R语言练习题
Posted Dream of Grass
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言练习题相关的知识,希望对你有一定的参考价值。
文章目录
- R语言练习题
- 第一题:合并不同数据类型的向量,并告诉我向量合并后的数据类型是什么。
- 第二题:x是-1到1之间均匀分布的长度为100的向量。请写程序定义一个关于x的分段函数y,满足: y = 1 − x , x < 0 1 + x , x ≥ 0 y=\\begincases1-x,\\quad x<0\\\\1+x,\\quad x\\ge0\\endcases y=1−x,x<01+x,x≥0
- 第三题:写程序定义变量ages,表示100个20~70岁的成年人年龄,并以每10岁作为区间,统计各个年龄段的人数。
- 第四题:写程序生成20×20的单位矩阵和对角线上分别为1:20的对角矩阵。
- 第五题:写程序生成如下矩阵 [ N A 9 17 25 3 N A 19 27 5 13 N A 29 7 15 23 N A ] \\left[\\beginarrayccccNA&9&17&25\\\\3&NA&19&27\\\\5&13&NA&29\\\\7&15&23&NA\\endarray\\right] ⎣⎢⎢⎡NA3579NA13151719NA23252729NA⎦⎥⎥⎤,并用apply命令按列进行求和。
- 第六题:利用R内部mtcars数据,计算mpg, cyl和hp列数据的长度(length)、平 均值(mean)及标准差(sd)。
R语言练习题
第一题:合并不同数据类型的向量,并告诉我向量合并后的数据类型是什么。
double <- c(1,2,3)
logical <- c(TRUE,FALSE,TRUE)
x <- 3
y <- 4
complex <- complex(re=x,im=y)
character <- c("ad","asfda","地方撒")
d_l <- c(double,logical);d_l;print("double and logical : ");typeof(d_l)
d_co <- c(double,complex);d_co;print("double and complex : ");typeof(d_co)
d_ch <- c(double,character);d_ch;print("double and character : ");typeof(d_ch)
l_co <- c(logical,complex);l_co;print("logical and complex : ");typeof(l_co)
l_ch <- c(logical,character);l_ch;print("logical and character : ");typeof(l_ch)
co_ch <- c(complex,character);co_ch;print("complex amd character : ");typeof(co_ch)
代码运行结果
[1] 1 2 3 1 0 1
[1] "double and logical : "
[1] "double"
[1] 1+0i 2+0i 3+0i 3+4i
[1] "double and complex : "
[1] "complex"
[1] "1" "2" "3" "ad"
[5] "asfda" "地方撒"
[1] "double and character : "
[1] "character"
[1] 1+0i 0+0i 1+0i 3+4i
[1] "logical and complex : "
[1] "complex"
[1] "TRUE" "FALSE" "TRUE" "ad"
[5] "asfda" "地方撒"
[1] "logical and character : "
[1] "character"
[1] "3+4i" "ad" "asfda" "地方撒"
[1] "complex amd character : "
[1] "character"
结论
由上面代码的运行结果可以知道:
数值型和逻辑型 = 数值型
数值型和复数型 = 复数型
数值型和字符型 = 字符型
逻辑型和复数型 = 复数型
逻辑性和字符型 = 字符型
复数型和字符型 = 字符型
通过上面的结论我们可以看到:
数值<逻辑<复数<字符
第二题:x是-1到1之间均匀分布的长度为100的向量。请写程序定义一个关于x的分段函数y,满足: y = 1 − x , x < 0 1 + x , x ≥ 0 y=\\begincases1-x,\\quad x<0\\\\1+x,\\quad x\\ge0\\endcases y=1−x,x<01+x,x≥0
x <- seq(-1,1,length=100)
print("x:")
x
y <- 1:100
# 要提前定义y
for(i in 1:100)
if(x[i]<0)
y[i] <- 1-x[i] else
y[i] <- 1+x[i]
print("y:")
y
代码运行结果
[1] "x:"
[1] -1.00000000 -0.97979798 -0.95959596 -0.93939394 -0.91919192 -0.89898990 -0.87878788
[8] -0.85858586 -0.83838384 -0.81818182 -0.79797980 -0.77777778 -0.75757576 -0.73737374
[15] -0.71717172 -0.69696970 -0.67676768 -0.65656566 -0.63636364 -0.61616162 -0.59595960
[22] -0.57575758 -0.55555556 -0.53535354 -0.51515152 -0.49494949 -0.47474747 -0.45454545
[29] -0.43434343 -0.41414141 -0.39393939 -0.37373737 -0.35353535 -0.33333333 -0.31313131
[36] -0.29292929 -0.27272727 -0.25252525 -0.23232323 -0.21212121 -0.19191919 -0.17171717
[43] -0.15151515 -0.13131313 -0.11111111 -0.09090909 -0.07070707 -0.05050505 -0.03030303
[50] -0.01010101 0.01010101 0.03030303 0.05050505 0.07070707 0.09090909 0.11111111
[57] 0.13131313 0.15151515 0.17171717 0.19191919 0.21212121 0.23232323 0.25252525
[64] 0.27272727 0.29292929 0.31313131 0.33333333 0.35353535 0.37373737 0.39393939
[71] 0.41414141 0.43434343 0.45454545 0.47474747 0.49494949 0.51515152 0.53535354
[78] 0.55555556 0.57575758 0.59595960 0.61616162 0.63636364 0.65656566 0.67676768
[85] 0.69696970 0.71717172 0.73737374 0.75757576 0.77777778 0.79797980 0.81818182
[92] 0.83838384 0.85858586 0.87878788 0.89898990 0.91919192 0.93939394 0.95959596
[99] 0.97979798 1.00000000
[1] "y:"
[1] 2.000000 1.979798 1.959596 1.939394 1.919192 1.898990 1.878788 1.858586 1.838384
[10] 1.818182 1.797980 1.777778 1.757576 1.737374 1.717172 1.696970 1.676768 1.656566
[19] 1.636364 1.616162 1.595960 1.575758 1.555556 1.535354 1.515152 1.494949 1.474747
[28] 1.454545 1.434343 1.414141 1.393939 1.373737 1.353535 1.333333 1.313131 1.292929
[37] 1.272727 1.252525 1.232323 1.212121 1.191919 1.171717 1.151515 1.131313 1.111111
[46] 1.090909 1.070707 1.050505 1.030303 1.010101 1.010101 1.030303 1.050505 1.070707
[55] 1.090909 1.111111 1.131313 1.151515 1.171717 1.191919 1.212121 1.232323 1.252525
[64] 1.272727 1.292929 1.313131 1.333333 1.353535 1.373737 1.393939 1.414141 1.434343
[73] 1.454545 1.474747 1.494949 1.515152 1.535354 1.555556 1.575758 1.595960 1.616162
[82] 1.636364 1.656566 1.676768 1.696970 1.717172 1.737374 1.757576 1.777778 1.797980
[91] 1.818182 1.838384 1.858586 1.878788 1.898990 1.919192 1.939394 1.959596 1.979798
[100] 2.000000
第三题:写程序定义变量ages,表示100个20~70岁的成年人年龄,并以每10岁作为区间,统计各个年龄段的人数。
options(digits=1)
ages <- runif(100,20,70)
print("ages:")
ages
ages_factor <- cut(ages,breaks=c(19,30,40,50,60,70))
table(ages_factor)
代码运行结果
[1] "ages:"
[1] 64 52 56 28 52 67 27 56 38 34 55 50 61 55 56 57 46 24 23 48 66 52 46 27 55 37 60 50 35
[30] 36 26 45 52 64 50 49 62 43 46 30 58 56 23 26 54 25 68 50 31 58 65 62 51 28 38 53 49 56
[59] 55 53 20 65 31 37 55 54 38 53 26 63 24 21 20 53 38 31 40 64 40 24 38 22 60 55 44 31 70
[88] 54 28 27 48 69 39 27 26 21 24 51 54 34
ages_factor
(19,30] (30,40] (40,50] (50,60] (60,70]
23 18 14 30 15
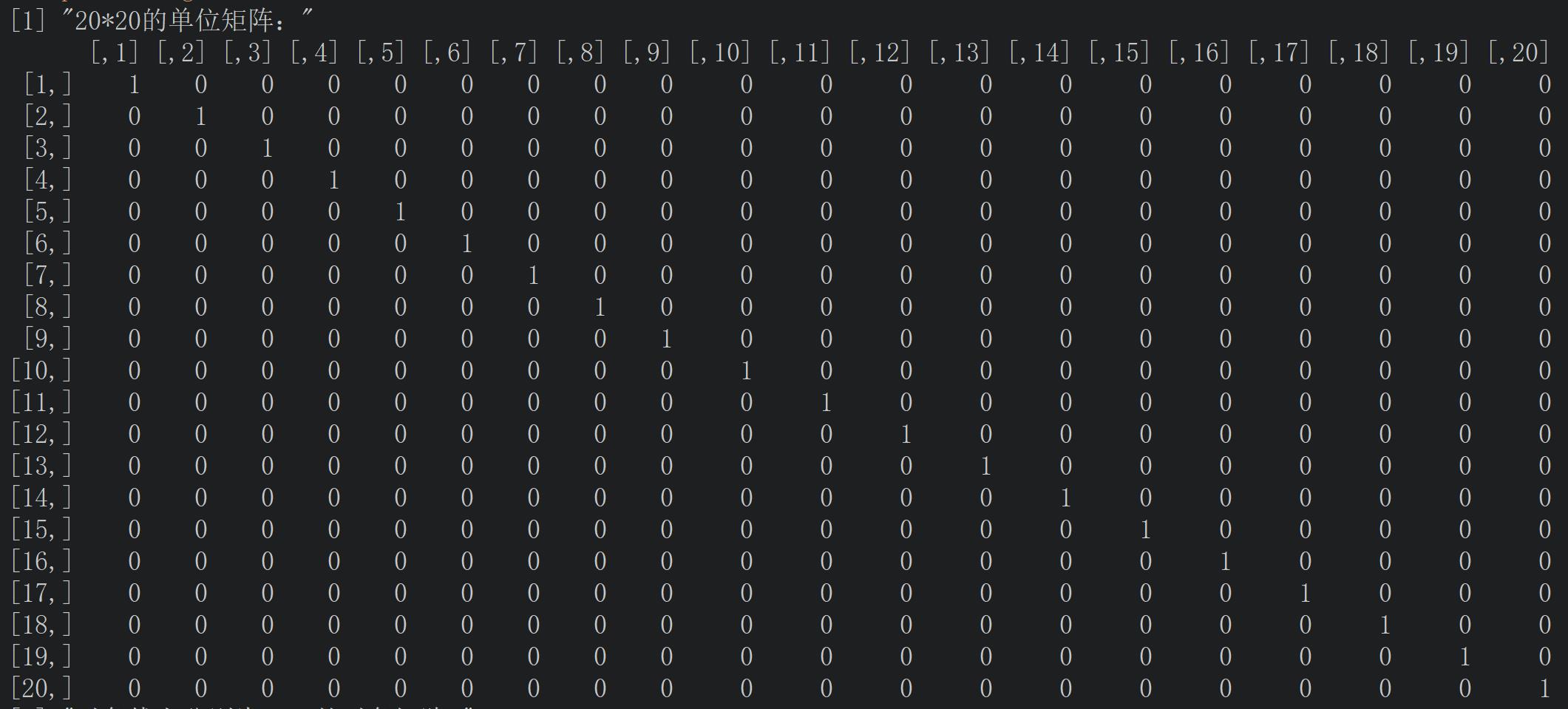
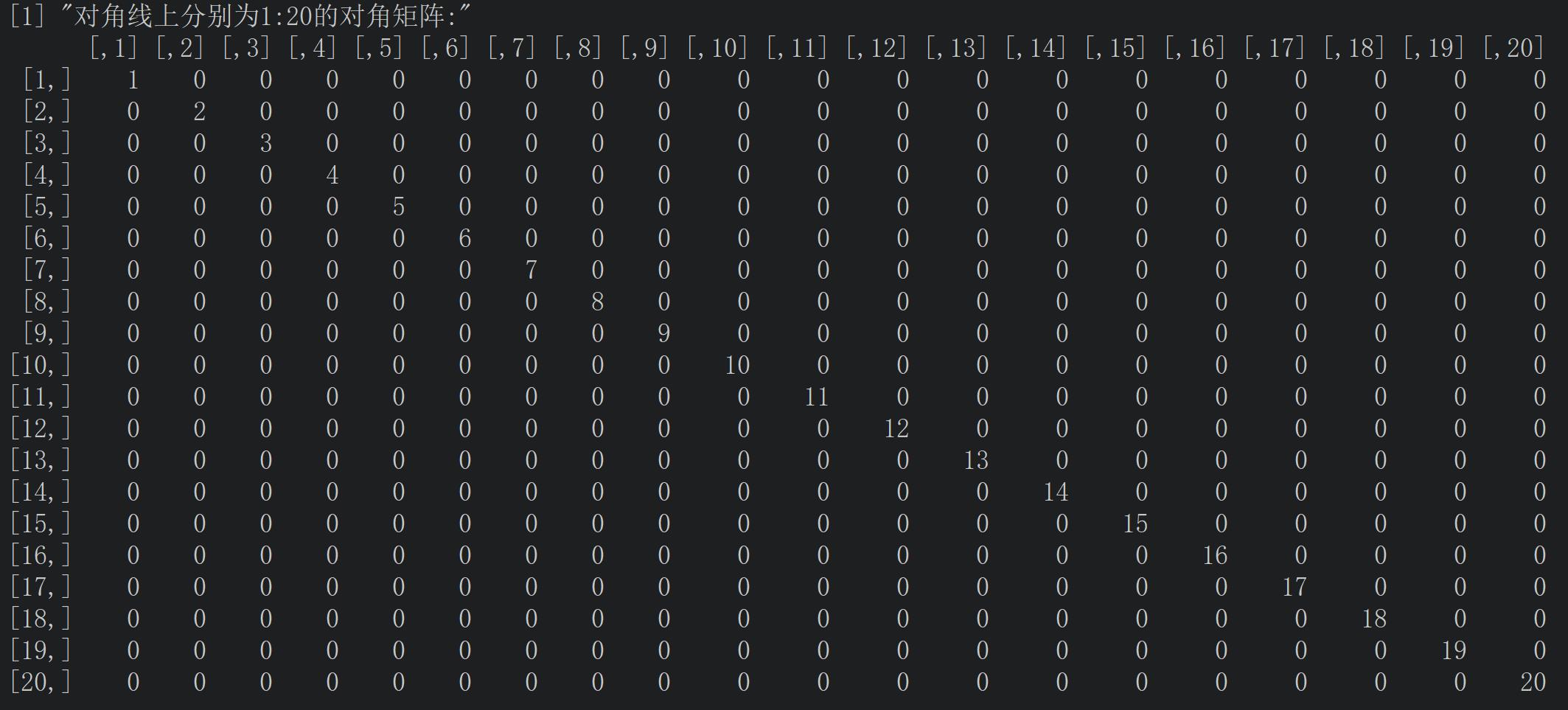
第四题:写程序生成20×20的单位矩阵和对角线上分别为1:20的对角矩阵。
eye <- diag(20)
print("20*20的单位矩阵:")
eye
eye_special <- diag(1:20,20)
print("对角线上分别为1:20的对角矩阵:")
eye_special
代码运行结果
第五题:写程序生成如下矩阵 [ N A 9 17 25 3 N A 19 27 5 13 N A 29 7 15 23 N A ] \\left[\\beginarrayccccNA&9&17&25\\\\3&NA&19&27\\\\5&13&NA&29\\\\7&15&23&NA\\endarray\\right] ⎣⎢⎢⎡NA3579NA13151719NA23252729NA⎦⎥⎥⎤,并用apply命令按列进行求和。
num <- seq(1,31,by=2)
f_m <- matrix(num,4)
f_m
i=1
for(i in 1:4)
f_m[i,i]=NA
print("要求的矩阵")
f_m
apply(f_m,2,sum,na.rm=T)
代码运行结果
[,1] [,2] [,3] [,4]
[1,] 1 9 17 25
[2,] 3 11 19 27
[3,] 5 13 21 29
[4,] 7 15 23 31
[1] "要求的矩阵"
[,1] [,2] [,3] [,4]
[1,] NA 9 17 25
[2,] 3 NA 19 27
[3,] 5 13 NA 29
[4,] 7 15 23 NA
[1] 15 37 59 81
第六题:利用R内部mtcars数据,计算mpg, cyl和hp列数据的长度(length)、平 均值(mean)及标准差(sd)。
print("mpg列数据的长度")
length(mtcars$mpg)
print("cyl列数据的长度")
length(mtcars$cyl)
print("hp列数据的长度")
length(mtcars$hp)
print("mpg列数据的平均值")
mean(mtcars$mpg)
print("cyl列数据的平均值")
mean(mtcars$cyl)
print("hp列数据的平均值")
mean(mtcars$hp)
print("mpg列数据的标准差")
sd(mtcars$mpg)
print("cyl列数据的标准差")
sd(mtcars$cyl)
print("hp列数据的标准差")
sd(mtcars$hp)
代码运行结果
[1] "mpg列数据的长度"
[1] 32
[1] "cyl列数据的长度"
[1] 32
[1] "hp列数据的长度"
[1] 32
[1] "mpg列数据的平均值"
[1] 20
[1] "cyl列数据的平均值"
[1] 6
[1] "hp列数据的平均值"
[1] 147
[1] "mpg列数据的标准差"
[1] 6
[1] "cyl列数据的标准差"
[1] 2
[1] "hp列数据的标准差"
[1] 69
以上是关于R语言练习题的主要内容,如果未能解决你的问题,请参考以下文章