Kubernetes 调度器调度策略分析
Posted 回归心灵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes 调度器调度策略分析相关的知识,希望对你有一定的参考价值。
整体认知
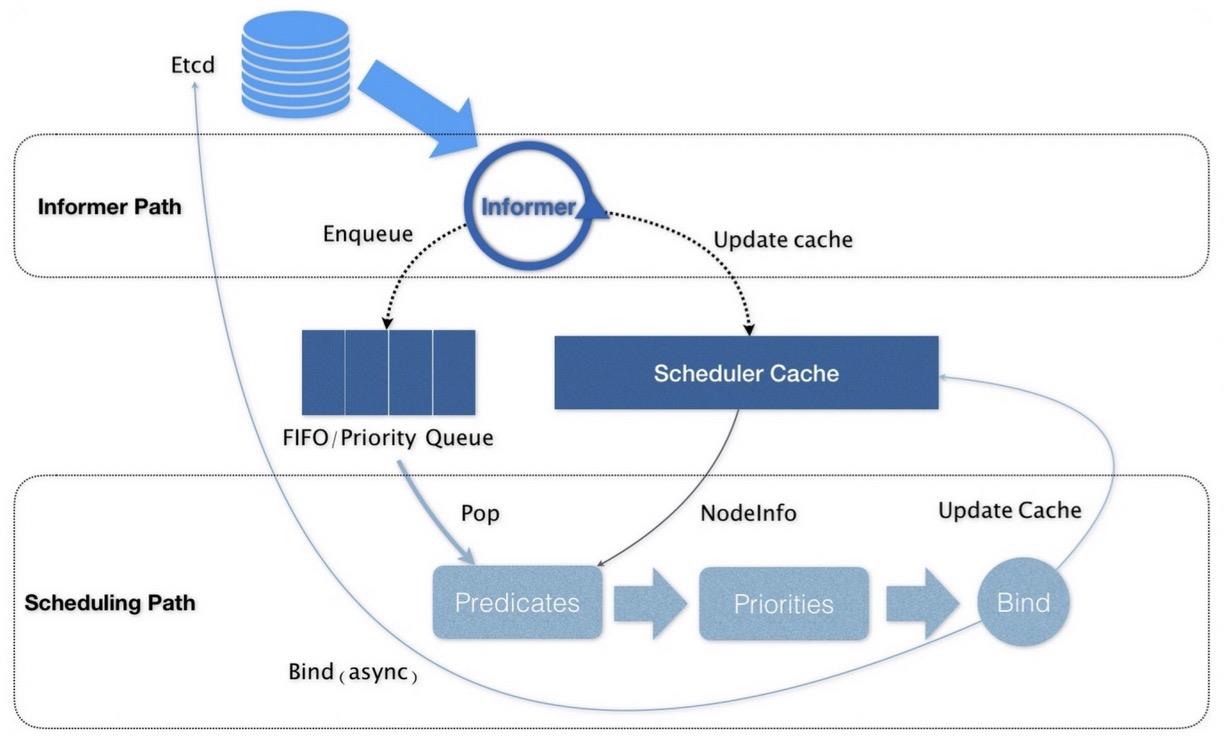
调度策略工作流程
在具体的调度流程中,默认调度器会首先调用一组叫作 Predicate 的调度算法,来检查每个 Node,筛选出能够调度的 Node。然后,再调用一组叫作 Priority 的调度算法,给上一步筛选出的每个 Node 打分。最终选出得分最高的 Node 作为 Pod 的调度节点。
调度流程图

Predicates 和 Priorities 详细介绍
pkg/scheduler/generic_scheduler.go:93
pkg/scheduler/generic_scheduler.go:106
pkg/scheduler/generic_scheduler.go:215 predicates
pkg/scheduler/generic_scheduler.go:129
pkg/scheduler/generic_scheduler.go:398 priority
pkg/scheduler/generic_scheduler.go:134
pkg/scheduler/generic_scheduler.go:146 select highest score host
Predicates
Predicates 在调度过程中的作用是过滤出一些列能够运行待调度 pod 的节点。Predicates 大致可以分为以下四种类型:
第一种类型,叫作 GeneralPredicates。这一组过滤规则,负责的是最基础的调度策略。比如,Fit plugin 就是计算宿主机的 CPU 和内存资源等是否够用, NodePorts plugin 用于检查宿主机的空闲端口是否能满足 pod 需要。
第二种类型,是与 Volume 相关的过滤规则。这一组过滤规则,负责的是跟容器持久化 Volume 相关的调度策略。例如 VolumeZone plugin 检查持久化 Volume 的 Zone 标签是否与宿主机节点的 Zone 标签相匹配。VolumeBinding plugin 检查该 Pod 对应的 PV 的 nodeAffinity 字段,是否跟某个节点的标签相匹配。
第三种类型,是宿主机相关的过滤规则。这一组规则,主要考察待调度 Pod 是否满足 Node 本身的某些条件。例如 TaintToleration plugin 检查 pod 的 Toleration 字段与 Node 的 Taint 字段能够匹配。
第四种类型,是 Pod 相关的过滤规则。例如 InterPodAffinity。这个规则的作用,是检查待调度 Pod 与 Node 上的已有 Pod 之间的亲密(affinity)和反亲密(anti-affinity)关系
// Filters the nodes to find the ones that fit the pod based on the framework
// filter plugins and filter extenders.
func (g *genericScheduler) findNodesThatFitPod(ctx context.Context, extenders []framework.Extender, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error)
diagnosis := framework.Diagnosis
NodeToStatusMap: make(framework.NodeToStatusMap),
UnschedulablePlugins: sets.NewString(),
// Run "prefilter" plugins.
s := fwk.RunPreFilterPlugins(ctx, state, pod)
allNodes, err := g.nodeInfoSnapshot.NodeInfos().List()
if err != nil
return nil, diagnosis, err
if !s.IsSuccess()
if !s.IsUnschedulable()
return nil, diagnosis, s.AsError()
// All nodes will have the same status. Some non trivial refactoring is
// needed to avoid this copy.
for _, n := range allNodes
diagnosis.NodeToStatusMap[n.Node().Name] = s
// Status satisfying IsUnschedulable() gets injected into diagnosis.UnschedulablePlugins.
diagnosis.UnschedulablePlugins.Insert(s.FailedPlugin())
return nil, diagnosis, nil
// "NominatedNodeName" can potentially be set in a previous scheduling cycle as a result of preemption.
// This node is likely the only candidate that will fit the pod, and hence we try it first before iterating over all nodes.
if len(pod.Status.NominatedNodeName) > 0 && feature.DefaultFeatureGate.Enabled(features.PreferNominatedNode)
feasibleNodes, err := g.evaluateNominatedNode(ctx, extenders, pod, fwk, state, diagnosis)
if err != nil
klog.ErrorS(err, "Evaluation failed on nominated node", "pod", klog.KObj(pod), "node", pod.Status.NominatedNodeName)
// Nominated node passes all the filters, scheduler is good to assign this node to the pod.
if len(feasibleNodes) != 0
return feasibleNodes, diagnosis, nil
feasibleNodes, err := g.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, allNodes)
if err != nil
return nil, diagnosis, err
feasibleNodes, err = findNodesThatPassExtenders(extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
if err != nil
return nil, diagnosis, err
return feasibleNodes, diagnosis, nil
Priorities
Priorities 在调度过程中的作用是为 Predicates 阶段过滤出的一系列节点打分。最后得分最高的作为 Pod 调度的最佳节点。
leastResourceScorer 计算调度在节点上的 pod 所请求的内存和CPU的百分比,并基于请求与容量的比例的平均值最小值确定优先级。
(cpu((capacity-sum(requested))*MaxNodeScore/capacity) + memory((capacity-sum(requested))*MaxNodeScore/capacity))/weightSum
mostResourceScorer 计算调度在节点上的 pod 所请求的内存和CPU的百分比,并基于请求与容量的比例的平均值最大值确定优先级。
(cpu(MaxNodeScore * sum(requested) / capacity) + memory(MaxNodeScore * sum(requested) / capacity)) / weightSum
// prioritizeNodes prioritizes the nodes by running the score plugins,
// which return a score for each node from the call to RunScorePlugins().
// The scores from each plugin are added together to make the score for that node, then
// any extenders are run as well.
// All scores are finally combined (added) to get the total weighted scores of all nodes
func prioritizeNodes(
ctx context.Context,
extenders []framework.Extender,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
nodes []*v1.Node,
) (framework.NodeScoreList, error)
// If no priority configs are provided, then all nodes will have a score of one.
// This is required to generate the priority list in the required format
if len(extenders) == 0 && !fwk.HasScorePlugins()
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes
result = append(result, framework.NodeScore
Name: nodes[i].Name,
Score: 1,
)
return result, nil
// Run PreScore plugins.
preScoreStatus := fwk.RunPreScorePlugins(ctx, state, pod, nodes)
if !preScoreStatus.IsSuccess()
return nil, preScoreStatus.AsError()
// Run the Score plugins.
scoresMap, scoreStatus := fwk.RunScorePlugins(ctx, state, pod, nodes)
if !scoreStatus.IsSuccess()
return nil, scoreStatus.AsError()
if klog.V(10).Enabled()
for plugin, nodeScoreList := range scoresMap
for _, nodeScore := range nodeScoreList
klog.InfoS("Plugin scored node for pod", "pod", klog.KObj(pod), "plugin", plugin, "node", nodeScore.Name, "score", nodeScore.Score)
// Summarize all scores.
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes
result = append(result, framework.NodeScoreName: nodes[i].Name, Score: 0)
for j := range scoresMap
result[i].Score += scoresMap[j][i].Score
if len(extenders) != 0 && nodes != nil
var mu sync.Mutex
var wg sync.WaitGroup
combinedScores := make(map[string]int64, len(nodes))
for i := range extenders
if !extenders[i].IsInterested(pod)
continue
wg.Add(1)
go func(extIndex int)
metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Inc()
defer func()
metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Dec()
wg.Done()
()
prioritizedList, weight, err := extenders[extIndex].Prioritize(pod, nodes)
if err != nil
// Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities
return
mu.Lock()
for i := range *prioritizedList
host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score
if klog.V(10).Enabled()
klog.InfoS("Extender scored node for pod", "pod", klog.KObj(pod), "extender", extenders[extIndex].Name(), "node", host, "score", score)
combinedScores[host] += score * weight
mu.Unlock()
(i)
// wait for all go routines to finish
wg.Wait()
for i := range result
// MaxExtenderPriority may diverge from the max priority used in the scheduler and defined by MaxNodeScore,
// therefore we need to scale the score returned by extenders to the score range used by the scheduler.
result[i].Score += combinedScores[result[i].Name] * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
if klog.V(10).Enabled()
for i := range result
klog.InfoS("Calculated node's final score for pod", "pod", klog.KObj(pod), "node", result[i].Name, "score", result[i].Score)
return result, nil
附录
以上是关于Kubernetes 调度器调度策略分析的主要内容,如果未能解决你的问题,请参考以下文章