MindSpore联邦学习框架解决行业级难题
Posted 华为移动服务
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MindSpore联邦学习框架解决行业级难题相关的知识,希望对你有一定的参考价值。
内容来源:华为开发者大会2021 HMS Core 6 AI技术论坛,主题演讲《MindSpore联邦学习框架解决隐私合规下的数据孤岛问题》。
演讲嘉宾:华为MindSpore联邦学习工程师
大家都知道,人工智能的发展离不开广泛的数据支撑。数据是基础,也是关键。但行业中小规模、碎片化,亦是大规模、高质量的数据都很难获取,涉及到工程、监管和隐私合规多方面的问题。这也就导致人工智能产业面临数据孤岛挑战,比如企业获得用户数据越来越难、企业内不同部门数据难合作、同行业企业数据难以共享、跨行业数据难以发挥价值等。

联邦学习:打破数据孤岛,建立新一代的技术生态
面对数据孤岛,人工智能应该怎样发展呢?联邦学习是一个能够确保数据隐私合规及模型性能的有效解决方案。
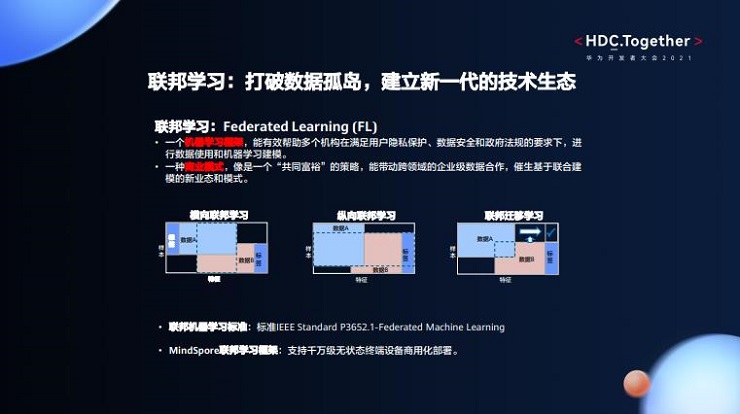
联邦学习最早由谷歌在2016年提出,一方面它是一个机器学习框架,能够有效帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。另一方面,联邦学习也是一种商业模式,更像是“共同富裕”的策略,能够带动跨领域的企业级数据合作,催生基于联合建模的新业态、新模式。
一般业内将联邦学习分为横向联邦学习、纵向联邦学习和联邦迁移学习三种。横向联邦学习适用于用户重叠较少,数据特征重叠较多的场景,比如谷歌最早应用在智能手机输入法联合建模上;纵向联邦学习适用于用户重叠较多,数据特征重叠较少的场景,比如一些业务垂直性强的行业;对于用户重叠和数据特征重叠都比较少的场景,我们则可以采用联邦迁移学习来建模。
那么,联邦学习在落地企业级应用时,一般会遇到哪些挑战呢?
首先是隐私安全。当前联邦学习还存在较多的安全隐患,例如投毒攻击、对抗攻击以及隐私泄露等。
其次是模型准确性。在安全业务下的样本不均衡、缺少数据标签等问题,会导致联邦聚合的效果不理想。另外,自动驾驶、医疗等行业的应用对模型精度也提出了更高的要求。
再次是通信效率。当面临千万级大规模异构终端部署时,需要应对网络不稳定、负载突变等复杂场景。大量本地模型更新的上传会对通信网络造成巨大的带宽负担。压缩算法虽然能够显著降低通信数据大小,但会严重影响模型精度。通信效率和模型精度之间的平衡成为较大挑战。
MindSpore联邦学习框架:端云协同,全场景统一架构
2021年6月,联邦学习框架开源。MindSpore联邦学习框架专注于横向联邦学习,支持千万级大规模异构终端部署场景,提供高性能、高可用的分布式联邦聚合计算。在隐私安全方面,数据不出设备,就可以完成本地训练。模型参数上传之前,我们还会提供多方安全计算,进行加密。在联邦效率提升方面,我们提供同步和异步两种联邦模式。此外,MindSpore联邦学习框架灵活易用,一行代码就可以切换单机训练与联邦学习模式。下面,我将从三个维度详细介绍MindSpore联邦学习框架的核心技术——
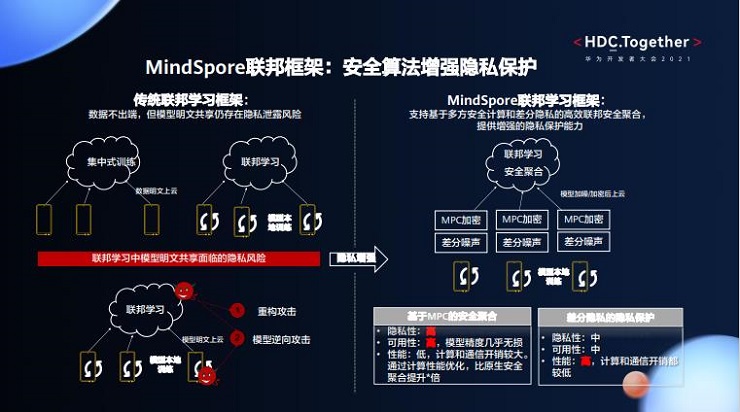
1、 安全算法增强隐私保护。传统联邦学习框架虽然数据不出端,但模型明文共享仍存在隐私泄露风险。MindSpore联邦学习框架支持基于多方安全计算和差分隐私的高效联邦安全聚合,增强了隐私保护能力。目前,这两种算法各有优势,开发者可以结合具体的应用场景选择。
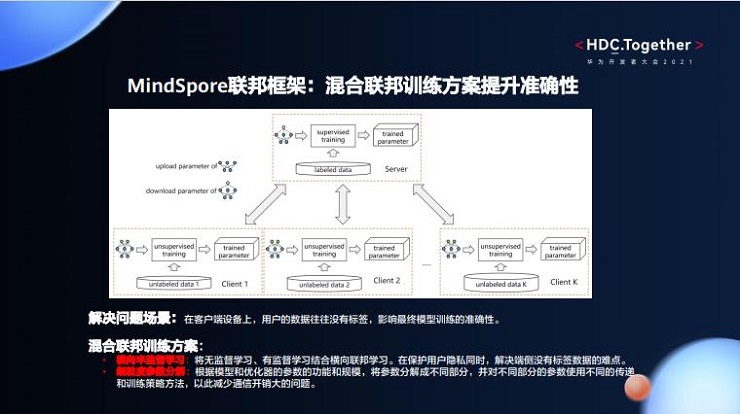
2、 混合联邦训练方案提升准确性。在实际应用场景中,用户数据在客户端设备上往往没有标签,影响最终模型训练的准确性。对此,我们提供一种混合联邦训练方案,分为横向半监督学习和细粒度参数分解两种。前者将无监督学习、有监督学习结合横向联邦学习,在保护用户隐私的同时解决端侧没有标签数据的痛点;后者则根据模型和优化器的参数功能和规模,将参数分解成不同部分,再对其使用不同的传递和训练策略及方法,减少通信开销大的问题。
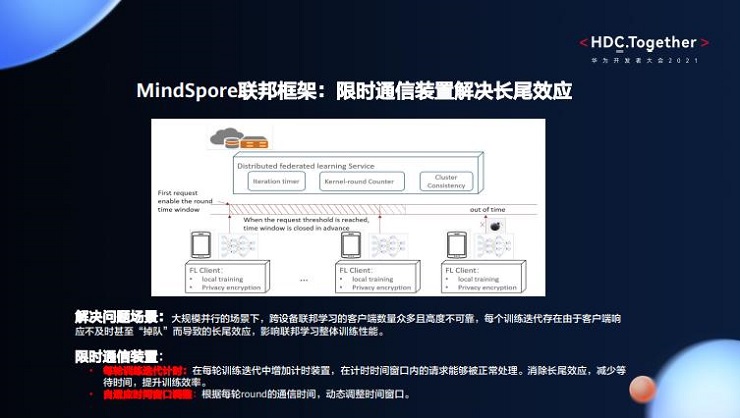
3、 限时通信装置解决长尾效应。在大规模并行的场景下,跨设备联邦学习的客户端数量众多且高度不可靠,因此每个训练迭代存在客户端响应不及时甚至“掉队”而导致的长尾效应,继而影响联邦学习整体训练性能。对此,我们提供限时通信装置。在每轮训练迭代中增加计时装置 ,保证计时时间窗口内的请求可以被正常处理,消除长尾效应,减少等待时间,提升训练效率。另外,时间窗口可以根据实际情况进行动态调整。
MindSpore联邦学习框架的两个应用场景
MindSpore联邦学习框架适用于终端广告的个性化推荐场景。传统的广告场景会面临许多问题与挑战,比如用户画像上,云侧无法获取手机端更丰富的特征;隐私合耦上,由于GDPR等法案对用户数据的管控,数据无法上传至中央服务器,导致传统链路无法打通;推荐效率上,从广告请求到最终广告展示需要经过诸多环节,这需要强大的工程架构来提高服务的时效性和稳定性。
MindSpore端云协同方案中的Cross-Device联邦学习框架可以打破用户与广告平台的数据壁垒,数据不用上云亦可实现联合建模。同时,我们通过小样本学习算法,充分利用端上用户特征数据及资源优化PCVR预估模型,提高广告转化率。在隐私合规的前提下,我们还支持端云协同的联合建模,以实现用户标签挖掘;在广告定向基础上于端侧进行二次推荐,提高广告转化效果。
MindSpore联邦学习框架适用于企业采集并上传大量图片、视频数据的场景。假设某公司的城市管廊项目,需要在站点上部署一些摄像头,用来做安全监控。传统方式是摄像头采集的视频数据上传到分控中心,分控中心做完数据预处理后,再传至总控中心。这一过程可能会出现两个问题:大量的数据上传会造成很大的带宽开销,成本也随之提高;数据中往往包含人脸和车辆等敏感信息,存在数据泄露的风险。
如何解决问题呢?MindSpore端云协同方案的Cross-silo联邦学习框架可以在每个站点做本地模型训练和推理,既能保证用户数据安全,还能控制带宽成本。
最后,希望开发者们可以持续关注MindSpore联邦学习框架,和我们一起构建联邦学习的生态技术,谢谢!
了解更多详情>>
访问华为开发者联盟官网
获取开发指导文档
华为移动服务开源仓库地址:GitHub、Gitee
关注我们,第一时间了解 HMS Core 最新技术资讯~
以上是关于MindSpore联邦学习框架解决行业级难题的主要内容,如果未能解决你的问题,请参考以下文章
联邦学习笔记-《Federated Machine Learning: Concept and Applications》论文翻译个人笔记
百度开源联邦学习框架 PaddleFL:简化大规模分布式集群部署