爬虫selenium实战--爬取知乎评论
Posted 可可卷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫selenium实战--爬取知乎评论相关的知识,希望对你有一定的参考价值。
🍬 博主介绍
- 👨🎓 博主介绍:大家好,我是可可卷,很高兴和大家见面~
- ✨主攻领域:【数据分析】【机器学习】 【深度学习】 【数据可视化】
- 🎉欢迎关注💗点赞👍收藏⭐️评论📝
- 🙏作者水平很有限,欢迎各位大佬指点,一起学习进步!

📚文章目录
🍭0 教程说明
使用selenium可以直接获得加载后的网页信息而无需考虑请求信息,Ajax,js解密等等,可谓偷懒神器,下面以 你读懂带土了吗? - 知乎
https://www.zhihu.com/question/375762710 为例,进行实战讲解
特殊声明:本教程仅供学习,若被他人用于其他用途,与本人无关
🥚🥚🥚我是分割线🥚🥚🥚
🍭1 分析url
分析网址,可以发现网址是https://www.zhihu.com/question/ + question_id,因此可以通过下述代码构建url:
try: option = webdriver.ChromeOptions() option.add_argument("headless") option.add_experimental_option("detach", True) driver = webdriver.Chrome(chrome_options=option) driver.get('https://www.zhihu.com/question/'+question_id) except Exception as e: print(e) finally: driver.close()
🥚🥚🥚我是分割线🥚🥚🥚
🍭2 关闭登录弹窗
进入网页,由于未登录,因此会出现登录弹窗,我们可以通过Xpath和CSS选择器的方式获取关闭按钮,模拟点击操作
# 先触发登陆弹窗。 WebDriverWait(driver, 40, 1).until(EC.presence_of_all_elements_located( (By.CLASS_NAME, 'Modal-backdrop')), waitFun()) # 关闭登陆窗口 driver.find_element_by_xpath('//button[@class="Button Modal-closeButton Button--plain"]').click()

🥚🥚🥚我是分割线🥚🥚🥚
🍭3 获取所有答案
由于知乎是动态加载,需要将滚轮滑动到底部才能获得全部答案,因此需要运行js获得页面高度,并模拟滚轮下滑
def waitFun(): js = """ let equalNum = 0; window.checkBottom = false; window.height = 0; window.intervalId = setInterval(()=> let currentHeight = document.body.scrollHeight; if(currentHeight === window.height) equalNum++; if(equalNum === 2) clearInterval(window.intervalId); window.checkBottom = true; else window.height = currentHeight; window.scrollTo(0,window.height); window.scrollTo(0,window.height-1000); ,1500)""" driver.execute_script(js) def getHeight(nice): js = """ return window.checkBottom; """ return driver.execute_script(js) # 当滚动到底部时 WebDriverWait(driver, 40, 3).until(getHeight, waitFun()) # 等待加载 sleep(1)
🥚🥚🥚我是分割线🥚🥚🥚
🍭4 获取标题和副标题
需要注意,有些问题是没有副标题的,因此也不存在副标题的element
title=driver.find_element_by_xpath('//h1[@class="QuestionHeader-title"]').text subtitle = driver.find_element_by_xpath('//span[@class="RichText ztext css-hnrfcf"]').text
🥚🥚🥚我是分割线🥚🥚🥚
🍭5 展开评论
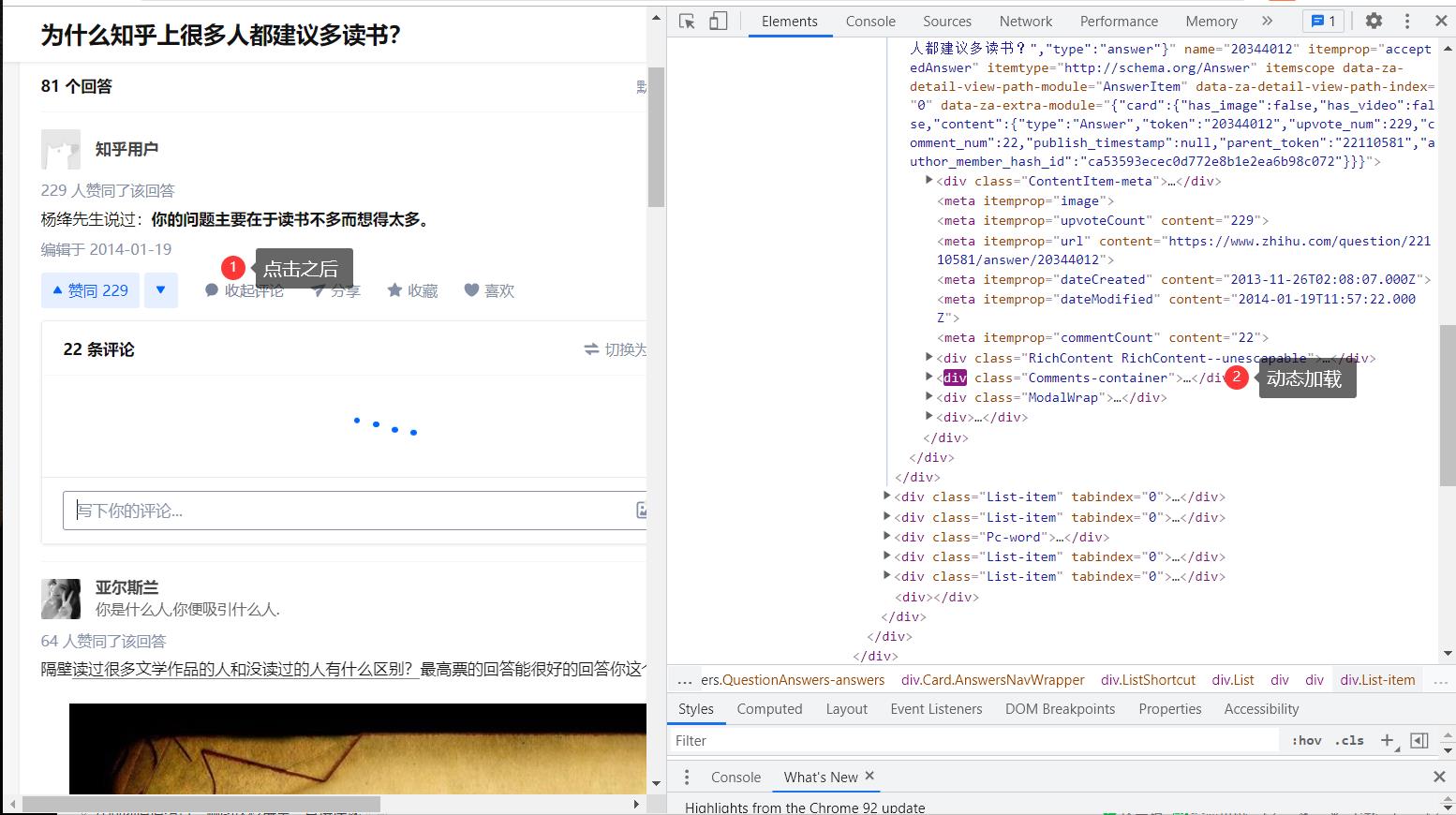
由于评论的数据并不包含在页面中,而需要点击 “XX条评论” 按钮后才进行动态加载,因此需要模拟点击这些按钮
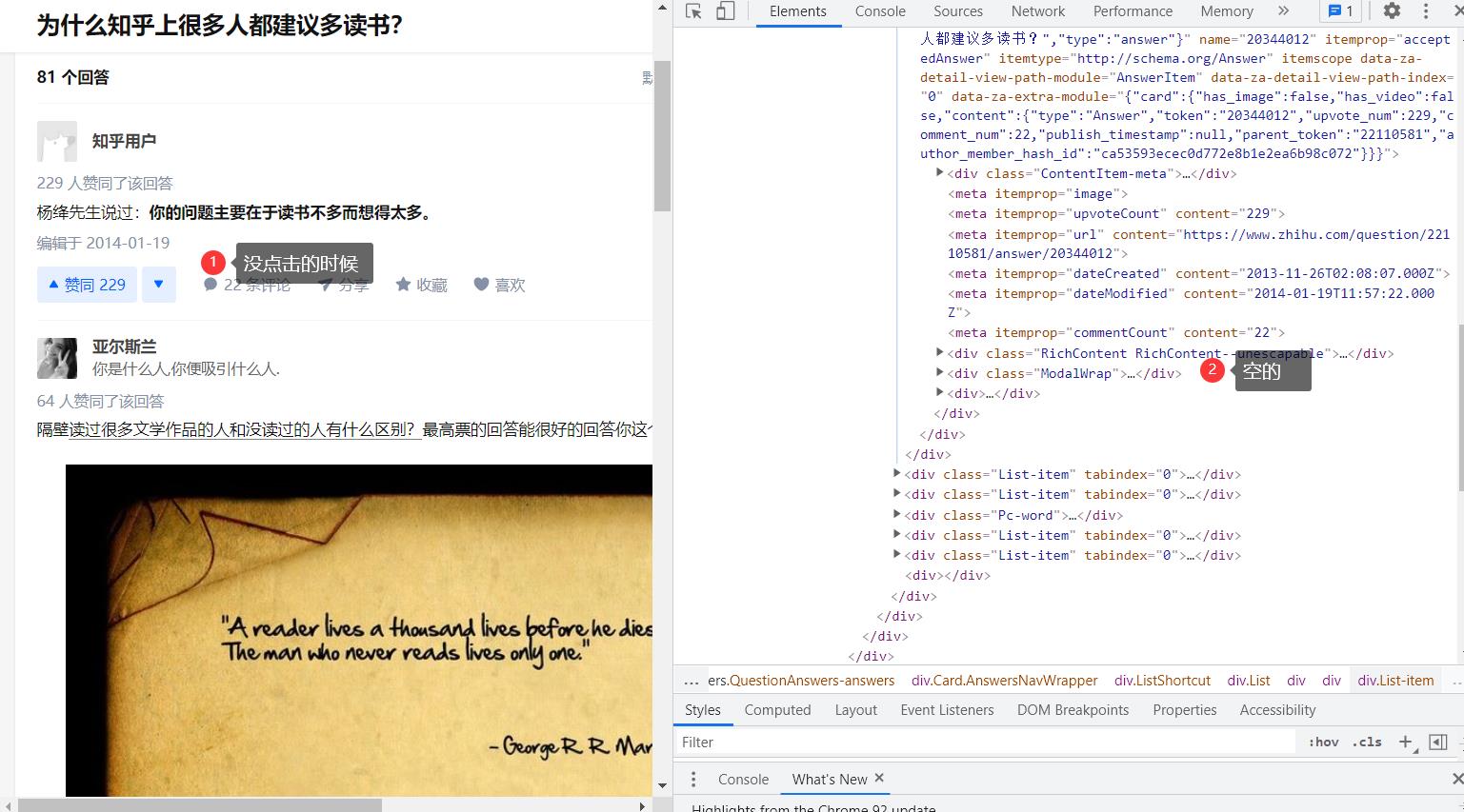
wait=WebDriverWait(driver,30) #显式等待 path=(By.XPATH,'//button[@class="Button ContentItem-action Button--plain Button--withIcon Button--withLabel"]') clicks=wait.until(EC.presence_of_all_elements_located(path)) for c in clicks: if '条' in c.text: driver.execute_script("arguments[0].click();", c) sleep(0.1)
🥚🥚🥚我是分割线🥚🥚🥚
🍭6 按块获取答案
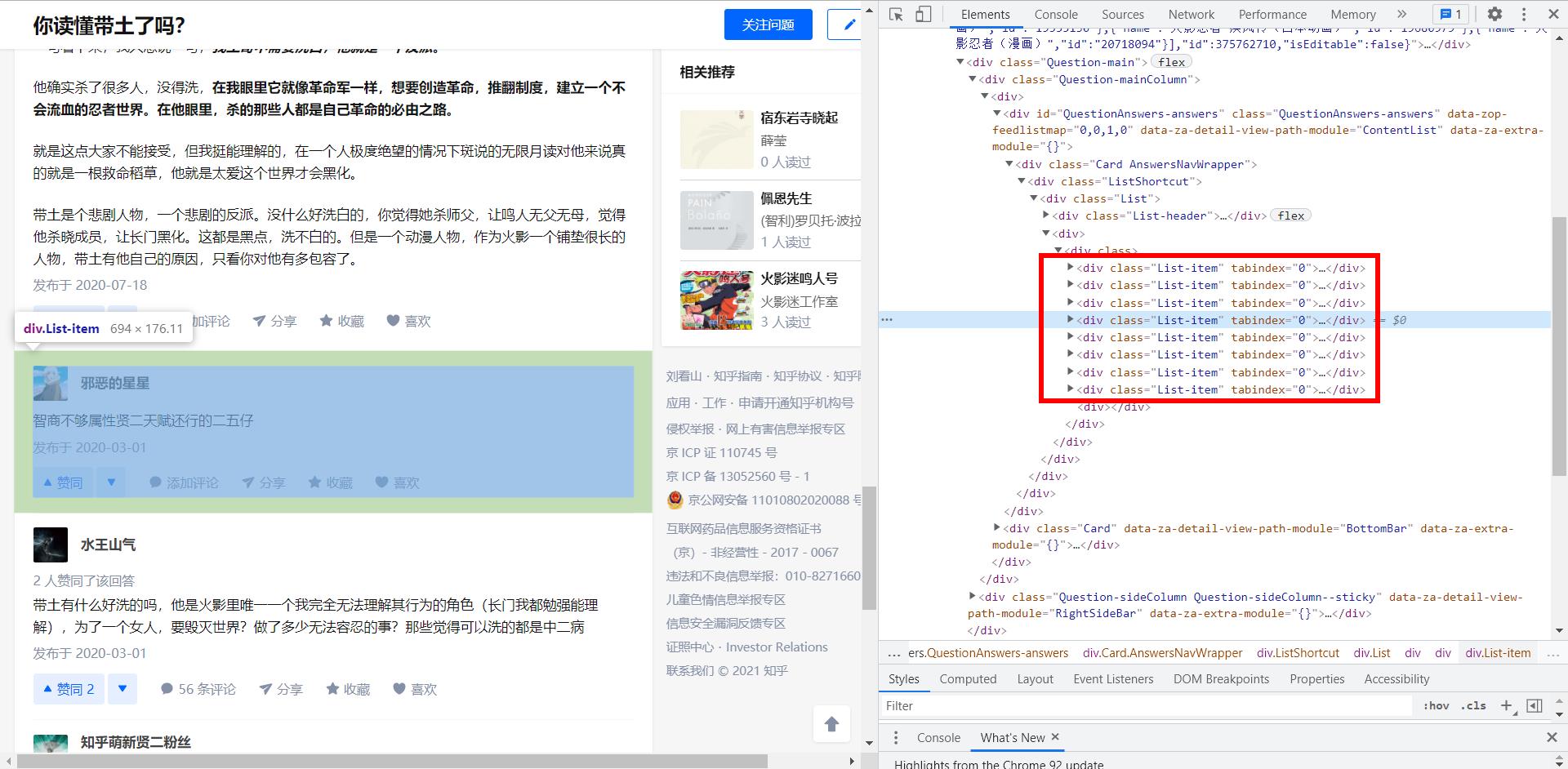
先分析得到每一个问题的答主信息、回答内容、评论都在 “List-item”下
然后在每一块元素的基础上,在进行答主信息、回答内容、评论的查找
# get blocks blocks=driver.find_elements_by_xpath('//div[@class="List-item"]') res=[] for b in blocks: author = b.find_element_by_xpath('.//div[@class="ContentItem-meta"]//meta[@itemprop="name"]').get_attribute('content') content = b.find_element_by_xpath('.//div[@class="RichContent-inner"]').text # button=b.find_element_by_xpath('.//div[@class="ContentItem-actions"]//button[contains(text(),"评论")]') button=b.find_element_by_xpath('.//button[@class="Button ContentItem-action Button--plain Button--withIcon Button--withLabel"]') if '收起' in button.text: comment = b.find_elements_by_xpath('.//ul[@class="NestComment"]') comments='' for c in comment: comments+=c.text print(comments) sleep(0.2) else: comments = '无评论' tmp='author':author,'content':content,'comments':comments res.append(tmp)
🥚🥚🥚我是分割线🥚🥚🥚
🍭7 保存信息
🍥7.1 json
json_str = json.dumps(res) with open(filename+'.json', 'w',encoding='utf-8') as json_file: json_file.write(json_str)
🍥7.2 csv
df = pd.DataFrame(res) df.to_csv(filename+'.csv')
🍥7.3 txt
cwd=os.getcwd() with open(cwd++filename+'.txt','a',encoding='utf-8')as f: for i,r in enumerate(res): f.write(f'第i+1个回答'.center(30,'=')) f.write('\\n') f.write(f'author:r["author"]\\n') f.write(f'content:r["content"]\\n') f.write(f'comments:\\nr["comments"]\\n')
🍥7.4 数据库
通过pymysql或pymongo保存到数据库中,有兴趣的可以再去了解
🥚🥚🥚我是分割线🥚🥚🥚
🍭8 结语
不知道大家在爬取之前,是否注意到知乎遵循了robots协议(没有关注过的可以点击这个网址:https://www.zhihu.com/robots.txt)
为了不给网站的管理员带来麻烦,希望大家在爬取的时候能尽量遵循robots协议;若在学习过程中在不可避免地无法遵循robots协议,也尽量维持爬虫爬取频率与人类正常访问频率相当,不过多占用服务器资源。
以上是关于爬虫selenium实战--爬取知乎评论的主要内容,如果未能解决你的问题,请参考以下文章