yolox训练自己的数据
Posted lishanlu136
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yolox训练自己的数据相关的知识,希望对你有一定的参考价值。
前言:此文是我从yolov5替换到yolox训练的过程,前提是我们有图片和标注文件,而且都是yolov5的txt格式的;之前在网上看了一圈,怎么用自己的数据训练yolox模型,都是需要把标注文件整理成voc格式或coco数据集格式,连文件夹的存放方式都必须一样,真是麻烦;而我之前的任务都是基于yolov5训练的,所以图片,标注文件已经有了,我也不想按voc,coco那样再去改变格式,于是就有了此文。
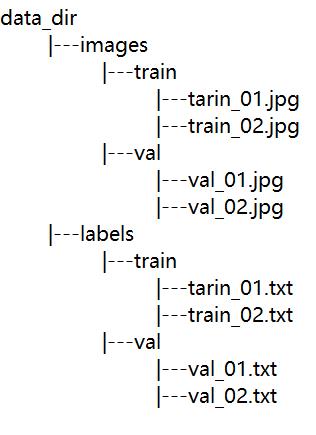
yolov5数据集目录如下:
一、利用yolov5标注生成xml格式的标注
利用yolov5的txt格式的标注文件生成xml格式的标注文件,在生成的时候需注意:
1、yolov5的标注是经过归一化的c_x, c_y, w, h
2、背景图片yolov5可以不用标注,即没有对应的txt文件,但yolox训练却不行
3、图片名字不要带有空格,yolov5可以正常训练验证,但yolox在验证的时候会报错。
直接上生成xml的代码,文件名yolotxt2xml.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/09/14 11:14
# @Author : lishanlu
# @File : yolotxt2xml.py
# @Software: PyCharm
# @Discription:
from __future__ import absolute_import, print_function, division
import os
from xml.dom.minidom import Document
import xml.etree.ElementTree as ET
import cv2
'''
import xml
xml.dom.minidom.Document().writexml()
def writexml(self,
writer: Any,
indent: str = "",
addindent: str = "",
newl: str = "",
encoding: Any = None) -> None
'''
class YOLO2VOCConvert:
def __init__(self, txts_path, xmls_path, imgs_path, classes_str_list):
self.txts_path = txts_path # 标注的yolo格式标签文件路径
self.xmls_path = xmls_path # 转化为voc格式标签之后保存路径
self.imgs_path = imgs_path # 读取读片的路径个图片名字,存储到xml标签文件中
self.classes = classes_str_list # 类别列表
# 从所有的txt文件中提取出所有的类别, yolo格式的标签格式类别为数字 0,1,...
# writer为True时,把提取的类别保存到'./Annotations/classes.txt'文件中
def search_all_classes(self, writer=False):
# 读取每一个txt标签文件,取出每个目标的标注信息
all_names = set()
txts = os.listdir(self.txts_path)
# 使用列表生成式过滤出只有后缀名为txt的标签文件
txts = [txt for txt in txts if txt.split('.')[-1] == 'txt']
txts = [txt for txt in txts if not txt.split('.')[0] == "classes"] # 过滤掉classes.txt文件
print(len(txts), txts)
# 11 ['0002030.txt', '0002031.txt', ... '0002039.txt', '0002040.txt']
for txt in txts:
txt_file = os.path.join(self.txts_path, txt)
with open(txt_file, 'r') as f:
objects = f.readlines()
for object in objects:
object = object.strip().split(' ')
print(object) # ['2', '0.506667', '0.553333', '0.490667', '0.658667']
all_names.add(int(object[0]))
# print(objects) # ['2 0.506667 0.553333 0.490667 0.658667\\n', '0 0.496000 0.285333 0.133333 0.096000\\n', '8 0.501333 0.412000 0.074667 0.237333\\n']
print("所有的类别标签:", all_names, "共标注数据集:%d张" % len(txts))
# 把从xmls标签文件中提取的类别写入到'./Annotations/classes.txt'文件中
# if writer:
# with open('./Annotations/classes.txt', 'w') as f:
# for label in all_names:
# f.write(label + '\\n')
return list(all_names)
def yolo2voc(self):
"""
可以转换图片和txtlabel数量不匹配的情况,即有些图片是背景
:return:
"""
# 创建一个保存xml标签文件的文件夹
if not os.path.exists(self.xmls_path):
os.makedirs(self.xmls_path)
for img_name in os.listdir(self.imgs_path):
# 读取图片的尺度信息
print("读取图片:", img_name)
try:
img = cv2.imread(os.path.join(self.imgs_path, img_name))
height_img, width_img, depth_img = img.shape
print(height_img, width_img, depth_img) # h 就是多少行(对应图片的高度), w就是多少列(对应图片的宽度)
except Exception as e:
print("%s read fail, %s"%(img_name, e))
continue
txt_name = img_name.replace(os.path.splitext(img_name)[1], '.txt')
txt_file = os.path.join(self.txts_path, txt_name)
all_objects = []
if os.path.exists(txt_file):
with open(txt_file, 'r') as f:
objects = f.readlines()
for object in objects:
object = object.strip().split(' ')
all_objects.append(object)
print(object) # ['2', '0.506667', '0.553333', '0.490667', '0.658667']
# 创建xml标签文件中的标签
xmlBuilder = Document()
# 创建annotation标签,也是根标签
annotation = xmlBuilder.createElement("annotation")
# 给标签annotation添加一个子标签
xmlBuilder.appendChild(annotation)
# 创建子标签folder
folder = xmlBuilder.createElement("folder")
# 给子标签folder中存入内容,folder标签中的内容是存放图片的文件夹,例如:JPEGImages
folderContent = xmlBuilder.createTextNode(self.imgs_path.split('/')[-1]) # 标签内存
folder.appendChild(folderContent) # 把内容存入标签
annotation.appendChild(folder) # 把存好内容的folder标签放到 annotation根标签下
# 创建子标签filename
filename = xmlBuilder.createElement("filename")
# 给子标签filename中存入内容,filename标签中的内容是图片的名字,例如:000250.jpg
filenameContent = xmlBuilder.createTextNode(txt_name.split('.')[0] + '.jpg') # 标签内容
filename.appendChild(filenameContent)
annotation.appendChild(filename)
# 把图片的shape存入xml标签中
size = xmlBuilder.createElement("size")
# 给size标签创建子标签width
width = xmlBuilder.createElement("width") # size子标签width
widthContent = xmlBuilder.createTextNode(str(width_img))
width.appendChild(widthContent)
size.appendChild(width) # 把width添加为size的子标签
# 给size标签创建子标签height
height = xmlBuilder.createElement("height") # size子标签height
heightContent = xmlBuilder.createTextNode(str(height_img)) # xml标签中存入的内容都是字符串
height.appendChild(heightContent)
size.appendChild(height) # 把width添加为size的子标签
# 给size标签创建子标签depth
depth = xmlBuilder.createElement("depth") # size子标签width
depthContent = xmlBuilder.createTextNode(str(depth_img))
depth.appendChild(depthContent)
size.appendChild(depth) # 把width添加为size的子标签
annotation.appendChild(size) # 把size添加为annotation的子标签
# 每一个object中存储的都是['2', '0.506667', '0.553333', '0.490667', '0.658667']一个标注目标
for object_info in all_objects:
# 开始创建标注目标的label信息的标签
object = xmlBuilder.createElement("object") # 创建object标签
# 创建label类别标签
# 创建name标签
imgName = xmlBuilder.createElement("name") # 创建name标签
imgNameContent = xmlBuilder.createTextNode(self.classes[int(object_info[0])])
imgName.appendChild(imgNameContent)
object.appendChild(imgName) # 把name添加为object的子标签
# 创建pose标签
pose = xmlBuilder.createElement("pose")
poseContent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(poseContent)
object.appendChild(pose) # 把pose添加为object的标签
# 创建truncated标签
truncated = xmlBuilder.createElement("truncated")
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated)
# 创建difficult标签
difficult = xmlBuilder.createElement("difficult")
difficultContent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultContent)
object.appendChild(difficult)
# 先转换一下坐标
# (objx_center, objy_center, obj_width, obj_height)->(xmin,ymin, xmax,ymax)
x_center = float(object_info[1]) * width_img + 1
y_center = float(object_info[2]) * height_img + 1
xminVal = int(
x_center - 0.5 * float(object_info[3]) * width_img) # object_info列表中的元素都是字符串类型
yminVal = int(y_center - 0.5 * float(object_info[4]) * height_img)
xmaxVal = int(x_center + 0.5 * float(object_info[3]) * width_img)
ymaxVal = int(y_center + 0.5 * float(object_info[4]) * height_img)
# 创建bndbox标签(三级标签)
bndbox = xmlBuilder.createElement("bndbox")
# 在bndbox标签下再创建四个子标签(xmin,ymin, xmax,ymax) 即标注物体的坐标和宽高信息
# 在voc格式中,标注信息:左上角坐标(xmin, ymin) (xmax, ymax)右下角坐标
# 1、创建xmin标签
xmin = xmlBuilder.createElement("xmin") # 创建xmin标签(四级标签)
xminContent = xmlBuilder.createTextNode(str(xminVal))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin)
# 2、创建ymin标签
ymin = xmlBuilder.createElement("ymin") # 创建ymin标签(四级标签)
yminContent = xmlBuilder.createTextNode(str(yminVal))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin)
# 3、创建xmax标签
xmax = xmlBuilder.createElement("xmax") # 创建xmax标签(四级标签)
xmaxContent = xmlBuilder.createTextNode(str(xmaxVal))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax)
# 4、创建ymax标签
ymax = xmlBuilder.createElement("ymax") # 创建ymax标签(四级标签)
ymaxContent = xmlBuilder.createTextNode(str(ymaxVal))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object) # 把object添加为annotation的子标签
f = open(os.path.join(self.xmls_path, txt_name.split('.')[0] + '.xml'), 'w')
xmlBuilder.writexml(f, indent='\\t', newl='\\n', addindent='\\t', encoding='utf-8')
f.close()
if __name__ == '__main__':
imgs_path1 = 'F:/Dataset/road/images/val' # ['train', 'val']
txts_path1 = 'F:/Dataset/road/labels/val' # ['train', 'val']
xmls_path1 = 'F:/Dataset/road/xmls/val' # ['train', 'val']
classes_str_list = ['road_crack','road_sag'] # class name
yolo2voc_obj1 = YOLO2VOCConvert(txts_path1, xmls_path1, imgs_path1, classes_str_list)
labels = yolo2voc_obj1.search_all_classes()
print('labels: ', labels)
yolo2voc_obj1.yolo2voc()
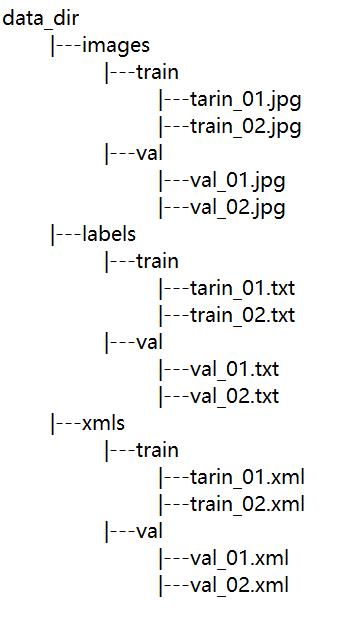
将train和val都转换生成后,目录格式如下:
二、定义数据读取文件
整个YOLOX的工程,训练过程,要想有一个大概浏览,可以见我的另一篇文章yolox训练解析
进入到YOLOX主目录
在yolox/data/datasets/目录下定义了数据的读取方式,有按coco方式读取,有按voc方式读取,另外mosaic增强也定义在这个文件夹下,我们添加新的读取方式就在这个目录下添加,添加yolo_style.py文件,代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/23 9:13
# @Author : lishanlu
# @File : yolo_style.py
# @Software: PyCharm
# @Discription: 读入yolox风格的xmls数据
from __future__ import absolute_import, print_function, division
import os
import os.path
import pickle
import xml.etree.ElementTree as ET
import cv2
import numpy as np
from yolox.evaluators.voc_eval import voc_eval
from .datasets_wrapper import Dataset
from pathlib import Path
import glob
from tqdm import tqdm
from PIL import Image, ExifTags
import torch
class AnnotationTransform(object):
"""Transforms a annotation into a Tensor of bbox coords and label index
Initilized with a dictionary lookup of classnames to indexes
Arguments:
classes_name: (str, str, ...): dictionary lookup of classnames -> indexes
keep_difficult (bool, optional): keep difficult instances or not
(default: False)
height (int): height
width (int): width
"""
def __init__(self, classes_name, keep_difficult=True):
self.class_to_ind = dict(zip(classes_name, range(len(classes_name))))
self.keep_difficult = keep_difficult
def __call__(self, target):
"""
Arguments:
target (annotation) : the target annotation to be made usable
will be an ET.Element
Returns:
a list containing lists of bounding boxes [bbox coords, class name]
"""
res = np.empty((0, 5))
for obj in target.iter("object"):
difficult = obj.find("difficult")
if difficult is not None:
difficult = int(difficult.text) == 1
else:
difficult = False
if not self.keep_difficult and difficult:
continue
name = obj.find("name").text.strip()
bbox = obj.find("bndbox")
pts = ["xmin", "ymin", "xmax", "ymax"]
bndbox = []
for i, pt in enumerate(pts):
cur_pt = int(bbox.find(pt).text) - 1
# scale height or width
# cur_pt = cur_pt / width if i % 2 == 0 else cur_pt / height
bndbox.append(cur_pt)
label_idx = self.class_to_ind[name]
bndbox.append(label_idx)
res = np.vstack((res, bndbox)) # [xmin, ymin, xmax, ymax, label_ind]
# img_id = target.find('filename').text[:-4]
width = int(target.find("size").find("width").text)
height = int(target.find("size").find("height").text)
img_info = (height, width)
return res, img_info
"""
generation yolo style dataloader.
"""
img_formats = ['bmp', 'jpg', 'jpeg', 'png', 'tif', 'tiff', 'dng', 'webp'] # acceptable image suffixes
# Get orientation exif tag
for orientation in ExifTags.TAGS.keys():
if ExifTags.TAGS[orientation] == 'Orientation':
break
def img2xml_paths(img_paths):
# Define xml paths as a function of image paths
sa, sb = os.sep + 'images' + os.sep, os.sep + 'xmls' + os.sep # /images/, /xmls/ substrings
return ['xml'.join(x.replace(sa, sb, 1).rsplit(x.split('.')[-1], 1)) for x in img_paths]
def get_hash(files):
# Returns a single hash value of a list of files
return sum(os.path.getsize(f) for f in files if os.path.isfile(f))
def exif_size(img):
# Returns exif-corrected PIL size
s = img.size # (width, height)
try:
rotation = dict(img._getexif().items())[orientation]
if rotation == 6: # rotation 270
s = (s[1], s[0])
elif rotation == 8: # rotation 90
s = (s[1], s[0])
except:
pass
return s
def xyxy2xywh(x):
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = (x[:, 0] + x[:, 2]