02HDFS分布式文系统
Posted 华为大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了02HDFS分布式文系统相关的知识,希望对你有一定的参考价值。
一、HDFS分布式文件系统概述
Hdfs Hadoop Distrabuted File System 分布式文件系统
1、分布式:
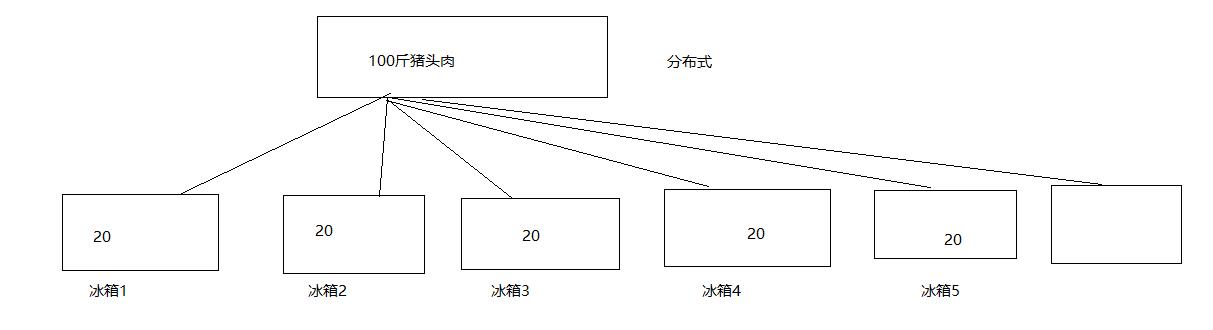
2、HDFS特点:
海量数据存储(GB,TB,PB级的数据)1MB=1024KB 1 GB=1024MB
高容错性:默认保存副本(3个),当一份数据丢失时,可以恢复数据,hdfs内部机制实现的。
数据冗余
高延时
不适合场景:
低延时:
不适合存放大量小文件
多用户输入,不适合做任意修改。
了解几个名词
3、了解几个名词
1、POSIX:可移植操作系统接口(英语:Portable Operating System Interface)是IEEE为要在各种UNIX操作系统上运行软件
2、什么是数据的流式访问:
- 流式数据访问:最小化磁盘的寻址开销,只需要寻址一次,然后一直读下去,适合一次写,多次读的数据访问
- 随机数据访问:要求定位、查询或修改数据的延迟较小,传统关系型数据库符合这一点
3、Nutch,Lucene,Avro
(1)Apache Nutch Web:Nutch是一个开源Java 实现的搜索引擎。包括全文搜索和Web爬虫。
(2) Nutch的创始人是Doug Cutting(道格卡廷),他同时也是Lucene(全文检索引擎)、Hadoop和Avro开源项目的创始人
(3)Avro是Hadoop下的子项目,是一个数据序列化系统,设计用于支持大批量数据交换的应用。主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;
二、HDFS的基本架构
 由三部分组成(Client NameNode DataNode)采用了Master-Slaver(主—从)模式
由三部分组成(Client NameNode DataNode)采用了Master-Slaver(主—从)模式
1、Client作用:
向NN发出请求,获得文件的位置,副本数
将文件切分block,每个块默认是128M(大小可以设置)
向DataNode读写文件
2、NameNode作用:
管理元数据信息(文件名,位置,大小,副 本,属组)
数据块的映射
配置副本
和DN保持 心跳,如果10分钟没有收到,表示宕机了,则删除,数据转移。
3、DataNode的作用:
真正存放数据
执行数据的读写
向NN发送心跳,3秒一次
4、NameNode 和DataNode 区别
| NameNode | DataNode |
| 存储元数据 | 存储数据内容 |
| 元数据保存在内存 | 文件内容存在磁盘上 |
问题一:为什么不能存放大量小文件?
因为一个集群只有一个NameNode,NameNode存放元数据信息在内存,如果存放大量小文件,会占用很大内存,成为集群的瓶颈。
问题二:如何理解元数据信息
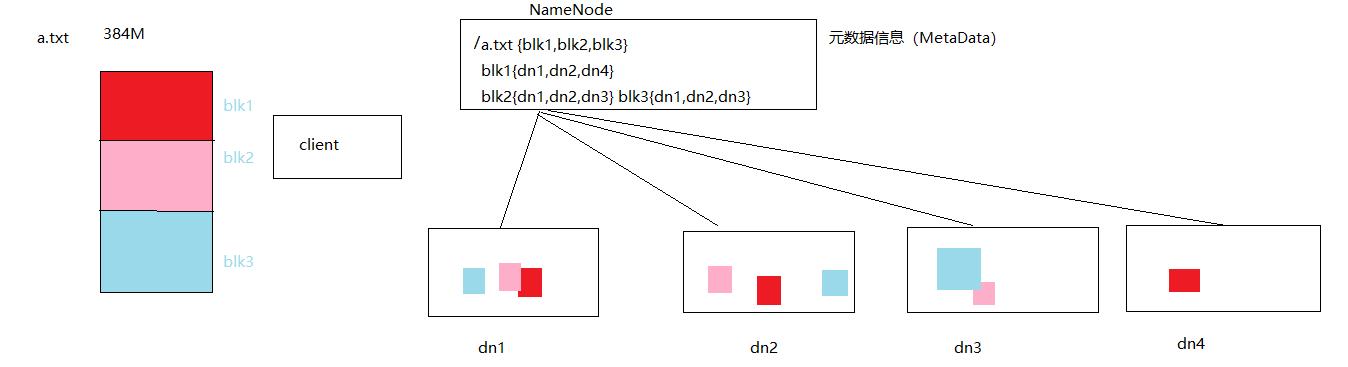 5、NameNode是如何存放数据
5、NameNode是如何存放数据
Fsimgage存放目录
Editlog客户端的操作(创建,删除,重命名)
三、HDFS的高可靠性(HA)
解决了只有一个NameNode可能会产生单 点故障问题-----------主备模式

- 主NN和备NN的数据同步
主NN写日志到JN上,同时备NN从JN上读取日志
2.主备切换
ZKFC对主NN进行监控,当主NN出现错误或宕机时时,ZKFC发送给zookeeper,Zookeeper让备NN成为主NN
四、元数据持久化
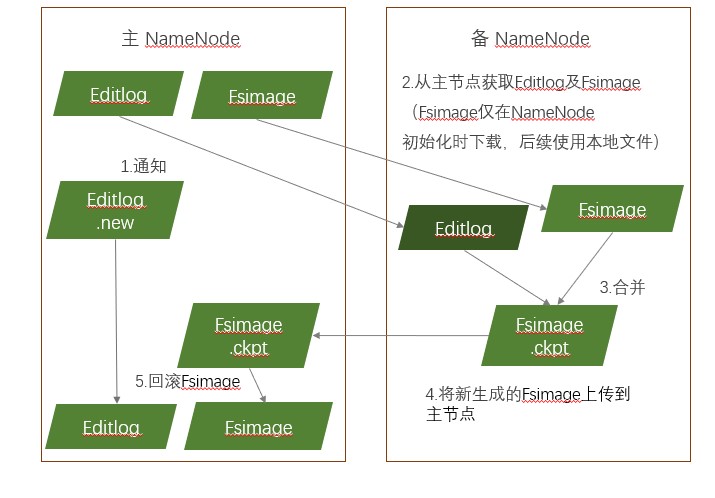
触发条件:每隔1个小时,或editlog满了64M时进行合并
- 备NN通知主NN生成EditLog.new文件
- 从主结点获取FsImage和Editlog
- 将获得的文件进行合并,生成新文件fsimage.ckpt
- 将新文件fsimage.ckpt上传到主NN
- 重命名为fsimage,覆盖原来的fsimage
- 将Editlog.new命名为Editlog
- 根据触发条件循环1-6步骤。
-
五、HDFS联邦 (Federation)
-

-
在使用主Namenode中的元数据,而且是放在内存里面,当数据增到大一定时,会出现内存不够用的状态,namenode内存就成为整个集群的一个瓶颈,为了解决这个问题,将NameNode做一个横向扩展,方案就是Federation,很好的解决了内存过高的问题。
六、HDFS副本策略同一台服务器的距离是0
同一个机架不同的服务器距离为2
不同机架的服务器距离为4
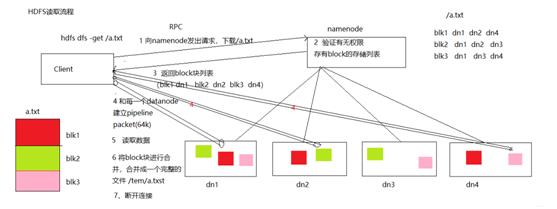
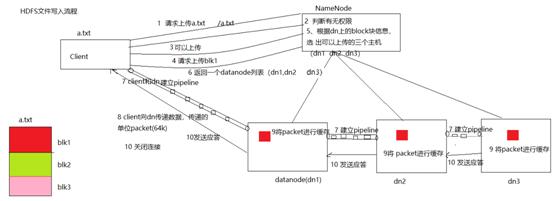
七、HDFS读取流程八、HDFS文件写入流程
九、常用的shell命令
2、 mkdir 创建目录
3、put :上传系统中的文件到HDFS指定的目 录
4、cat 显示文件的内容
7、appendToFile 追加一个文件到已经存在的文件的末尾13、 du 统计文件夹的大小
十、Zookeeper容灾能力
ZooKeeper选举时,当某一个实例获得了半数以上的票数时,则变为leader。
n为奇数时,假定n=2*x+1 ,则成为leader的节点需获得x+1票,容灾能力为x。
n为偶数时,假定 n=2*x+2 ,则成为leader的节点需要获得x+2票 (大于一半),容灾能力为x。
注:由于5台和6台机器构成的集群容灾能力是一样的,所以建议使用奇数个服务器去构建集群,以免造成 浪费。
十一、思考题:
块比磁盘大(磁盘的块一般为512字节),目的是为了最小化寻址开销。块足够大,那么从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。但也不能太大,因为map通常只处理一个块中的数据。如果Map数太少,则作业运行速度会比较慢
3.HDFS的数据在写入时,能够读取到吗?
当数据在写入的时候,写入数据不能立即可见,在命令空间是立即可见的。当写入超过一个块或者结束的时候,对一个新的reader就是可见的。当前正在写入的块,对其他reader是不可见的

以上是关于02HDFS分布式文系统的主要内容,如果未能解决你的问题,请参考以下文章
从设计到实现:HDFS复制流程细节 | 分布式文件系统读书笔记
探秘HDFS —— 发展历史核心概念架构工作机制 (上)| 博文精选
分布式大数据系统概览(HDFS/MapReduce/Spark/Yarn/Zookeeper/Storm/SparkStreaming/Lambda/DataFlow/Flink/Giraph)