IDC网络传输新方法-流体渗透原理
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IDC网络传输新方法-流体渗透原理相关的知识,希望对你有一定的参考价值。
IDC网络传输,本周再开一个脑洞。
学过计算机网络这门课程后,反被迷惑。试着回答下图中的两个问题:
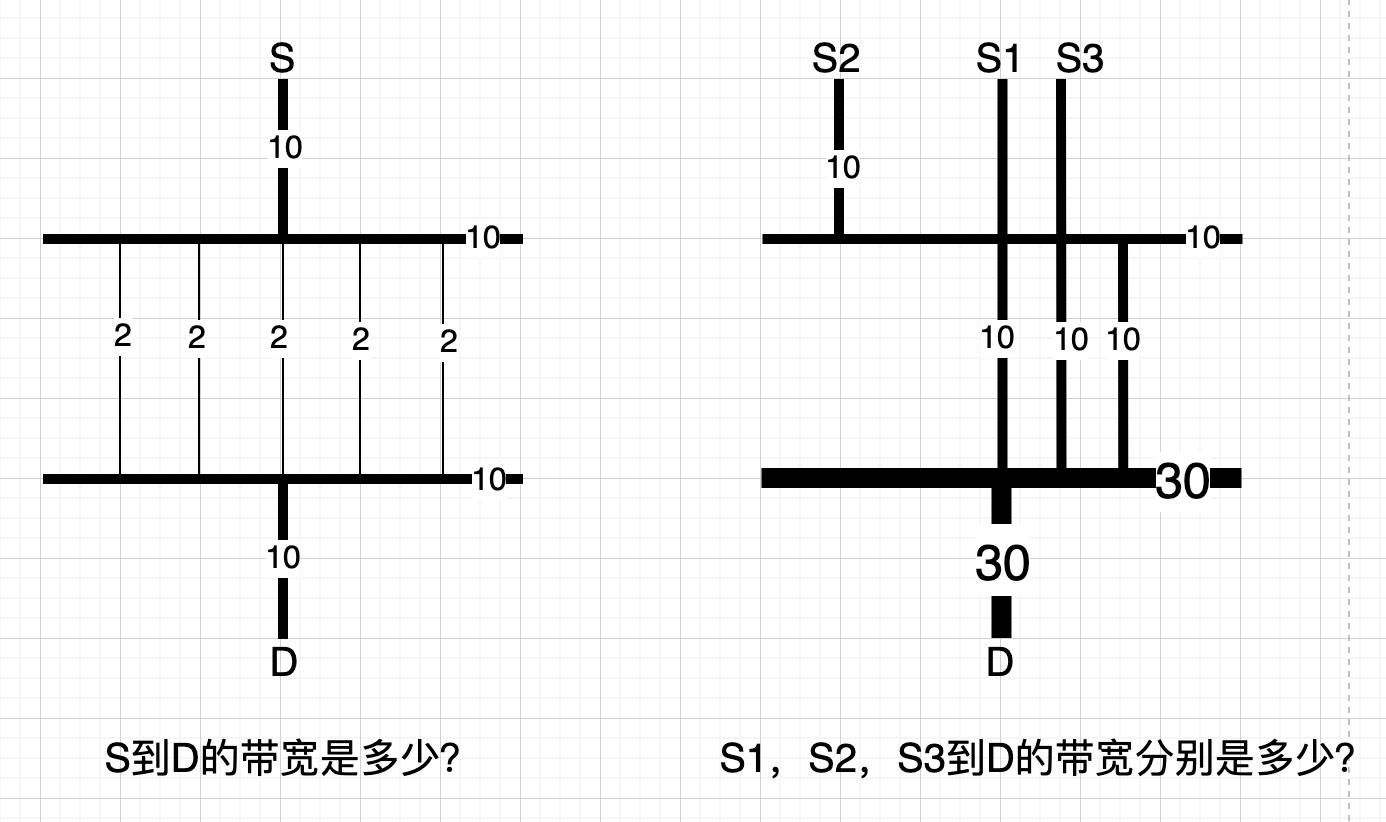
数字表示带宽,黑线表示连接,黑线之间的交点表示交换机。
图画成上面这个样子是为了揭示常识,答案很明确:
- 左图的答案是10。
- 右图的答案是10。
但是如果学过计算机网络,便不会轻易下结论了,虽然按常识理解,答案很明确,但总觉得违背了些什么真理。
几乎没有任何路由协议会生成上述答案,因为上述答案违背了最短路径优先。内中一些细节暂时搁下,来看些现实的例子。
水往低处流,这是常识,水从山顶流下时,会选择什么样的路径呢?
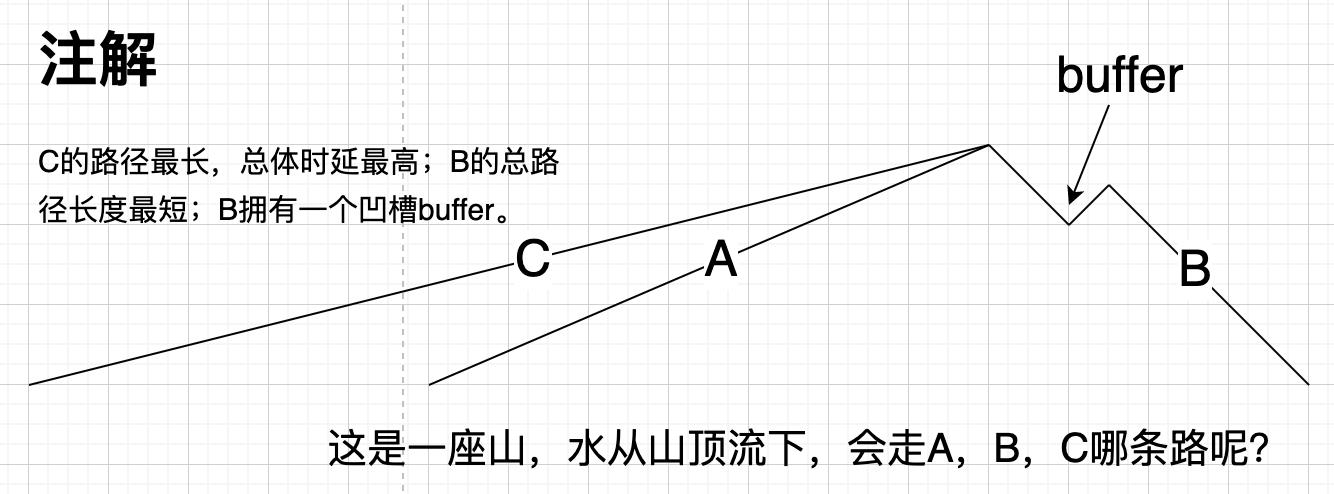
上图所示,显然B比A要短,但流水不会首先从B流下,在水从B流下之前,那个buffer首先要被充满。B是最短路径,但水流追求的不是最短路径,而是永远流动。只要水流不会被阻滞,那么它就会选择这条路径。这就是流体渗透的原理。
江河泛滥是最现实的例子,洪水总是以最高的效率将村庄城市淹没。
下面是一个模拟的例子:
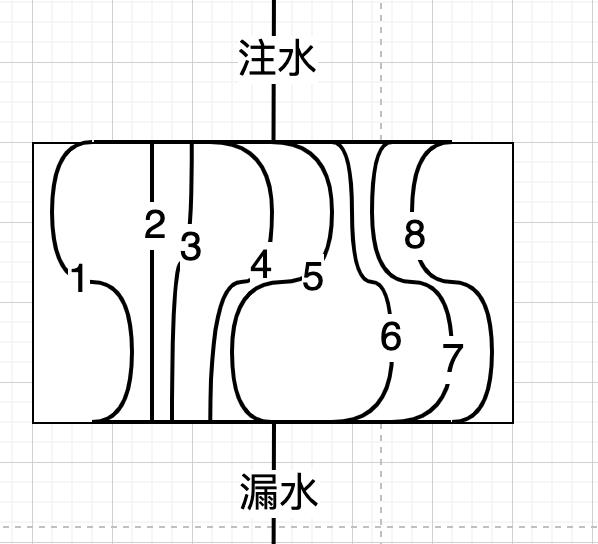
1~8是8根管子,流体可以从中流过。除了模拟江河泛滥,这个装置还可以传输沙子和小米,绿豆:
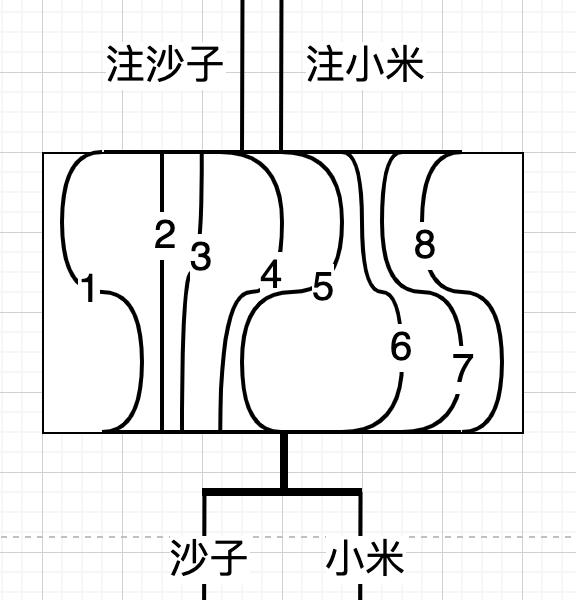
也可以传输数据!
无论是传输洪水,沙子,小米或数据,所有的管子都应完全被填充,整个装置才会被最大限度利用,换句话说,这些管子整体上要被看作资源池。
若要高效传输数据,数据要充满网络,而不是仅从一条路径通过。这是一个流体扩散模型。
考虑下面的拓扑:
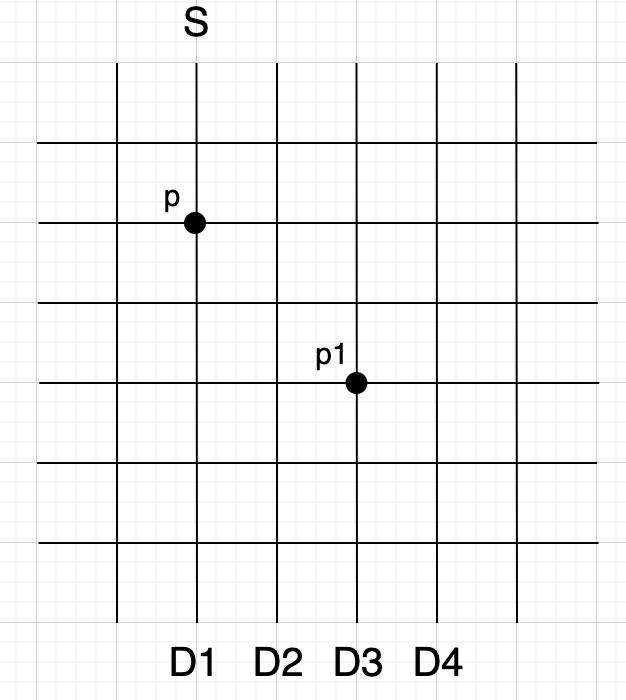
这是一个适用于IDC网络的规则拓扑,对每一个交换节点,以p为例,其每一个port均附着一张二维表,表中每一个元素均为从特定端口到达特定目的地的开销:
| p点上端口 | 上 | 下 | 左 | 右 |
|---|---|---|---|---|
| S | 100000 | 100000 | 100000 | 100000 |
| D1 | 100000 | 1 | 2 | 2 |
| D2 | 100000 | 1 | 2 | 1 |
| D3 | 100000 | 1 | 2 | 1 |
| D4 | 100000 | 1 | 2 | 1 |
请试着填写p1点左端口的二维表。它就是普通的路由表,但是并没有彻底断送次优,第三优,第四优等路由的机会。
每一个交换节点的每一个端口的该表可以在拓扑确定后手动静态绘制,也可以通过动态路由协议来自动学习和收敛,以适应拓扑的变化。
可以不断摘除最优路径(度量无穷大)从而用路由算法迭代出次优,第三,第四,…优选路由。
若仅按上述路由原则,数据依然无法充满整个网络,现加入排队开销,依然以上表为例。假设p点的下端口有排队,就在原静态开销的基础上增加一个动态开销,它是队列长度的函数:
w ( l ) = f ( l ) w(l)=f(l) w(l)=f(l)
| p点上端口 | 上 | 下 | 左 | 右 |
|---|---|---|---|---|
| S | 100000 | 100000 | 100000 | 100000 |
| D1 | 100000 | 1+ w w w | 2 | 2 |
| D2 | 100000 | 1+ w w w | 2 | 1 |
| D3 | 100000 | 1+ w w w | 2 | 1 |
| D4 | 100000 | 1+ w w w | 2 | 1 |
S到达D1的数据包本应从下端口发出,若该端口排队开销 w w w大于1,那么它将从左口或右口发出。为消除随机性,可在权重相等的情况下人为引入优先级,比如:
- 右优先于左。
- 左右优先于上下。
这实现了数据包在网络的自动渗透。如果你想完全消除队列,就将函数
w
(
l
)
w(l)
w(l)定义猛烈一些。这是一个自动收敛的负反馈算法,一旦其它数据包由于发现排队而绕路,原本的队列便会消除,数据包又会回到静态最短路径,这对于抗突发是多么有益,丝毫不要端到端做任何事情。
…
但算法有个大缺陷:
- 如何应对乱序?
这个问题不值得讨论,因为我这么做的前提就是认为分组交换网的传输不负责保序。
保序的传输将不再是纯分组交换,它大大降低了存储转发的统计复用效率,这是TCP性能差的根源!保序和不保序的折中就是Flowlet.
那么这就是一个非常不错的算法了。是的。但是为什么不能在广域网推广?
回到山顶流水的例子,若C长到了一定程度,流水到达山底的时间将变久,换算成开销,直到它大于路径B的开销。
广域网相对IDC网络的不规则拓扑并不是主因,主因是广域网的传播开销相对排队开销不容忽视,绕路可能受损。
还是生活中的例子。
人们在城市里开车,遇到拥塞一般会从别的路绕开,但在高速公路遇到堵车,即便是有匝道也不会绕行,还是会等待。因为在城市中,即便多绕一倍的里程,对于节省时间也是有益的,对于高速,绕一跳的里程,至少也要几百公里。
总结一下,不合时宜。
为了满足路由协议最短路径约束,无视数据包堵在交换机,这是为了保持西装崭新而反穿西装的做法,这是为了保持皮鞋跟不歪而钉个铁掌的做法。但这只是其罪一。
即便是利用INT回传丰富的拥塞信息HPCC也依然是迟到的事后拥塞控制,对于突发依然无解,这是其罪二。
人们总寄希望于实时获取关于拥塞的信息,基于这些信息做拥塞控制,这不是真正管用的拥塞控制,BBR不管用,Remy不管用,PCC不管用,HPCC也不管用。这类似于你至多只能在出门前规划,一旦在路上遭遇拥塞,你将束手无策。
排除故障因素,拥塞几乎总是统计波动造成的,而统计波动本质上是独立事件到达率的波动,它无法预测,所谓的“拥塞控制”事实上是伪命题,真相是在统计复用系统上拥塞无法控制。
把整个IDC网络而非单条路径看做资源,并池化,采用流体渗透原理,可获得天然的最大带宽利用率。所以,IDC网络拥塞控制本质上还是资源调度。
那么广域网拥塞控制的本质是什么呢?我认为是选路,无论如何依然不是规划发送量。如果真的是选路,那和端到端拥塞控制原则相违背的,端到端显然无法选路,选路必须在中间节点进行,和IDC网络一样,这将带来一个复杂的网络中心,这和互联网的原则背道而驰。至于使用overlay是否能至少解决问题的一部分,那只是实现方式,并非问题的本质。但原则一定就正确吗?正确的就一定高效吗?这不是本文的主题。
这个思路可能违背很多协议,违背了很多设计原则,但对与错只是一个说法,并不重要,在对的面前,不一样的都是错的。
最后,出一个有意思的小题目:
- 经理走在一个无限大的方格子路网中,每一个十字街头有一个红绿灯,每一个红绿灯均保证一个方向是红灯另一个方向是绿灯,路网中任选两个点,问经理若希望一路绿灯到达目的地,最坏情况收敛吗?最好情况是什么?(这个问题和随机游走有关,但不是一回事,它的解就是本文算法的详细设计)
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于IDC网络传输新方法-流体渗透原理的主要内容,如果未能解决你的问题,请参考以下文章