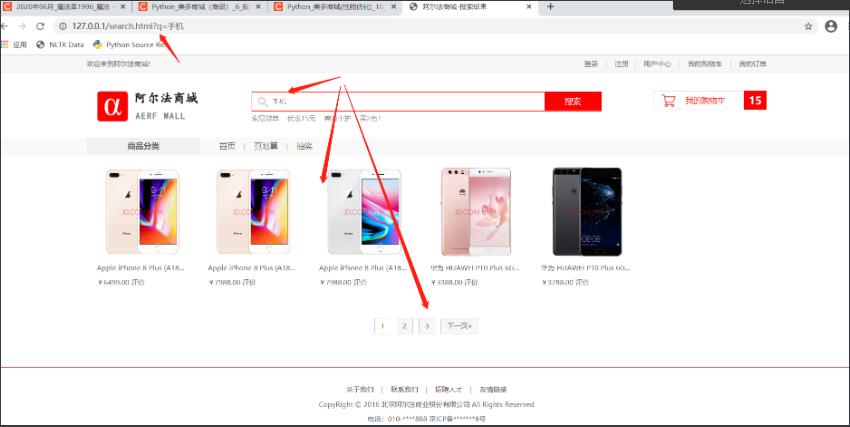
2. 渲染商品搜索结果
Haystack返回的数据包括:
query:搜索关键字paginator:分页paginator对象page:当前页的page对象(遍历page中的对象,可以得到result对象)result.objects: 当前遍历出来的SKU对象。
goods.views.py
# 使用Haystack提供的搜索视图,实现搜索
# SearchView搜索视图基类,它提供的视图对应的接口就是:
# 请求方式:GET
# 请求路径:search/
# 请求参数:?q=华为&page=1&page_size=3
# 响应数据:默认返回的是完整的html页面;不符合我们的接口需求,所以调整它的返回值
from haystack.views import SearchView
class MySearchView(SearchView):
# 当前搜索是"短语精确搜索" —— 不会把用户的搜索词进行分词处理;
# 构建一个响应
def create_response(self):
# 默认SearchView搜索视图逻辑:先搜索出结果,再调用create_response函数构建响应
# 1、获取全文检索的结果
context = self.get_context()
# context['query'] 检索词
# context['paginator'] 分页器对象
# context['paginator'].count 数据量
# context['paginator'].num_pages 当前页
# context['page'].object_list 列表(SearchResult对象)
# SearchResult.object 被搜索到的SKU模型类对象
sku_list = []
# 2、从查询的结果context中提取查询到的sku商品数据
for search_result in context['page'].object_list:
# search_result: SearchResult对象
# search_result.object: SKU模型类对象
sku = search_result.object
sku_list.append(
'id': sku.id,
'name': sku.name,
'price': sku.price,
'default_image_url': sku.default_image_url.url,
'searchkey': context['query'],
'page_size': context['paginator'].per_page,
'count': context['paginator'].count
)
# sku_list = [
#
# 'id': 1,
# 'name': '苹果100',
# 'price': 10,
# 'default_image_url': 'http://192.168.42.1:8888/group1/M00/00/02/CtM3BVrPB4GAWkTlAAGuN6wB9fU4220429',
# 'searchkey': '华为',
# 'page_size': 5,
# 'count': 12
#
# ]
return JsonResponse(sku_list, safe=False) #当safe=True并且所传过来的data不是dict类型时,会引发异常,提醒我们如果传过来的objects不是dict,就将safe参数设置为False.
goods.urls.py
from django.urls import re_path
from .views import *
urlpatterns = [
re_path(r'^search/$', MySearchView()),
]
celery知识补充
1、celery worker的工作模式
- 默认是进程池方式,进程数以当前机器的CPU核数为参考,每个CPU开四个进程。
- 如何自己指定进程数:`celery worker -A proj --concurrency=4
celery -A celery_tasks.main worker -l info -c 10
如何改变进程池方式为协程方式:`celery worker -A proj --concurrency=1000 -P eventlet -c 1000
# 安装eventlet模块
pip install eventlet
# 启用 Eventlet 池
celery -A celery_tasks.main worker -l info -P eventlet -c 1000
2、celery_tasks\\email\\tasks.py
from django.core.mail import send_mail
from django.conf import settings
from celery_tasks.main import app
# @app.task(name='send_verify_email')
# def send_verify_email(to_email, verify_url):
# subject = '阿尔法商城邮箱验证'
#
# html_message = '<p>尊敬的用户您好!</p>' \\
# '<p>感谢您使用阿尔法商城。</p>' \\
# '<p>您的邮箱为:%s 。请点击此链接激活您的邮箱:</p>' \\
# '<p><a href="%s">%s<a></p>' % (to_email, verify_url, verify_url)
# send_mail(
# subject,
# '',
# settings.EMAIL_FROM,
# [to_email],
# html_message=html_message
# )
# bind: 保证task对象会作为第一个参数自动传入。bind=True,函数加self,代表任务对象
# name:异步任务别名
# retry_backoff : 异常自动重试的时间间隔 第n次(retry_backoff*2^(n-1))s 3s 6s 12s
# max_retries:异常自动重试次数的上限
@app.task(bind=True, name='send_verify_email', retry_backoff=3)
def send_verify_email(self, to_email, verify_url):
"""
发送验证邮箱邮件
:param to_email: 收件人邮箱
:param verify_url: 验证链接
:return: None
"""
subject = "阿尔法商城邮箱验证"
html_message = '<p>尊敬的用户您好!</p>' \\
'<p>感谢您使用阿尔法商城。</p>' \\
'<p>您的邮箱为:%s 。请点击此链接激活您的邮箱:</p>' \\
'<p><a href="%s">%s<a></p>' % (to_email, verify_url, verify_url)
try:
send_mail(subject, "", settings.EMAIL_FROM, [to_email], html_message=html_message)
except Exception as e:
# 有异常自动重试三次
raise self.retry(exc=e, max_retries=3)

祝大家学习python顺利!
以上是关于开源web框架django知识总结(十七)的主要内容,如果未能解决你的问题,请参考以下文章