试用GO开发python编译器:实现词法解析
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了试用GO开发python编译器:实现词法解析相关的知识,希望对你有一定的参考价值。
编译器由于涉及到编译原理,了解计算机科学的同学就能感触到,编译原理是较为抽象,无论从原理还是从实践上都是比较难把握的对象。在接触理论性较强,难度较大的问题时,最好的办法是从最简单的情况入手,先从感性上获得认知,为后面的理性认知打下基础,因此我们先从编译原理算法的基础入手,首先掌握词法解析。
上一节我们体会了“字节码”,现在问题在于”巧妇难为无米之炊“,我们总得有东西让我们产生字节码,这需要我们有能力将给定的代码进行解析后产生对应的字节码,而将代码转换为字节码的过程需要一系列非常复杂的操作,本节我们先从这些复杂操作的第一步,也就是词法解析开始。
词法解析简单来说就是对编程语言中的对象进行分类,例如在代码中,”1“,”234“,”3.14“等这类字符串我们将他们归类为NUMBER,用数值1来表示,类似”def", “map”, “string”,“with”,这类字符串我们将他们归类为KEYWORD,用数值2来表示,类似”+“,”-“,”*“,"/" ,"(",")",我们归类为OPERATOR,用数值3表示,类似"x",“y”,"my_str"等这类字符串归类为IDENTIFIER,用数值4表示,以此类推。如果我们把代码中对应的元素进相应归类后,一段看起来很复杂的代码其实就是一系列归类符号的组合,例如语句"x + (y - 1) "就可以转换成IDENTIFIER OPERATOR IDENTIFIER OPERATOR IDENTIFIER OPERAOTR NUMBR,由此词法解析其实是对源代码进行分析时所做的第一步抽象。
在词法解析中例如上面用来进行归类的标签,例如OPERATOR, IDENTIFIER,等我们统称为token,在python内核系列文章里面,我们下载了python编译器代码,里面有一个文件夹叫Grammar,在里面有一个文件叫token,打开之后能看到如下内容:
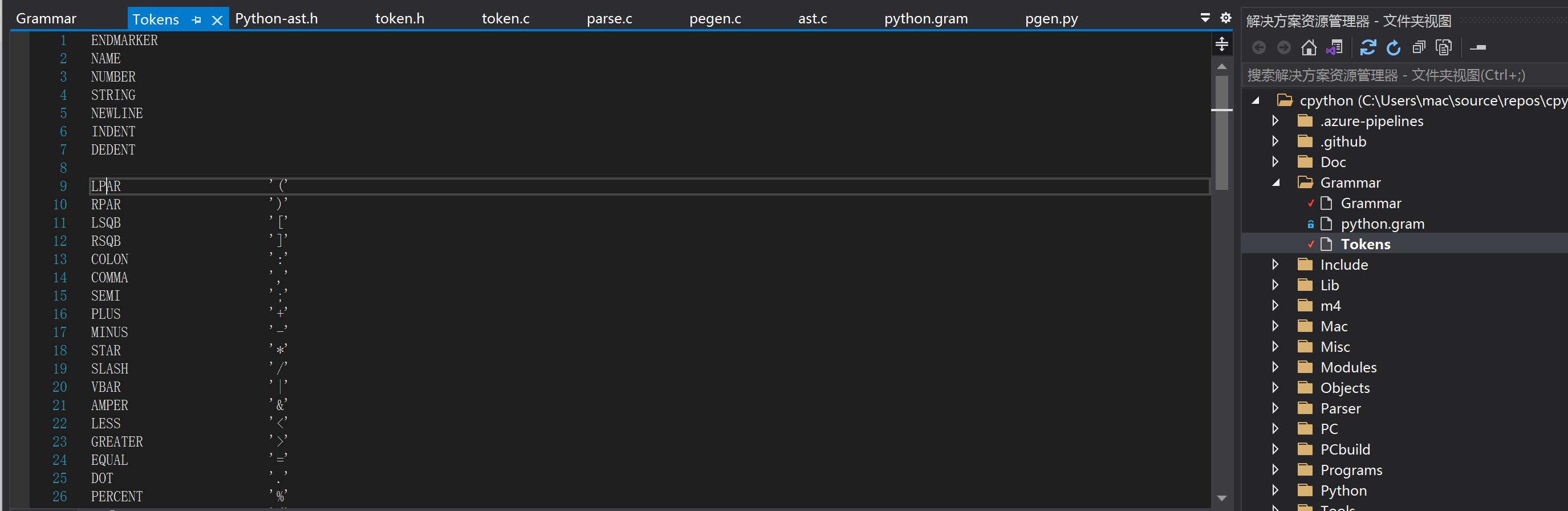
文件里面描述的就是对不同符号的归类,从上面可以看出左括号被归类为LPAR,所有的操作符号都有对应的归类,当读取一段Python代码后,将代码中不同符号根据上面的对应关系完成归类的过程就是词法解析。
接下来我们开始词法解析的实现,首先定义具体的数据结构,在上节基础上新建一个文件夹名为Token,在里面添加一个"token.go”文件,添加如下代码:
package token
type TokenType string
type Token struct
Type TokenType //类型
Literal string //对应字符串
//例如数值”1“对应的实例为Token "NUMBER", "1"
根据python语法的token文件,我们先进行一系列常量定义:
const (
ILLEGAL = "ILLEGAL"
EOF = "EOF"
INDENT = "INDENT" //变量类型对应的归类
NUMBER = "NUMBER" //数值类型对应的归类
EQUAL = "=" //赋值操作符
PLUS = "+" //加号操作符
LPAR = "("
RPAR = ")"
LBRACE = ""
RBRACE = ""
COMMA = ","
DEF = "def" //关键字
)
上面我们堆一系列符号进行了归类,当然还有很多符号没有进行相应归类,后面我们用到的时候再处理,要不然会搞得过于复杂。接下来我们的目标是读取一段代码字符串,将字符串分割成不同的单元,然后将这些单元对应到给定分类。在相同目录下新建一个文件夹叫lexer,里面添加一个文件名为lexer_test.go,相应内容如下:
package lexer
import(
"testing"
"token"
)
func TestNextToken(t *testing.T)
input := `=+(),`
tests := []struct
expectedType token.TokenType
expectedLiteral string
token.EQUAL, "=",
token.PLUS, "+",
token.LPAR, "(",
token.RPAR, ")",
token.LBRACE, "",
token.RBRACE, "",
token.COMMA, ",",
token.EOF, "",
l := New(input)
for i, tt := range tests
tok := l.NextToken()
if tok.Type != tt.expectedType
t.Fatalf("test[%d] - tokenType wrong. expected=%q, got=%q",
i, tt.expectedType, tok.Type)
if tok.Literal != tt.expectedLiteral
t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q",
i, tt.expectedLiteral, tok.Literal)
上面的测试用例还不能运行,我们需要先实现函数New,它返回一个对象能够提供接口NextToken,首先我们先进入Token文件夹设置一下其包信息:
go mod init token
然后进入到lexer文件夹,同样初始化一下包信息:
go mod init lexer
为了能成功引用token包,我们要打开lexer文件夹下的go.mod添加如下信息:
replace token => ../token
然后运行命令:
go mod tidy
完成上面操作后,lexer包就能使用token包导出的接口了。下面我们完成一个基本功能的词法解析器,在lexer文件夹下面新建一个文件为lexer.go,输入内容如下:
package lexer
type Lexer struct
input string //要解析的源代码字符串
position int //当前读取的字符位置
readPosition int //下一个要读取的字符位置,也就是position + 1
ch byte //读取的字符
func New(input string) *Lexer //生成一个词法解析器
l := &Lexerinput: input
return l
我们看上面代码,为何需position和readPosition两个变量呢,其中position指向当前读取的字符所在位置,readPosition指向下一个要读取的字符位置,在解析过程中,我们在读取到当前字符时,还需要看下一个字符的内容才能决定要执行的操作,因此我们还需要readPosition来指向下一个字符,下面实现相关的函数:
package lexer
import "token"
type Lexer struct
input string //要解析的源代码字符串
position int //当前读取的字符位置
readPosition int //下一个要读取的字符位置,也就是position + 1
ch byte //读取的字符
func New(input string) *Lexer //生成一个词法解析器
l := &Lexerinput: input
l.readChar() //先读取第一个字符
return l
func (l *Lexer) readChar() //读取当前字符
if l.readPosition >= len(l.input)
l.ch = 0
else
l.ch = l.input[l.readPosition]
l.position = l.readPosition
l.readPosition += 1
func (l *Lexer) NextToken() token.Token//读取一个字符,判断是否属于特定分类
var tok token.Token
switch l.ch
case '=':
tok = newToken(token.EQUAL, l.ch)
case '(':
tok = newToken(token.LPAR, l.ch)
case ')':
tok = newToken(token.RPAR, l.ch)
case ',':
tok = newToken(token.COMMA, l.ch)
case '+':
tok = newToken(token.PLUS, l.ch)
case '':
tok = newToken(token.LBRACE, l.ch)
case '':
tok = newToken(token.RBRACE, l.ch)
case 0: //读取到末尾
tok.Literal = ""
tok.Type = token.EOF
l.readChar()
return tok
func newToken(tokenType token.TokenType, ch byte) token.Token
return token.TokenType: tokenType, Literal: string(ch)
上面代码逻辑比较简单,每次从输入的字符串中读取一个字符,看看读到的字符是否属于特定分类,现在可以跑起测试用例,在命令行窗口进入lexer目录然后运行go test,没问题的话可以看到测试用例通过。
下面重点来了,我们要解析一段python代码,其内容如下:
def add(x, y):
assert x > 0 and y > 0
return x + y
上面是python代码定义的一个函数,在上面代码字符串中add, x, y, 属于一个类别,也就是变量名,我们用IDENTIFIER表示,(,)分别属于LPRA和RPRA。def, return, assert and属于同一个类别,也就是关键字,我们在lexer_test.go中添加对应测试用例
func TestNextToken2(t *testing.T)
input := `
def add(x, y):
z = x + y
return z
`
tests := []struct
expectedType token.TokenType
expectedLiteral string
token.DEF, "def",
token.IDENTIFIER, "add",
token.LPAR, "(",
token.IDENTIFIER, "x",
token.COMMA, ",",
token.IDENTIFIER, "y",
token.RPAR, ")",
token.COLON, ":",
token.IDENTIFIER, "z",
token.EQUAL, "=",
token.IDENTIFIER, "x",
token.PLUS, "+",
token.IDENTIFIER, "z",
token.RETURN, "return",
token.IDENTIFIER, "z"
l := New(input)
for i, tt := range tests
tok := l.NextToken()
if tok.Type != tt.expectedType
t.Fatalf("test[%d] - tokenType wrong. expected=%q, got=%q",
i, tt.expectedType, tok.Type)
if tok.Literal != tt.expectedLiteral
t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q",
i, tt.expectedLiteral, tok.Literal)
这里我们有个问题需要解决,那就是识别变量名,变量名的规则是以字母开头,后面跟着数字或者是下划线,因此解析逻辑就是,当我们读取到字符时,我们就进入到变量名的识别流程,也就是读取到字符后,如果接下来读取的还是字符,数字或者是下划线,我们就不断的往下走,直到遇到不是字符,数字或下划线的符号为止,由此我们在lexer.go中实现如下代码:
func (l *Lexer) NextToken() token.Token
var tok token.Token
switch l.ch
....
default:
if isLetter(l.ch)
tok.Literal = l.readIdentifier()
return tok
else
tok = newToken(token.ILLEGAL, l.ch)
l.readChar()
return tok
//如果读取到字符,数字或者下划线那么就继续读取下一个字符
func (l *Lexer) readIdentifier() string
position := l.position
for isLetter(l.ch)
l.readChar()
//获取到变量名字符串
return l.input[position : l.position]
func isLetter(ch byte) bool
return 'a' <= ch && ch <= 'z' || 'A' <= ch && ch <= 'Z' || ch == '_'
现在我们有一个问题,那就是满足变量名的条件中有一个字符串,他们不能简单看做是变量,这些字符串就是关键字,例如def, return, assert and,这些字符串有特定的功能,虽然他们的组成规则满足变量名的要求,但是我们要专门把他们抽取出来,于是我们回到token.go进行相应处理:
const (
ILLEGAL = "ILLEGAL"
EOF = "EOF"
IDENTIFIER = "IDENTIFIER" //变量类型对应的归类
NUMBER = "NUMBER" //数值类型对应的归类
EQUAL = "=" //赋值操作符
PLUS = "+" //加号操作符
LPAR = "("
RPAR = ")"
LBRACE = ""
RBRACE = ""
COMMA = ","
COLON = ":"
LESS = "<"
GREATER = ">"
DEF = "def" //关键字
INT = "int"
RETURN = "return"
ASSERT = "assert"
AND = "and"
)
var keywords = map[string]TokenType
"def" : DEF,
"int" : INT,
"return" : RETURN,
"assert" : ASSERT,
"and" : AND,
//将关键字从变量名中区别开来
func LookupIdent(ident string) TokenType
if tok, ok := keywords[ident]; ok
return tok
return IDENTIFIER
由此我们获得到变量名后,就得再做一次处理,看看所得变量名是不是关键字,由此回到lexer.go:
default:
if isLetter(l.ch)
tok.Literal = l.readIdentifier()
//看看变量名是否属于关键字
tok.Type = token.LookupIdent(tok.Literal)
return tok
else
tok = newToken(token.ILLEGAL, l.ch)
现在我们还有一个问题没有处理到,那就是空格,回车,换行等特殊符号,对Python而言空格有特定作用,但我们这里先忽略它,于是在读取字符时,遇到空格,回车,换行的字符时要忽略他们,所以在lexer.go中要做如下处理:
func (l *Lexer) NextToken() token.Token//读取一个字符,判断是否属于特定分类
var tok token.Token
//忽略空格,回车,换行等特定字符
l.skipSpecialChar()
....
func (l *Lexer) skipSpecialChar()
//不读取回车换行,空格等这些特定字符
for l.ch == ' ' || l.ch == '\\t' || l.ch =='\\n' || l.ch == '\\r'
l.readChar()
现在我们还有一种特定字符串需要处理,那就是数字,数字的规则就是,它由“0”到“9”这几个字符组成,我们暂时忽略调浮点数,只处理整数,于是一旦我们读取的字符串以数字开头时,我们就进入数字识别流程,接下来的字符必须跟着数字,一旦读取到非数字字符时,我们就判断当前读取到的字符合在一起是否形成有效数字,由此我们继续修改lexer.go:
func (l *Lexer) NextToken() token.Token
var tok token.Token
//忽略空格,回车,换行等特定字符
l.skipSpecialChar()
switch l.ch
...
default:
if isLetter(l.ch)
tok.Literal = l.readIdentifier()
//看看变量名是否属于关键字
tok.Type = token.LookupIdent(tok.Literal)
return tok
else if isDigit(l.ch)
tok.Type = token.NUMBER
tok.Literal = l.readNumber()
return tok
else
tok = newToken(token.ILLEGAL, l.ch)
unc (l *Lexer) readNumber() string
position := l.position
for isDigit(l.ch)
l.readChar()
return l.input[position : l.position]
func isDigit(ch byte) bool
return '0' <= ch && '9' >= ch
完成以上代码后,我们当前所有测试都能通过,这也意味着着我们当前的工作已经能够对Python代码做初步的解析了。眼尖的同学可能会意识到一个问题,那就是在读取数字时,如果我们遇到非法的数字字符串例如“123abc",此时词法解析器会将其读作123和abc,这个问题在以后章节中我们再做处理。
完整代码请点击这里
https://github.com/wycl16514/go_python_lexer_1.git
以上是关于试用GO开发python编译器:实现词法解析的主要内容,如果未能解决你的问题,请参考以下文章