spark源码跟踪累加器Accumulators
Posted cangchen@csdn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark源码跟踪累加器Accumulators相关的知识,希望对你有一定的参考价值。
累加器Accumulators
一,累加器作用及其原理
1.1,作用
可实现分布式计数或求和;可以在spark application运行UI中显示其值,便于调试。
1.2,原理
在Driver端中定义的累加器Accumulators对象,跟随各spark task任务分发到Executor端,反序列化后的Accumulators副本对象各自执行累加操作(add),task任务执行执行完毕后,Driver端对返回的多个Accumulators副本对象执行合并操作(merge)。
二,累加器关键源码跟踪阅读
2.1,测试代码
def main(args: Array[String]): Unit =
log.info("-------begin---------")
val sparkConnf=new SparkConf().setAppName("acc").setMaster("local[3]")
val sparkContext=new SparkContext(sparkConnf)
val rdd = sparkContext.parallelize(Array(1, 2, 3, 4,5), 2)
var sum=0
val sumAcc = sparkContext.longAccumulator("sumAcc")
rdd.foreach(num=>
sum=sum+num
sumAcc.add(num)
println("----excutor:----sumACC="+sumAcc)
)
println("---------sum="+sum)
println("---------sumAcc="+sumAcc.value)
sparkContext.stop()
关键日志:
----excutor:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 3)
----excutor:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 7)
----excutor:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 12)
----excutor:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 1)
----excutor:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 3)
---------sum=0
---------sumAcc=15
2.2,跟踪源码
2.2.1,add调用
SparkContext.scala
/**
* Create and register a long accumulator, which starts with 0 and accumulates inputs by `add`.
*/
def longAccumulator(name: String): LongAccumulator =
val acc = new LongAccumulator
register(acc, name)
acc
/**
* Register the given accumulator with given name.
*
* @note Accumulators must be registered before use, or it will throw exception.
*/
def register(acc: AccumulatorV2[_, _], name: String): Unit =
acc.register(this, name = Option(name))
AccumulatorV2.scala
private[spark] def register(
sc: SparkContext,
name: Option[String] = None,
countFailedValues: Boolean = false): Unit =
if (this.metadata != null)
throw new IllegalStateException("Cannot register an Accumulator twice.")
this.metadata = AccumulatorMetadata(AccumulatorContext.newId(), name, countFailedValues)
AccumulatorContext.register(this)
sc.cleaner.foreach(_.registerAccumulatorForCleanup(this))
AccumulatorContext
/**
* This global map holds the original accumulator objects that are created on the driver.
* It keeps weak references to these objects so that accumulators can be garbage-collected
* once the RDDs and user-code that reference them are cleaned up.
* TODO: Don't use a global map; these should be tied to a SparkContext (SPARK-13051).
*/
private val originals = new ConcurrentHashMap[Long, jl.ref.WeakReference[AccumulatorV2[_, _]]]
/**
* Registers an [[AccumulatorV2]] created on the driver such that it can be used on the executors.
*
* All accumulators registered here can later be used as a container for accumulating partial
* values across multiple tasks. This is what `org.apache.spark.scheduler.DAGScheduler` does.
* Note: if an accumulator is registered here, it should also be registered with the active
* context cleaner for cleanup so as to avoid memory leaks.
*
* If an [[AccumulatorV2]] with the same ID was already registered, this does nothing instead
* of overwriting it. We will never register same accumulator twice, this is just a sanity check.
*/
def register(a: AccumulatorV2[_, _]): Unit =
originals.putIfAbsent(a.id, new jl.ref.WeakReference[AccumulatorV2[_, _]](a))
val sumAcc = sparkContext.longAccumulator("sumAcc")
这行代码创建了一个LongAccumulator类型的累加器,并做了一些列注册工作,并返回了一个对象。
接下来rdd.foreach是一个行动操作:
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit = withScope
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
这里runJon的第二个参数的实际内容大致为
(iter: Iterator[Int])=>iter.foreach(
num=>
sum=sum+num
sumAcc.add(sum)
println("----excutor:----sumACC="+sumAcc)
)
这个函数在那执行?是在task类的runTask方法中执行的。
ResultTask.scala
override def runTask(context: TaskContext): U =
// Deserialize the RDD and the func using the broadcast variables.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTimeNs = System.nanoTime()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported)
threadMXBean.getCurrentThreadCpuTime
else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTimeNs = System.nanoTime() - deserializeStartTimeNs
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported)
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
else 0L
func(context, rdd.iterator(partition, context))
这里反序列化出来的func函数的第二个参数中就封装了测试代码中rdd.foreach中传入的用户代码。
(iter: Iterator[Int])=>iter.foreach(
num=>
sum=sum+num
sumAcc.add(sum)
println("----excutor:----sumACC="+sumAcc)
)
func(context, rdd.iterator(partition, context)) 执行func函数。
rdd.iterator返回该task负责的rdd一个分区的所有数据组成的迭代器Iterator并作为参数传入func中,在其函数体中遍历Iterator中数据并挨个执行用户自定义的逻辑代码。
结论一:所以sumAcc.add(sum)的执行次数与行动操作返回的数据元素数量一致。
2.2.2,merge调用
一个stage执行完毕后,executor会和ApplicationMaster通讯发送
CompletionEvent对象。
DAGSchedulerEventProcessLoop.scala
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
case StageCancelled(stageId, reason) =>
dagScheduler.handleStageCancellation(stageId, reason)
case JobCancelled(jobId, reason) =>
dagScheduler.handleJobCancellation(jobId, reason)
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
case ExecutorLost(execId, reason) =>
val workerLost = reason match
case SlaveLost(_, true) => true
case _ => false
dagScheduler.handleExecutorLost(execId, workerLost)
case WorkerRemoved(workerId, host, message) =>
dagScheduler.handleWorkerRemoved(workerId, host, message)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case SpeculativeTaskSubmitted(task) =>
dagScheduler.handleSpeculativeTaskSubmitted(task)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
最终会调用updateAccumulators(event: CompletionEvent): Unit方法合并所有的累加器。
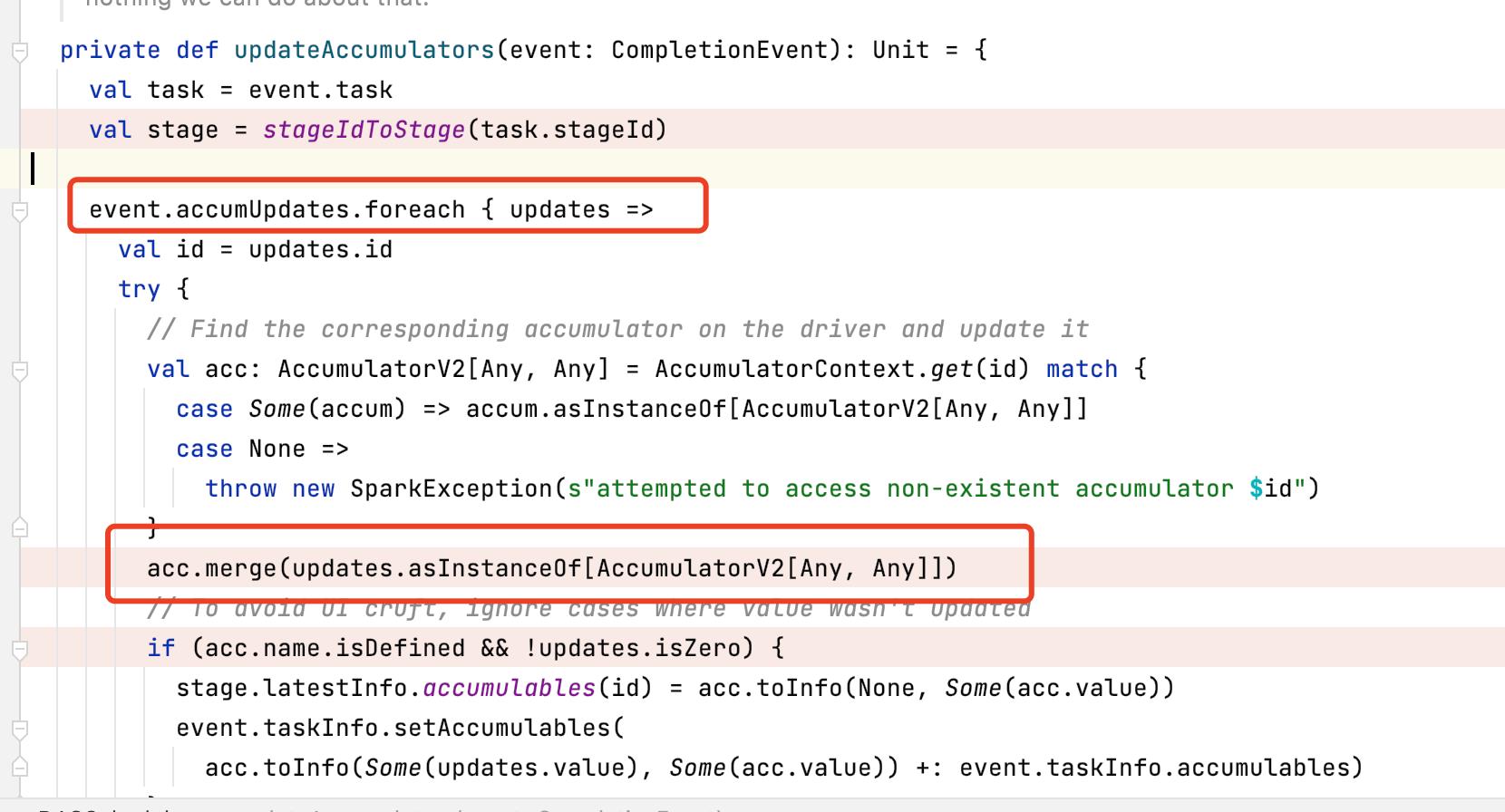
测试代码中sum=sum+num执行次数和 sumAcc.add(num)执行情况一摸一样,都是分散在各个executor中执行的,但是其结果没有回传到Driver端,所以Driver端的sum结果一直是初始值。
三,累加器在行动算子和转换算子中执行有何不同
上面写的源码跟踪里累加器是写在行动操作中的,与写在转换操作中有什么不一样?
3.1,测试代码
def main(args: Array[String]): Unit =
log.info("-------begin---------")
val sparkConnf=new SparkConf().setAppName("acc").setMaster("local[1]")
val sparkContext=new SparkContext(sparkConnf)
val rdd = sparkContext.parallelize(Array(1, 2, 3, 4,5), 2)
val sumAcc = sparkContext.longAccumulator("sumAcc")
val mapRDD = rdd.map(num =>
sumAcc.add(num)
println("----transfer:----sumACC="+sumAcc)
num
)
mapRDD.foreach(num=>
sumAcc.add(num)
println("----action:----sumACC="+sumAcc)
)
println("----result:----sumACC="+sumAcc)
sparkContext.stop()
在转换操作中执行的add操作显然是在rdd的compute方法中被调用的,先于行动操作执行。
关键日志:
----transfer:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 1)
----action:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 2)
----transfer:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 4)
----action:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 6)
----transfer:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 3)
----action:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 6)
----transfer:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 10)
----action:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 14)
----transfer:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 19)
----action:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 24)
----result:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 30)
累加器add操作执行了两次,结果是30不是15。
四,累加器级别
累加器是application级别的,如果一个application中有多个行动操作或者有检查点(检查点是一个独立的job,参考:https://cangchen.blog.csdn.net/article/details/122020410)的情况,累加器的值可能与预期的不一致。
4.1,检查点与累加器
def main(args: Array[String]): Unit =
log.info("-------begin---------")
val sparkConnf=new SparkConf().setAppName("acc").setMaster("local[1]")
val sparkContext=new SparkContext(sparkConnf)
sparkContext.setCheckpointDir(".")
val rdd = sparkContext.parallelize(Array(1, 2, 3, 4,5), 2)
val sumAcc = sparkContext.longAccumulator("sumAcc")
val mapRDD = rdd.map(num =>
sumAcc.add(num)
num
)
mapRDD.checkpoint()
mapRDD.foreach(num=>
println(num)
)
println("----result:----sumACC="+sumAcc)
sparkContext.stop()
结果:
----result:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 30)
累加器的add操作是在转换操作map中执行的,计算时执行了两次,第一次是在行动操作foreach 提交的job中执行的,第二次是检查点提交的job中执行,要避免检查点重复执行add,可使用cache。
def main(args: Array[String]): Unit =
log.info("-------begin---------")
val sparkConnf=new SparkConf().setAppName("acc").setMaster("local[1]")
val sparkContext=new SparkContext(sparkConnf)
sparkContext.setCheckpointDir(".")
val rdd = sparkContext.parallelize(Array(1, 2, 3, 4,5), 2)
val sumAcc = sparkContext.longAccumulator("sumAcc")
val mapRDD = rdd.map(num =>
sumAcc.add(num)
num
)
mapRDD.checkpoint()
mapRDD.cache()
mapRDD.foreach(num=>
println(num)
)
println("----result:----sumACC="+sumAcc)
sparkContext.stop()
结果:
----result:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 15)
cache会缓存数据避免rdd的compute函数再次调用,所以累加器只执行了一次。
4.2 多个行动操作与累加器
def main(args: Array[String]): Unit =
log.info("-------begin---------")
val sparkConnf=new SparkConf().setAppName("acc").setMaster("local[1]")
val sparkContext=new SparkContext(sparkConnf)
// sparkContext.setCheckpointDir(".")
val rdd = sparkContext.parallelize(Array(1, 2, 3, 4,5), 2)
val sumAcc = sparkContext.longAccumulator("sumAcc")
val mapRDD = rdd.map(num =>
sumAcc.add(num)
num
)
// mapRDD.checkpoint()
//mapRDD.cache()
mapRDD.foreach(num=>
println(num)
)
mapRDD.foreach(num=>
println(num)
)
println("----result:----sumACC="+sumAcc)
sparkContext.stop()
结果:
----result:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 30)
两个行动操作生成两个独立的job,累加器执行了两次。同样使用cache也能避免这种情况:
def main(args: Array[String]): Unit =
log.info("-------begin---------")
val sparkConnf=new SparkConf().setAppName("acc").setMaster("local[1]")
val sparkContext=new SparkContext(sparkConnf)
// sparkContext.setCheckpointDir(".")
val rdd = sparkContext.parallelize(Array(1, 2, 3, 4,5), 2)
val sumAcc = sparkContext.longAccumulator("sumAcc")
val mapRDD = rdd.map(num =>
sumAcc.add(num)
num
)
// mapRDD.checkpoint()
mapRDD.cache()
mapRDD.foreach(num=>
println(num)
)
mapRDD.foreach(num=>
println(num)
)
println("----result:----sumACC="+sumAcc)
sparkContext.stop()
----result:----sumACC=LongAccumulator(id: 0, name: Some(sumAcc), value: 15)
五,自定义累加器
自定义累加器实现wordcount功能
package cchen.spark.sparkcore
import org.apache.spark.internal.Logging
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2, LongAccumulator
import org.apache.spark.SparkConf, SparkContext
import scala.collection.Iterator, mutable
class WordCount
object WordCount extends Logging
def main(args: Array[String]): Unit =
log.info("-------begin---------")
val sparkConnf=new SparkConf().setAppName("acc").setMaster("local[3]")
val sparkContext=new SparkContext(sparkConnf)
val rdd = sparkContext.parallelize(Array("hello", "thank you", "thank you very much", "are you ok"), 2)
val flat_rdd = rdd.flatMap(_.split(" ",-1))
val wordCountACC = new WordCountAccumulator
sparkContext.register(wordCountACC, "wordCountACC")
flat_rdd.foreach(f=>
wordCountACC.add(f)
)
flat_rdd.cache()
println("----reduceByKey result-----")
flat_rdd.map(f=>(f,1)).reduceByKey(_+_).collect().map(f=>println(f._1+":"+f._2))
println("----acc result-----")
wordCountACC.value.map(f=>println(f._1+":"+f._2))
sparkContext.stop()
class WordCountAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]]
private var map=mutable.Map[String,Long]()
override def isZero: Boolean = map.isEmpty
override def copy(): AccumulatorV2[String, mutable.Map[String,Long]] =
val newACC=new WordCountAccumulator()
newACC.map=this.map.clone()
newACC
override def reset(): Unit = map.clear()
override def add(v: String): Unit =
val value=map.getOrElse(v,0L)
map.put(v,value+1)
override def merge(other: AccumulatorV2[String, mutable.Map[String,Long]]): Unit =other match
case o: WordCountAccumulator =>
o.value.map(f=>
val value=map.getOrElse(f._1,0L)
map.put(f._1,value+f._2)
)
case _ =>
throw new UnsupportedOperationException(
s"Cannot merge $this.getClass.getName with $other.getClass.getName")
override def value: mutable.Map[String,Long]= map
结果:
----reduceByKey result-----
are:1
thank:2
hello:1
very:1
ok:1
you:3
much:1
----acc result-----
you:3
ok:1
are:1
very:1
thank:2
much:1
hello:1
使用累加器的方式速度应该更快,跟reduceByKey相比它没有shuffle过程。
六,总结
1,累加器的add操作实际执行的地方与客户代码中调用的地方有关系。
如果add在RDD转换操作中调用,则实际在RDD compute函数中被调用;如果在RDD行动操作中被调用,则在ResultTask runTask方法中被调用。都是在Excutor端执行
2,累加器的merge操作实际执行的地方在Driver端,每个job stage执行成功后执行累加器的merge操作。
3,累加器是application级别,多个行动操作或者单行动操作且有检查点checkpoint的情况下要注意“多加”的现象。
以上是关于spark源码跟踪累加器Accumulators的主要内容,如果未能解决你的问题,请参考以下文章