面向单目深度估计的基于几何的预训练方式 -- Geometric Pretraining for Monocular Depth Estimation
Posted Levi_Ackerman__
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面向单目深度估计的基于几何的预训练方式 -- Geometric Pretraining for Monocular Depth Estimation相关的知识,希望对你有一定的参考价值。
一些前提知识
Monocular Depth Estimation:单目深度估计,从单张图片中去预测每个像素点具体的深度,相当于从二维图像推测出三维空间。
ImageNet-Pretraining:基于ImageNet的预训练模型,ImageNet是一个带有标签的大数据集,其中有1,000个类别的图像。CV界常在进行下游任务之前,一般会在ImageNet上进行预训练,以学习到图像的语义信息,便于迁移学习。
optical flow:光流,用于研究图像对齐的算法,分为稀疏光流(一般选角点)和稠密光流。
stereo images:立体图像集,由不同角度拍摄的图像集合。
Abstract

| ImageNet-pretrained networks have been widely used in transfer learning for monocular depth estimation. These pretrained networks are trained with classification losses for which only semantic information is exploited while spatial information is ignored. However, both semantic and spatial information is important for per-pixel depth estimation. In this paper, we design a novel self-supervised geometric pretraining task that is tailored for monocular depth estimation using uncalibrated videos. The designed task decouples the structure information from input videos by a simple yet effective conditional autoencoder-decoder structure. Using almost unlimited videos from the internet, networks are pretrained to capture a variety of structures of the scene and can be easily transferred to depth estimation tasks using calibrated images. Extensive experiments are used to demonstrate that the proposed geometric-pretrained networks perform better than ImageNet-pretrained networks in terms of accuracy, few-shot learning and generalization ability. Using existing learning methods, geometric-transferred networks achieve new state-of-the-art results by a large margin. The pretrained networks will be open source soon1 . | 基于ImageNet的预训练网络已经在单目深度估计的迁移学习中广泛的使用了。这些预训练网络都只挖掘出了图像的语义信息而忽略了其空间信息,但它们对于逐像素的深度预测都十分重要。本文中,我们设计了一个新奇的自监督的为单目深度估计量身定做的使用无标定视频进行训练的几何预训练任务。设计的任务通过简单但有效的条件自编码-解码器架构,将结构信息和输入视频解耦。使用来自互联网的几乎没有限制的视频,整个网络架构通过预训练得到场景不同的结构信息,并且可以使用有标注的图像轻松的迁移至单目深度估计任务中。我们做了许多的实验去验证我们的geometric-pretraining模型在精度、小数据学习和泛化能力上表现优于ImageNet-pretraining。使用现有的学习方法,我们的几何迁移网络实现了新的最先进的结果,并且领先了一大截。我们的预训练网络即将开源。 |
目前研究方法 + 存在的问题 + 我们提出的观点 + 我们的优势 + 实验结果
1 Introduction
| Estimating depth maps of images is of vital importance in computer vision and robotics. Benefiting from the development of deep learning, many methods have been proposed to estimate the depth map using a single input image. These methods can be deployed easily and used in a variety of applications such as visual odometry [1], [2], sensor fusion [3], and augmented reality [4]. Although generating impressive results, learning-based methods need a large amount of data for training. Per-pixel depth annotating of real-world images is almost impossible as LiDAR only provides sparse depth measurements, and time-of-flight (ToF) cameras have limited ranges. The KITTI stereo dataset [5] uses CAD models to densify depth measurements of cars but only contains hundreds of images. Yang et al. [6] propose DrivingStereo with more than 180k frames fused from multi-frame LiDAR measurements. Despite the high accuracy depth measurement in DrivingStereo, the density of annotated pixels is less than 15%. Recently, many self-supervised works [7]–[16] have been proposed to train networks using calibrated stereo images or monocular videos. These methods are built on the assumption that images from nearby views can be synthesized correctly if the scene geometry and camera motion are estimated correctly. Compared with using active sensors (e.g., LiDAR and ToF), training with stereo images or monocular videos offers a number of advantages. First and foremost, training data can be captured much more easily without depth labeling, thus a larger variety of data can be used for training. Second, the depth of every pixel can be supervised by minimizing photometric errors. Despite the success of recent selfsupervised methods, the geometric view synthesize process needs camera intrinsic parameters, which requires offline calibration. Because of this, current self-supervised methods cannot utilize the almost unlimited videos from the internet and train a ‘universal’ monocular depth estimation model. To overcome the training data limitations, using networks pretrained on ImageNet [17] classification tasks as training initialization becomes a default choice. The success of transferring ImageNet-pretrained models to other classification tasks has been widely demonstrated and studied [19], [20]. However, transferring networks trained on ImageNet classification tasks for dense depth map estimation has several potential problems. First, classification tasks emphasize semantic feature maps, while the spatial information is ignored. When transferred to spatial-sensitive tasks, e.g. keypoint detection, He et. al. [20] show that ImageNetpretrained networks have limited benefits. Secondly, images from the ImageNet dataset focus on object detection and are very different from images for depth estimation. In this paper, we propose a novel pretraining task that uses wild videos from the internet to capture both semantic and spatial information. Based on the fact that the optical flow between two images is determined solely by the geometric structure and motions (both camera and object motion), we use a conditional encoder-decoder to separate structure information and motion information from uncalibrated videos.The structure information of the scene is encoded from a single image, and motion information is estimated from two adjacent images. The optical flow between two images is finally reconstructed by using the estimated structure information conditioned on the motion vector. Since optical flow can be supervised without camera intrinsic or extrinsic parameters, the pretraining task can utilize unlimited videos from the internet and learn a variety of structures. After the pretraining stage, the encoder network can be easily transferred to depth estimation tasks. Extensive experiments are used to demonstrate the transferred performance of the proposed geometric-pretrained networks. In Figure 1, we show estimated depth maps of ImageNet-pretrained networks and geometric-pretrained networks. Compared with ImageNet-pretrained networks, the proposed networks generate more accuracy and sharper depth estimations and can be generalized to other scenes or datasets. | 估计图像的深度图在计算机视觉和机器人技术中至关重要。受益于深度学习的大环境,许多方法已经被提出,通过单张图片的输入去估计其深度图。这些方法可以轻松部署并用于各种应用程序,例如视觉测程、传感融合以及增强现实。
尽管产生了令人印象深刻的结果,基于学习的方法需要大量的数据用于训练。对于现实生活中的图像的逐像素的深度标注几乎是不可能的,现有的方法有以下问题:(1)稀疏 (2)有范围限制。有人对车辆的深度测量进行增稠,但只有几百张图像;有人对图像进行高精度标注,但是标注像素的稠密度低于15%。最近,研究者们提出了许多自监督的工作使用带标注的立体图像或单目视频去训练网络。这些方法都建立在,如果场景几何和相机运动都能被正确估计,那么临近视图的图像可以被正确估计的假定之下。
相较于使用传感器,使用立体图像集或单目视频提供了一些列优势。(1) 训练数据可以不适用深度标注就被被轻松地获取,因此可以使用多种数据进行训练。(2) 每个像素的深度可以通过最小化光度误差被监督。尽管最近的自监督方法很成功,但几何视图合成过程需要相机内在参数,这需要离线标注, 因此目前的自监督方法无法利用无限制的来自互联网的视频来训练“通用”的单目深度估计模型。 为了克服训练数据的限制,使用在ImageNet分类任务上预训练的网络作为初始化成为了大家的默认选择。
ImageNet Pretraining针对其他分类任务的迁移学习已经被证实了是很大的成功。但是,ImageNet针对单目深度估计的迁移学习有几个潜在的问题。(1) 分类任务强调语义特征图,但是空间上的信息被忽略了。针对空间敏感的任务,ImageNet的预训练效果不显著。 (2) ImageNet上的图片集中在对象检测上,这和深度估计所使用的图片非常不一样。
本文中,我们提出了一个新奇的与训练任务,它使用来自互联网的视频去抓取语义信息和空间信息。由于两张图象之间的光流仅仅由几何结构和运动(相机运动和对象运动)决定,我们使用了一种条件编码-解码器来从未标注的视频中分离结构信息和运动信息。结构信息由单张图片编码得到,运动信息则由两个相邻的图像估计得到。两个图像之间的光流最终会以运动向量为条件使用估计的结构信息去重建。由于光流可以不需要相机内置或外置的参数被监督,预训练任务可以使用无限制的来自互联网的视频并且学习到多种结构类型。在预训练阶段结束后,编码网络可以被轻松的迁移到深度估计任务中。
实验证明,我们的模型....,我们提供了更准确、更锋利的深度估计,并且可以泛化到其他的场景或者数据集上。 |
2 Related Work
2.1 Self-supervised Depth Learning
| Due to the limited quantity of images with depth annotation, using stereo images or monocular videos to learn the depth map has become attractive to researchers and industry. The core concept of self-supervised learning is that with accurate geometric prediction and poses from calibration or estimation, images from nearby views can be correctly reconstructed. Garg et. al. [7] propose a pioneering method that minimizes the photometric error between reconstructed images and the second view image. Subsequent works [21]– [23] improve the depth quality by incorporating discriminating losses and improving the depth resolution. Compared with rectified and synchronized stereo images, calibrated monocular videos are easier to capture. SfMLearner [8] extends the self-supervised method from synchronized stereo images to calibrated monocular videos by estimating the camera motion between two frames by a deep network. However, in monocular cases. pixels of dynamic objects cannot be reconstructed correctly using only the camera motion. A number of works [15], [18], [24] have been proposed to mask dynamic objects or explicitly estimate the motion of each rigid dynamic object using semantic masks. GLNet [25] further estimates intrinsic parameters such that it can be trained on uncalibrated pinhole images. | 由于带深度标注的图片数量有限,人们常使用立体图像或单目视频来学习深度图。自监督学习的核心概念是,使用从标注或估计中得到的精准的几何预测和机位,来正确重建图像的邻近视图。XXX提出一种先进的方法最小化重构图像和第二视角图像之间的光度误差。后续工作通过结合判别损失和提高深度分辨率来提高深度估计质量。相较于带有校正和同步的立体图像,带标注的单目视频更容易捕捉。XXX通过深度网络估计两个图像帧之间的相机运动,从而将自监督方法从同步的立体图像集推广到带标注的单目视频上。但是,在单目的情况下,仅使用相机运动信息,动态对象的像素无法被正确重建。许多工作已经提出屏蔽动态对象,或者使用语义掩码精确估计每个刚性动态对象的运动。XXX进一步估计了相机内在参数,使得它可以在未标注的的针孔图像上进行训练。 |
2.2 Transfer Learning
迁移学习,这一部分在BERT中也介绍过了,这里就简述一下内容。
迁移学习可以加快训练过程,提高模型精确度。ImageNet-Pretaining在迁移至小规模训练数据的下游任务时,在分类任务中取得了很好的效果,但在空间信息上效果不明显。有研究证明,深度估计学习与正则估计、闭塞估计关系更加紧密,而和语义分割、对象分类关系不大。(然后介绍了一系列预训练任务...存在一些缺点,模型复杂、效率低、精度不够等等...)接下来明确工作,提出几何预训练任务。(把上面提到的模型的优点又叙述了一遍)
3 Geometric Pretraining
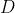 | source frame(源帧)的深度图 |
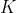 | 相机的内置参数 |
 | 用于表示相机运动和对象运动的齐次坐标矩阵 |
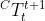 | 相机在第 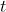 帧和第 帧和第  帧间的运动齐次坐标 帧间的运动齐次坐标 |
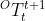 | 对象在第 |
 | 像素点 |
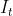 | 第 |
用于表示相机和对象运动地齐次坐标矩阵 :

其中,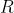 是旋转矩阵, 是平移矢量,代表相机的运动,代表对象的运动。
是旋转矩阵, 是平移矢量,代表相机的运动,代表对象的运动。
像素点从到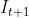 的光流可以如下计算得到:
的光流可以如下计算得到:
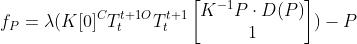
其中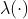 是归一化函数。对于静态对象的像素点,是一个相同的矩阵。相较于和图像一样大小的稠密的深度图,运动矩阵可以只由6个参数构成。在动态环境中,不同的运动矩阵的个数即为独立运动对象的个数,远少于图像中的像素点个数。
是归一化函数。对于静态对象的像素点,是一个相同的矩阵。相较于和图像一样大小的稠密的深度图,运动矩阵可以只由6个参数构成。在动态环境中,不同的运动矩阵的个数即为独立运动对象的个数,远少于图像中的像素点个数。
几何预训练任务的核心是将结构信息与光流分离。使用条件编码-解码器,光流以两个图像间的运动信息为条件,使用来自单张图片的结构信息被重构。通过低维瓶颈压缩运动信息,结构编码器被迫捕捉以运动信息的定量的结构信息,所以光流可以被正确估计。
3.1 Framework

3.1.1 Structure Encoder
结构编码器使用source image作为输入,并且输出特征图作为光流解码器的输入。因此训练好的结构编码器将会作为深度估计的主干网络使用,而不需要其他的架构。在这次的工作中,我们使用标准的ResNet-18进行绝大多数的实验,来和monodepth2保持一致。(这里的monodepth2我也不清楚具体细节,但是是一种经典的单目深度估计自监督学习模型。)
3.1.2 Motion Encoder
运动编码器使用两张邻近图像作为输入,并且输出一个小规模的动作向量。动作编码器的目的和GeoNet中pose networks相似,是为了估计运动信息。与其不同的是,我们提出的动作编码器使用特征向量生成运动信息。我们和monodepth2一样,使用一个调整过带有bottleneck layer(一个 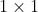 的卷积层,先降维,进行卷积计算后,再把维度升回去)的ResNet网络去生成仅有128维的特征运动向量。相较于光流的维度
的卷积层,先降维,进行卷积计算后,再把维度升回去)的ResNet网络去生成仅有128维的特征运动向量。相较于光流的维度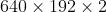 ,运动向量仅占总数据量的不到0.1%,因此运动向量只会编码必要的运动信息。
,运动向量仅占总数据量的不到0.1%,因此运动向量只会编码必要的运动信息。
3.1.3 Flow Decoder
光流解码器用于融合结构编码器和运动编码器的信息。运动向量经过上采样然后与结构编码器的特征图级联。解码器由几个最近邻插值上采样层nearest-upsample layer和残差连接构成,去重构 到 间的光流信息。我们的光流解码器包含14层,相较于一般的解码器网络规模较小。为了加速训练收敛,光流 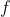 以由粗到细的粒度被估计。
以由粗到细的粒度被估计。
总之,我们提出的架构和单目监督深度学习很像,但我们的与训练结构目的是续写到整体的结构心儿,因此不会精确地预测深度和机位信息。
补充信息:
nearest-upsample,采用最近邻插值的上采样方法,具体流程如下:
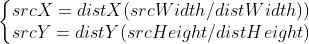
3.2 Loss Function
两帧间的光流可基于光度一致性假设计算。在预训练过程中,损失函数由光度损失photometric term和一个平滑损失smoothness term组成:
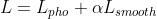
其中,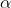 是平滑项的学习率。
是平滑项的学习率。
光度误差测量的是,源图像和经过变形的图像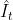 ,其中
,其中  。有研究表明L1 loss和ssim loss结合在一起可以得到锋利的深度图,我们使用了他们的想法:
。有研究表明L1 loss和ssim loss结合在一起可以得到锋利的深度图,我们使用了他们的想法:

平滑损失表示如下:
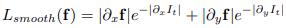
与前人的工作类似,我们选取  来平衡误差项。
来平衡误差项。
补充信息:
simm loss, 原像质量损失函数,把图的相似性分为三部分比较,亮度  ,对比度
,对比度 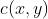 和结构
和结构 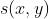 ,SSIM的值介于0到1之间,SIMM值越大,图像相似度越接近。
,SSIM的值介于0到1之间,SIMM值越大,图像相似度越接近。
L1 loss,相较于L2 loss对异常点不太敏感(L2 对异常点存在放大效果)。
smoothness loss,在没有纹理的区域产生精确一直的注意力机制,从而实现水平和垂直方向的注意力一致。
3.3 Pretraining Dataset
三个数据集:KITTI(平均光流小于 1 个像素的静态帧被删除),CityScapes(多了很多动态对象),Driving Videos(无标注、体量大)
3.4 Training Details
使用ImageNet-prectrained网络作为初始化 --> geometric-pretraining --> 迁移学习至depth-learning
使用Adam优化器,学习率选择0.0001。
4 Depth Learning Fine-tune
使用monodepth2框架进行depth-learning,因为它简单、有效,可以很好的体现到预训练网络的有效性。
单目监督学习中,图像三元组 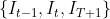 作为输入,估计相邻帧的机位和深度图
作为输入,估计相邻帧的机位和深度图 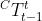 和 ,从而计算出光流(monodepth2中忽略
和 ,从而计算出光流(monodepth2中忽略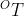 ),对应的参考图像将被重建为
),对应的参考图像将被重建为  (使用
(使用 )) 和
)) 和  (使用)) 。不同于应用于预训练中的光度损失的是,monodepth2用过逐像素地优化最小光度误差来处理遮挡的和动态的对象。
(使用)) 。不同于应用于预训练中的光度损失的是,monodepth2用过逐像素地优化最小光度误差来处理遮挡的和动态的对象。

5 Experiments
实验效果见原文,这里略
6 Conclusion
| We propose a simple but effective pretraining task, called geometric pretraining, that is designed for monocular depth learning. The pretraining task only requires uncalibrated monocular image sequences and thus can utilize unlimited resources from the Internet. Extensive experiments are used to prove that, in terms of depth transfer learning, the proposed geometric pretrained model performs better in accuracy, few-short learning, and generalization ability compared to ImageNet-pretrained networks. The pretraining task can also be used to generalize depth learning into specific scenes without the calibration or synchronization of cameras. In the future, we plan to improve the pretraining tasks that can further decouple each independent moving object. The driving videos dataset will also be further expanded due to the observation that a larger dataset benefits the performance of transferred models. | 我们为单目深度学习提出了而一个简单但有效的预训练任务,称为Geometric Pretraining。预训练任务只需要未标注的弹幕图像序列,因此可以利用无限制的来自于互联网的资源。大量的实验已经证明了我们提出的几何预训练模型,在深度估计迁移学习中,在精确度、小样本学习、泛化能力上相较于ImageNet Pretraining表现的更好。这个预训练任务还可以将深度学习泛化到具体的场景,而不需要相机的校准和同步。
未来,我们计划改进这个预训练任务去进一步将每个独立的移动对象解耦。行车记录视频数据集也将被进一步扩大,因为更大的数据集会带来更好的迁移学习效果。 |
结束!
以上是关于面向单目深度估计的基于几何的预训练方式 -- Geometric Pretraining for Monocular Depth Estimation的主要内容,如果未能解决你的问题,请参考以下文章