生产故障|Kafka ISR频繁伸缩缩引发性能急剧下降原因分析
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生产故障|Kafka ISR频繁伸缩缩引发性能急剧下降原因分析相关的知识,希望对你有一定的参考价值。
本文是笔者双十一系列第二弹,源于一个双十一期间一个让笔者猝不及防的生产故障,本文将详细剖析Kafka的副本机制,以及ISR频繁变更(扩张与伸缩)为什么会导致集群不可用。
1、Kafka副本机制
Kafka数据组织方式是topic-parition的结构,每一个topic可以设置多个分区,各个分区的数据是topic数据的一部分(数据分片),为了保证单个分区的高可用行,又引入了副本机制,即一个分区的数据会存储多份,避免单点故障.
一个3节点的Broker集群,每一个Toipic的副本因子设置为3,则对于其中一个Topic,其存储结构如下图所示:
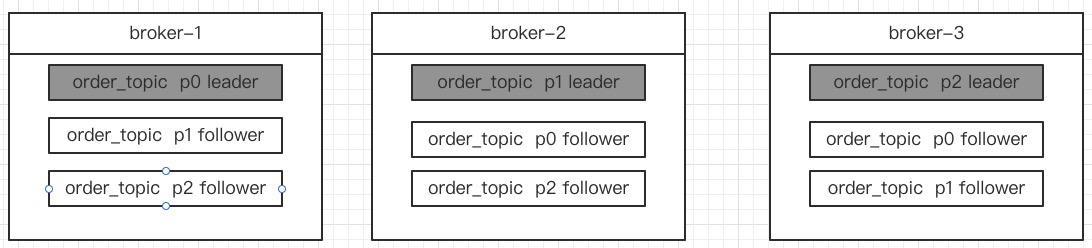
正如上图所示:一个Topic有三个分区,p0,p1,p2,其中每一个分区有3个副本(3份相同的数据),其与客户端交互的关键点如下:
- 每一个分区的Leader负责该分区的读写
- 分一个分区的follower从Leader节点复制数据
- 如果leader分区所在的broker宕机,会触发leader选举
上述的模型,满足高可用的诉求,但同时会带来一个设计难题:如何保证同一个分区中Leader与follwer节点数据的一致性。
Kafka副本之间的数据复制模型如下图所示:
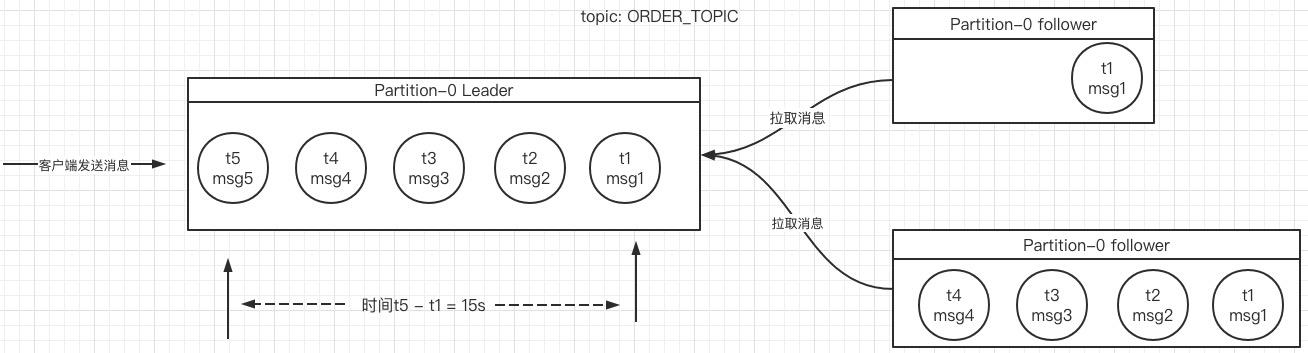
Kafka复制模型采取的是拉模型,即follower节点主动向leader拉取数据,leader节点可用根据从节点发起的拉起请求的消息偏移量,从而得知从节点当前复制数据的位置。
Kafka在数据副本一致性方面并没有采取诸如raft协议之列的,而是之间基于最高水位线与leader_epoch机制,本文不深入探讨在一致性方面的知识,这些后续会一一剖析。
在Kafka中,引入了一个概念:副本同步集,即ISR集合。
所谓的副本同步集,表示这个集合中的副本能跟上Leader的从节点,判断的规则:两者之间同步消息的时间间隔不能超过设置的阔值,该值由参数 replica.lag.time.max.ms 来控制,默认为10s。
例如上图中,分区p0的leader节点成功写入了5条消息,两者在服务端存储的时间间隔为15s,而其中一个从节点只复制了t1,与最新的t5消息间隔15s,超过了replica.lag.time.max.ms设置的10s,则Leader会将该节点从ISR集合中剔除;而另外一个从节点尽管只复制了4条消息,但落户Leader副本的时间间隔小于10s,则该节点会作为ISR集合中的一员。
ISR集合与副本数的关系如下图所示:

那这个ISR集合的作用是什么呢?
一个非常重要的作用:可以用来实现消息发送阶段消息不丢失。
构建KafkaProducer对象时可以设置acks=all或者-1表示必须ISR集合中的副本全部成功写入消息才会向客户端返回成功,注意:这里并不是说所有副本写入成功。
并且对ISR集合中的副本的个数也有要求,可以在topic级别的配置参数:min.insync.replicas进行设置,该值默认为2。
例如将topic的副本因子设置为3,表示有三个副本,只要ISR集合中的数量不少于2个,将acks设置为all时才能正常写入成功,如果ISR集合中的副本数量小于min.insync.replicas,则消息发送会失败。
以上就是Kafka ISR集合的一些基本介绍,该专栏后续会继续深入探讨kafka的日志存储、高低水位线、Leader epoch等机制。
在探究ISR伸缩与扩张会引发消息发送、消息消费性能急剧下降原因之前,想提出一个思考题,如果大家有兴趣交流,可以私信我。
思考题:从上文中可知,ISR集合中各个副本虽然是同步集合,但判断是否同步的规则确实从节点不落后Leader节点多少数据,那这些副本之间的数据并不是完全同步的,如果在Leader切换过程中,会丢失消息吗?
2、ISR频繁伸缩缩引发性能急剧下降
双十一期间一个Kafka集群频繁发生ISR,读写性能急剧下降,监控图如下所示:
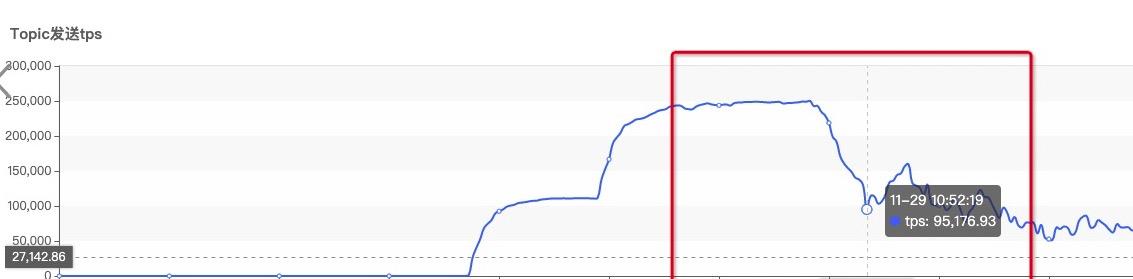
起初一个topic的写入tps达到了25W每秒,当出现ISR收缩与扩张后,断崖式下降,与此同时,服务端会有大量的日志:

为什么会ISR频繁收缩与扩张,为导致性能急剧下降呢?
当然,首先如果acks设置为all,消息写入下降这个是必然的,因为ISR集合中的数量会低于min.insync.replicas,导致消息无法写入,但这个topic是用于同步数据库binlog,如果出现集群等原因导致消息丢失,完全可以回放binlog进行数据补推,故消息发送时是将acks设置为1(Leader节点写入成功即返回成功)。
那又是为什么呢?
通过系统相关的监控发现发生问题时的CPU、磁盘都没有瓶颈,故优先排查Kafka的线程堆栈信息。
关键信息一:Kafka Broker在处理消息写入时需更新Kafka高水位线,需要申请leaderIsrUpdateLock的读锁,如下图所示:
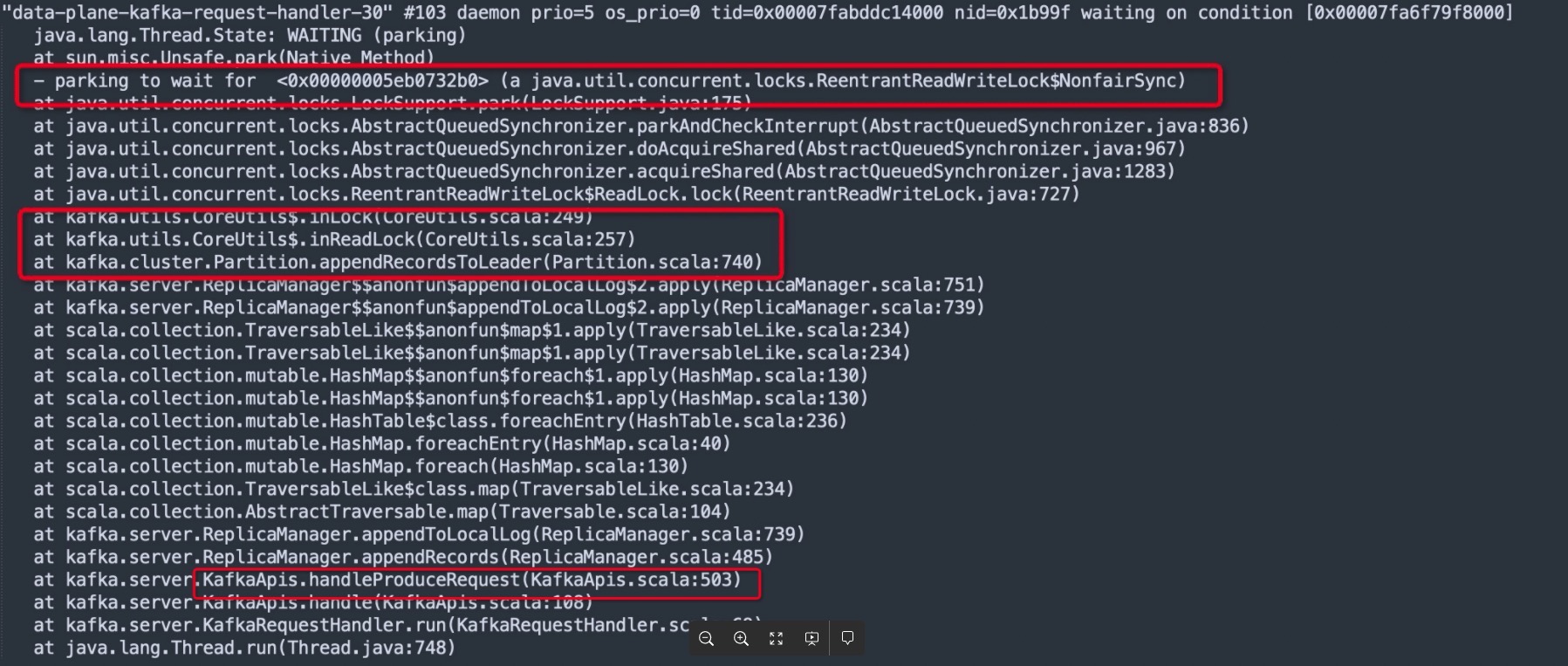
原来消息写入时需要加读锁,但由于读锁与读锁之间时相容的,并不影响消息发送的并发度。
关键信息二:Kafka Broker在处理消息拉起请求时(消费端、从节点都会发fetch请求)需同样需要更新Kafka高水位线,需要申请leaderIsrUpdateLock的读锁,如下图所示:
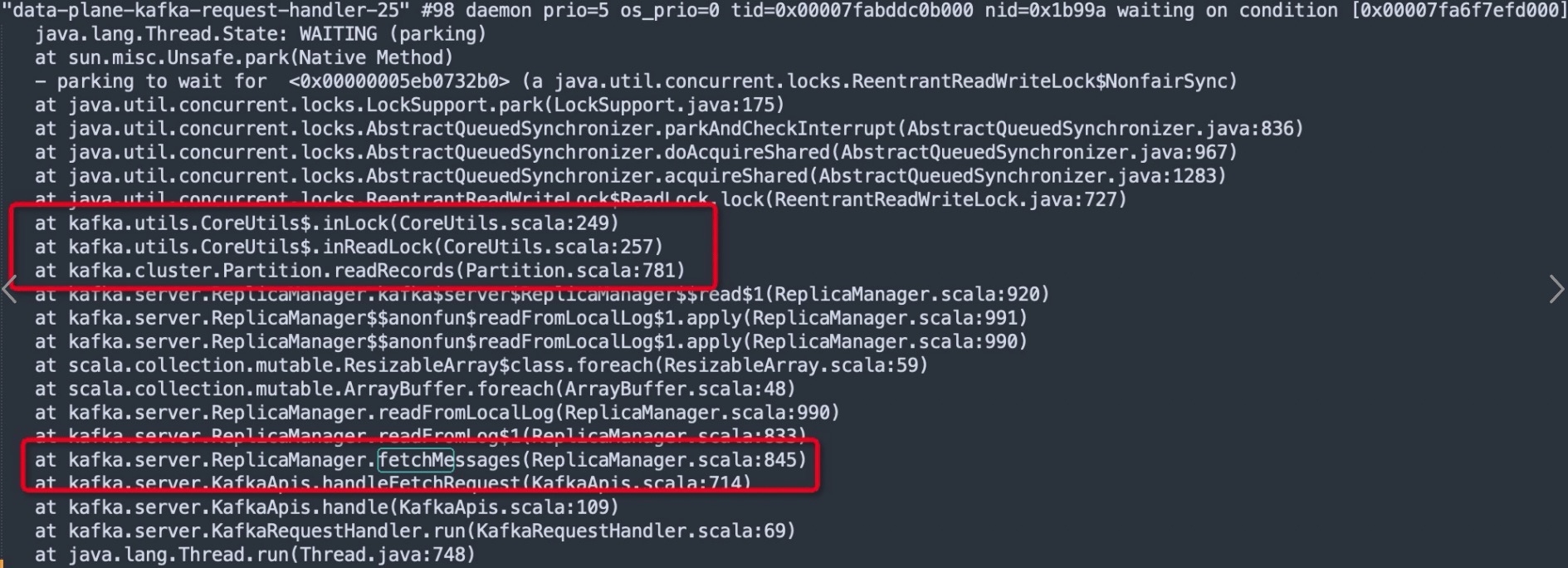
消息发送、消息写入都需要申请读写锁leaderIsrUpdateLock中的读锁,并不会影响并发度。
关键信息三:Kafka Broker在ISR发生扩张与伸缩时需要申请leaderIsrUpdateLock的写锁,如下图所示:

在ISR集合发生变更时,对高水位线的的更新需要加写锁,此时会与消息发送、消费客户端消费消息、分区副本消息复制发送锁竞争,并发度急剧下降,这样就解释了为什么ISR收缩与扩张会导致TPS急剧下降。
令人比较“无语”的是,这里会有一个连锁反应,因为会影响副本分区从其Leader节点拉取消息的速率,容易加剧ISR的扩张与收缩,从而使问题越来越严重。
3、解决方案
经过上述分析,ISR的频繁扩张与收缩,其最直观的原因是:follower副本从Leader副本复制数据,由于复制跟不上,导致两者之间数据同步的差距超过了replica.lag.time.max.ms,导致Leader分区会将跟不上进度的副本剔除ISR,然后当follwer分区跟上后,又能加入ISR。
故可以通过调整Kafka相关的参数,来减少ISR发生的几率:
- replica.lag.time.max.ms
从默认10s,调整为30s - num.replica.fetchers
从默认值1调整为10,该参数的主要作用是设置Follower节点用于从服务端复制数据的线程数量,调整该参数可以加大并发,在线程堆栈线程名称为:ReplicaFetcherThread线程,注意,这个是控制一个节点到集群单个Broker的链接数,例如一集群有8个节点,该值设置为10,那一个节点就会创建 (8-1)* 10 共70个ReplicaFetcherThread线程。
本文就到介绍到这里里,其实ISR频发扩张后,还会引发更加严重的问题,最后竟然引发了整个集群无法写入消息,无法消费消息,这些将在后续文章中发布,如果有兴趣,可以持续关注。
文章首发:https://www.codingw.net/posts/c3bb6e0e.html
一键三连(关注、点赞、留言)是对我最大的鼓励。
各位技术朋友们,我是《RocketMQ技术内幕》一书作者,CSDN2020博客之星TOP2,热衷于中间件领域的技术分享,维护「中间件兴趣圈」公众号,旨在成体系剖析Java主流中间件,构建完备的分布式架构体系,欢迎大家大家关注我,回复「专栏」可获取15个专栏;回复「PDF」可获取海量学习资料,回复「加群」可以拉你入技术交流群,零距离与BAT大厂的大神交流。
以上是关于生产故障|Kafka ISR频繁伸缩缩引发性能急剧下降原因分析的主要内容,如果未能解决你的问题,请参考以下文章