用沐神的方法阅读PyTorch FX论文
Posted just_sort
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用沐神的方法阅读PyTorch FX论文相关的知识,希望对你有一定的参考价值。
【GiantPandaCV导语】torch.fx对于PyTorch来说确实是一个比较好的工作,因为它消除了一些动态图和静态图的Gap。比如在图改写方面,torch.fx让PyTorch想做一些其它静态图框架的算子融合优化非常容易。并且torch.fx让后训练量化和感知训练量化以及AMP等的实现难度大大降低,这得益于我们可以直接在Python层操作这个IR,所以我认为这是一个不错的工作。尤其是对使用PyTorch开发的算法工程师来说,现在可以基于这个特性大开脑洞了。我之前围绕FX也做了一个QAT的工作,感兴趣可以阅读:基于OneFlow实现量化感知训练。torch.fx的卖点就是,它使用纯Python语言实现了一个可以捕获PyTorch程序的计算图并转化为一个IR的库,并且非常方便的在这个IR上做Pass,同时提供将变换后的IR Codegen合法的Python代码功能。我觉得算是达到了在Eager下写Pass就像做链表插入删除题目一样顺滑。
0x0. 动机
最近沐神在B站上分享了一些经典论文的阅读视频,我也跟着看了几个比如TransFormer,VIT等,很赞。所以我就想试试沐神这种论文阅读方法,找一篇论文来阅读一下。目前我比较关注的是工程方向的论文,正好上周PyTorch 放出了torch.fx的论文,所以我就以这篇论文为例来试试。沐神的论文阅读方法大概是这样(数字代表先后顺序):
- 标题
- 摘要
- 引言
- 结论
- 相关工作
- FX特性
- 实验
- 评论
PyTorch FX论文的链接在:https://arxiv.org/pdf/2112.08429.pdf 。下面我就以沐神的论文阅读顺序来分享一下阅读体验,帮助大家搞清楚PyTorch FX这个特性到底是什么,以及它可以在PyTorch中发挥什么作用。
0x1. 标题

我们可以这样进行翻译:TORCH.FX:基于Python的深度学习实用程序捕获和变换。这个基于Python的深度学习实用程序这里就可以理解为基于PyTorch开发的模型程序了,然后这里的重点是捕获和变换。现在还不清楚这里的捕获和变换是什么意思,我们可以接着往下读。插一点言外话,我半年前就有关注FX,之前在OneFlow框架下也成功接入了FX并且做了一个QAT的任务,而那个时候FX还是没有论文的,所以我感觉这篇论文更像是一个对TORCH.FX这个特性的总结以及占位的那种感觉。
0x2. 摘要
摘要部分简单指明了像PyTorch这种基于动态图执行模式的深度学习框架虽然提升了用户的易用性。但是在一些真实场景中,用户可能是需要捕获和变换程序结构(也可以直接理解为神经网络的结构)来进行性能优化,可视化,分析和硬件调优等。为了解决这个痛点,PyTorch设计了torch.fx这个模块来做PyTorch程序的捕获和变换,这个模块是纯Python开发的。
这一节主要是讲了一下torch.fx的卖点,就是说动态图虽然易用性很强,但是图结构不能被提前感知和变换,但通过这篇论文的torch.fx模块,这件事就成啦!
0x3. 引言
早期的图模式或者叫define-and-run的静态图框架有Caffe,TensorFlow等,它们设计了一个表示图的IR,用户通过调用这些框架提供的API来构建IR。然后我们可以在这个IR上做程序微分,将IR切分到设备上实现并行,量化,性能优化等等。但这些事情一般都要求开发者在领域特定的语言上去做,比如以OneFlow的静态图模式为例,要做图切分,量化,性能优化等都需要基于C++去开发,并且调试也会相对比较难(要借助pdb,gdb等等专业工具)。
现在的eager模式或者叫define-by-run的动态图框架有PyTorch,TensorFlow Eager模式等,它们可以随心所欲的让用户基于脚本语言编程并且可以解决大多数的训练(基于自动微分)和预测任务。但是有一些变换比如量化和算子融合 是不能直接做的,而这一点在静态图模式下则很简单。为了消除这种Gap,动态图框架需要一种从用户的程序捕获图结构的方法来使能这些变换。
实际上,这种程序捕获技术在PyTorch中早就有了,那就是TorchScript,它基于Python程序的AST来构造IR,对整个Python程序进行全面建模。但这样做仍存在一个问题,那就是程序捕获的技术复杂性太大,并且在这个高复杂性的IR上写变换太难了。作为对比,我们可以将需求简化一下,从全面建模Python程序变成只需要建模到可以做量化和算子融合等变换即可。要做到这两件事,我们其实只需要程序中的那个DAG结构就可以了,而不需要程序中隐藏的更高层的API的结构(比如卷积和BN),这句话的意思就是说我们可以不关注卷积和BN这种可能由多种操作拼出来的nn.Module,我们在他的上层进行截断就行,即最后获得了一个high-level API的DAG。
基于上面的思路,torch.fx被提出,它关注深度学习程序中的DAG并且提供了定制接口来获取这个DAG。这样torch.fx就可以实现大多数深度学习框架中的图变换,同时还提供了一套简单易用的APIs来帮助用户自定义变换。总结一下,torch.fx的核心卖点是:
- 对深度学习程序很重要的程序捕获和转换的实用分析特性。Trace
- 一个仅用Python实现的程序捕获库,可以进行定制以捕获不同级别的程序细节。 Pure Python
- 一个简单的只有 6 条指令的 IR,用于表示捕获的程序,重点是易于理解和易于进行静态分析。 IR
- 用于将变换后的代码返回到宿主语言生态系统的代码生成系统。Codegen
- 关于如何在实践中使用 torch.fx 开发性能优化、程序分析、设备lowering等功能的案例研究。 Eager Pass
0x4. 结论
我们提出了torch.fx,这是一个用于捕获和转换PyTorch程序的纯Python系统。我们分析了使相关系统复杂化的因素,包含控制流,可变性和数据模型,并展示了 torch.fx 如何通过关注常见用例和可定制性来避免复杂性。 我们在优化、分析和设备lowering方面调查了 torch.fx 的各种用例,并展示了 torch.fx 的 API 设计如何实现这些结果。
0x5. 相关工作
在捕获和变换程序时,eager和graph模式的深度学习框架都必须在捕获程序结构、程序特化和保存程序的IR的设计方面做出选择。 这些选择的组合决定了可在框架中表示的程序空间、编写变换的难易程度以及生成的变换程序的性能。 一般来说,支持程序的高性能运行需要更复杂的捕获框架和IR,从而使转换更难编写。每一段相关工作我就不详细过了,只描述每一段工作的核心是在说什么,相关细节大家可以查看原始论文。
0x5.1 捕获程序结构
这一节提到了PyTorch的jit.trace,MxNet Gluon,TensorFlow的tf.function等程序捕获方法,并指出这些方法只能处理Python的一些子集。然后,TorchScript通过在AST上分析可以处理控制流和更多的Python语法。然后还提了一下Julia和Swift For TensorFlow中将捕获程序结构的接口集成到了非Python的宿主语言中,要使用的话需要用户放弃Python生态系统。
0x5.2 特化程序
对于a+b这个Python语句来说,这个表达式对a和b的类型没有限制。但当深度学习框架捕获程序时一般会对这两个变量进行特化,以便它们只对特定类型或者张量有效。在深度学习框架中处理的大多数程序都是特化类型的程序,特化程度越高,能够处理的输入就越少。例如torch.jit.trace在执行trace的时候只能处理某些拥有合法输入shape的输入。接下来还讨论了LazyTensor和Jax的jit来说明为了更好的处理特化程序中捕获的失败,它们做了哪些努力。
0x5.3 IR设计
深度学习框架都有自己的IR设计,Caffe和TensorFlow使用Protocol Buffers格式。而PyTorch和MxNet使用C++数据结构来表示IR并额外绑定到Python。这些IR设计在runtime阶段表现都会比较好并且可以统一被序列化。但从另外一个角度来说,这些IR表示相比于纯Python语言的表示都需要更高的学习成本。接下来,这一节讨论了控制流和状态的问题,用来表明要处理这些问题需要设计较为复杂的IR以及要基于这个IR做较为复杂的分析才行。
基于上面几点,论文提出了torch.fx的基本设计原则:
- 避免支持长尾分布,复杂的样例。主要关注经典模型的程序捕获和变换。
- 使用机器学习从业者已经熟悉的工具和概念,例如Python的数据结构和 PyTorch 中公开记录的算子 。
- 使程序捕获过程具有高度可配置性,以便用户可以为长尾需求实现自己的解决方案。
这一节主要对一些相关工作进行了展开,以此来突出torch.fx的核心卖点,就是说我虽然不能像TorchScript这样的IR处理一些比较难的Case(比如动态控制流),但是我在神经网络这个领域里做得够用就可以了。最关键的是我的实现很简单,是纯Python的库,这样用户写变换就会很简单,学习成本会很小并且易用。(简单不代表不强大!
0x6. FX特性
以简单为基本原则,torch.fx通过符号跟踪来捕获程序,并通过一个简单的6个指令的IR来表示它们,并基于这个IR重新生成Python代码来运行它。为了避免JIT特化中的重捕获的复杂性,torch.fx没有对程序本身进行特化,而是依靠变换来决定在捕获期间需要实现哪些特化。用户也可以配置符号跟踪的过程来实现自定义捕获需求。
Figure1给我们展示了使用torch.fx.symbolic_trace捕获程序的例子,输入可以是一个torch.nn.Module或者函数,并且捕获之后的结构被存在一个Graph对象里面。该Graph对象和GraphModule中的模块参数相结合,GraphModule是 torch.nn.Module 的子类,其 forward 方法运行捕获的 Graph。 我们可以打印此图的Nodes以查看捕获的 IR。 placeholder节点表示输入,单个output节点表示Graph的结果。 call_function 节点直接引用了它将调用的 Python 函数。 call_method 节点直接调用其第一个参数的方法。 Graph 被重组为 Python 代码(traced.code)以供调用。

Figure2展示了使用 torch.fx 进行变换的示例。 变换是找到一个激活的所有实例并将它们替换为另一个。在这里,我们使用它来将gelu 替换 relu。

0x6.1 程序捕获
torch.fx的符号跟踪机制使用一个Proxy数据结构来记录给定一个输入之后经过了哪些Op。Proxy是一个duck-typed类型的Python类记录了在它之上的的属性访问和调用方法,是程序中真实Op的上层抽象。duck-typed可以看一下这里的介绍:https://zh.wikipedia.org/wiki/%E9%B8%AD%E5%AD%90%E7%B1%BB%E5%9E%8B 。PyTorch的算子以及Python子集的某些函数都会被这个Proxy包装一次,然后在符号跟踪传入的是一个nn.Module时,会对这个nn.Module中的子nn.Module也进行Proxy包装,当然还包含输入数据。这样程序中的输入和其它Op都是duck-typed类型的Proxy对象,我们就可以执行这个程序了,也就是符号跟踪的过程。符号跟踪的过程通过一个Tracer类进行配置,它的方法可以被重写以控制哪些值被作为Proxy对象保留,哪些值被unpack。(Proxy记录下来的Op可以进行unpack,unpack之后可以拿到真实的Tensor, Parameter和运算符等等)。通过Proxy和Tracer类的配合,torch.fx就可以完成PyTorch程序的符号跟踪,需要注意的是这里的符号跟踪的意思就是运行一遍这个被代理之后的nn.Module的forward。
0x6.2 中间表示
torch.fx的中间表示(IR)由一个Python数据结构Graph来做的。这个Graph实际上是一个包含一系列Node的线性表。节点有一个字符串操作码opcode,描述节点代表什么类型的操作(操作码的语义可以在附录 A.1 中找到)。 节点有一个关联的目标,它是调用节点(call_module、call_function 和 call_method)的调用目标。 最后,节点有 args 和 kwargs,在trace期间它们一起表示 Python 调用约定中的目标参数(每个opcode对应的 args 和 kwargs 的语义可以在附录 A.2 中找到)。 节点之间的数据依赖关系表示为 args 和 kwargs 中对其他节点的引用。
torch.fx 将程序的状态存储在 GraphModule 类中。 GraphModule 是转换程序的容器,暴露转换后生成的代码,并提供 nn.Module 类似的参数管理APIs。 GraphModule 可以在任何可以使用普通的 nn.Module 的地方使用,以提供转换后的代码和PyTorch 生态系统的其余部分之间的互操作性。
0x6.3 源对源的变换
torch.fx 变换pipline的最后阶段是代码生成。 torch.fx 并不是退出 Python 生态系统并进入定制的运行时,而是从变换后的 IR 生成有效的 Python 源代码。 然后将此变换后的代码加载到 Python 中,生成一个可调用的 Python 对象,并作为forward方法安装在 GraphModule 实例上。 使用代码生成允许将 torch.fx 变换的结果安装在模型中并用于进一步的变换。 例如,在图3中,我们拿到trace原始程序的结果并将其安装为新模块中的激活函数。

到这里PyTorch FX特性就精读完了,但查看FX的论文可以发现还有一节叫作Design Decisions,分别介绍了Symbolic Tracing,Configurable Program Capture,AoT Capture without Specialization,Python-based IR and Transforms等等FX实现中依赖的一些想法和 决策,以及它们的好处等。我理解这一节就是Introduction的加强版,所以就不继续讲解这一小节了,如果你担心会错过什么细节知识可以阅读论文原文。
0x7. 实验
torch.fx的一个目标就是简化深度学习模型产生的IR,下面的Figure5以ResNet50为例展示了TorchScript IR和torch.fx IR的差别,相比于TorchScript IR,torch.fx IR确实简单并且可读性更强。

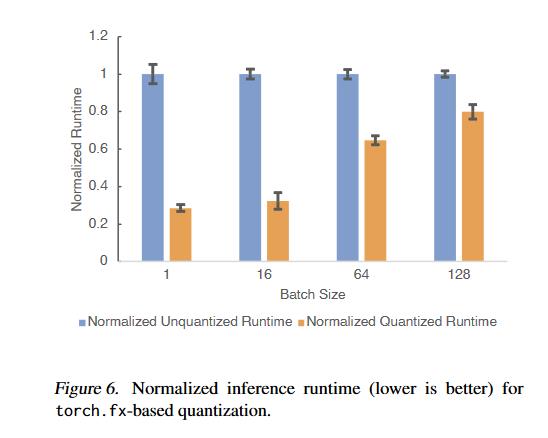
我们知道后量化以及量化感知训练可以提示程序推理时的性能,下面的Figure6就展示了基于torch.fx实现的后量化(使用FBGEMM量化算子)应用在DeepRecommender模型之后,在Intel Xeon Gold 6138 CPU @2.00GHz上的性能表现。基于torch.fx实现的后量化模型推理速度相比float类型的模型要高3.3倍。并且基于torch.fx实现量化操作相比基于TorchScript IR要简单很多。
torch.fx还可以做Op融合,Figure7展示了基于torch.fx做了Conv+BN融合后应用在ResNet50上,在n NVIDIA Tesla V100-SXM2 16GB with CUDA version 11.0 和 Intel Xeon Gold 6138 CPU @ 2.00GHz的性能表现,可以看到在GPU上减少了约6%的latency,在CPU上减少了约40%的latency(多线程)和约18%的latency(单线程)。

除此之外torch.fx还可以应用在FLOPs计算,内存带宽使用分析,工作负载的数据值大小估计等,用来分析程序运行时的内存和速度。torch.fx还可以用在形状推断,以及模型对应的DAG可视化作图等等。
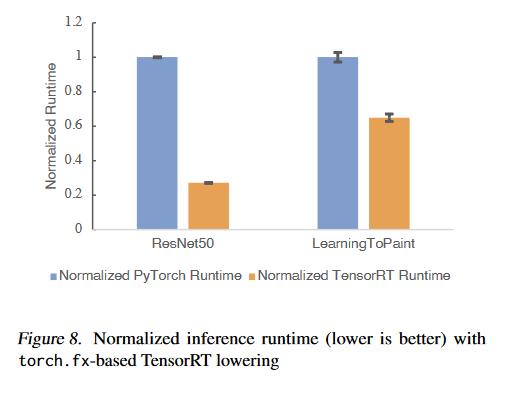
最后,torch.fx在runtime阶段还支持通过ASIC加速(即将torch.fx中的算子lowering到对应的ASIC上),下面的Figure8展示了基于torch.fx推理ResNet50和LearningToPaint并将算子lowering到TensorRT之后的加速情况:
0x8. 评论
torch.fx对于PyTorch来说确实是一个比较好的工作,因为它消除了一些动态图和静态图的Gap。比如在图改写方面,torch.fx让PyTorch想做一些其它静态图框架的算子融合优化非常容易。并且torch.fx让后训练量化和感知训练量化以及AMP等的实现难度大大降低,这得益于我们可以直接在Python层操作这个IR,所以我认为这是一个不错的工作。尤其是对使用PyTorch开发的算法工程师来说,现在可以基于这个特性大开脑洞了。我之前围绕FX也做了一个QAT的工作,感兴趣可以阅读:基于OneFlow实现量化感知训练。
最后总结一下,torch.fx的卖点就是,它使用纯Python语言实现了一个可以捕获PyTorch程序的计算图并转化为一个IR的库,并且非常方便的在这个IR上做Pass,同时提供将变换后的IR Codegen合法的Python代码功能。我觉得算是达到了在Eager下写Pass就像做链表插入删除题目一样顺滑。
沐神的论文阅读方法,感觉确实比较科学,文章末尾再赞一次。
以上是关于用沐神的方法阅读PyTorch FX论文的主要内容,如果未能解决你的问题,请参考以下文章