Python正则表达式使用
Posted 涤生手记大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python正则表达式使用相关的知识,希望对你有一定的参考价值。
小练习:用代码实现自定义的replace_practice替换函数,实现代码如下:功能是将字符串中所包含的空格替换为mm
def replace_practice(str,a,b,count=None):
i=0
#记录替换count次数
n=0
result=[]
if count==None:
count=len(str)
while i<len(str) and len(str)!=0 and n<count:
if str[i:i+len(a)]==a:
result+=list(str[0:i])+list(b)
str=str[i+len(a):]
n+=1
i=0
else:
i+=1
result.append(str)
return ''.join(result)
if __name__ == '__main__':
string = '** *112567* *abc** *98765** **xyz***'
print(string)
a = []
print('替换结果:',replace_practice(string,' ','mm'))
可以看到,函数replcae_parctice主要是将每个空格替换为两个m字符串。当然,实际的开发中还会存在不同的替换功能需要自行实现(或者其它),但Python内置的字符串函数可以解决很大一部分功能,节省了开发人员的工作时间,提升了开发效率,非常高效。今天的重点在于正则在Python中的使用,正则表达式是一种特殊的字符序列,用于处理更为复杂的字符串,方便开发人员检查一个字符串是否与某种模式匹配。简单来说,正则表达式就是一种简练描绘一组字符串的方式,可用于高效地执行常见的字符串处理任务,如匹配、分拆和替换(比Python字符串函数功能更为强大)。
1 正则表达式
依据维基百科,正则表达式是对字符串操作的一种逻辑公式,其功能主要是对定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。特点包含以下几点:
1.灵活性、逻辑性和功能性非常强;
2.迅速地用极简单的方式达到字符串的复杂控制;
3.对于初学者有些不太友好,比较难懂。
既然正则表达式对于使用者不太友好,那任何一种语言都极力推荐它的原因是什么?该表达式可以帮助开发者们从字符串中匹配到要的特定部分,主要用于它可以:
1.测试字符串内的模式:例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证,数据处理等;
2.基于模式匹配从字符串中提取子字符串:可以查找文档内或输入域内特定的文本;
3.替换文本:可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。
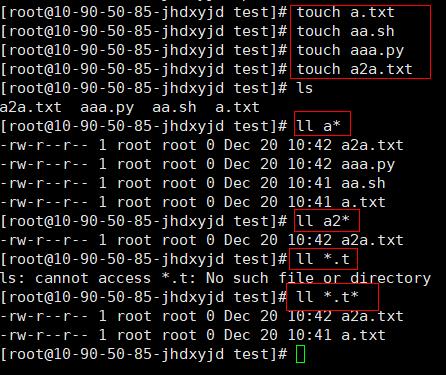
举一个简单的正则表达式:例如几个字符串 'a.txt' , 'aa.sh' , 'aaa.py' , 'a2a.txt' ,简单的使用shell命令(python基本类似)查看如下图,正则表达式 'a*'表达了所有含a的字符串,'a2*' 仅表示 'a2a.txt' ,也请注意正则匹配的用法。
Python 在正则表达式中,可使用圆括号来指出要将运算符用于那个子串。例如,正则表达式 '(ha)+!'描述了如下字符串:'ha!'、'haha!'、'hahaha!' 等;而 'ha+!' 描述了一组截然不同的字符串:'ha!'、'haa!'、'haaa!' 等。
1.1 正则匹配字符串
匹配字符串是正则表达式的一种常见使用。例如,假设你要编写一个程序,要求必须输入 finished或 failed 来结束程序。
def judge(string):
return string == 'finished' or string == 'failed'当然,Python提供了一个功能十分强大的正则函数模块:re 。上述judge()函数等同于下面的代码:第1行导入Python 的标准正则表达式库。为匹配正则表达式,使用了函数 re.match(regex, string),它在 regex 与 string 不匹配时返回 None,否则返回一个特殊的正则表达式匹配对象。在这个示例中,不需要关心匹配对象的细节,只检查返回值是否为 None。
import re
def judge_re(string):
#return string == 'finished' or string == 'quit'
return re.match('finfished|failed',string) != None对比这两个功能相同的函数,我们发现:judge_re()函数并不比judge()函数代码少,但在使用中会发现,随着程序逻辑的复杂性,代码量越来越大,re模块的优秀会让人越勇越爽。可以在judge()函数中多加几个判断完成的字符串在体验一下,对于judge_re,只需要将re.match括号引号内改为 'done|quit|over| finished|end|stop' ,而judge则需要多加or来完成,使得代码的阅读感直线下降。
更复杂一下,程序函数需要实现取出开头为一个或多个 'tian' ,末尾为 'ha' 的字符串,使用Python自带的正则表达式则十分简单,许多更详细的案例可以参考官网: http://docs.python.org/3/ library/re.html
import re
def get_string(s):
return re.match('(tina)+(ha)+', s)!= None1.2 Python正则语法
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
1.2.1 普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符,包括所有大写和小写字母、数字、标点符号和部分其它符号:
| 字符 | 描述 |
| [ABC] | 匹配 [...] 中的所有字符,例如 [lbk] 匹配字符串 "lihao bato kechen" 中所有的 l b k字母 |
| [^ABC] | 匹配除了[...] 中的所有字符,例如 [^lbk] 匹配字符串 "lihao bato kechen" 中除了 l b k 的字母 |
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母 |
| [\\s\\S] | 匹配所有。\\s 是匹配所有空白符,包括换行,\\S 非空白符,不包括换行 |
| \\w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
| . | 匹配除换行符(\\n、\\r)之外的任何单个字符,相等于 [^\\n\\r] |
1.2.2 非打印字符
| 字符 | 描述 |
| \\cx | 匹配由x指明的控制字符 |
| \\f | 匹配一个换页符 |
| \\n | 匹配一个换行符 |
| \\r | 匹配一个回车符 |
| \\s | 匹配任何空白字符,包括空格、制表符、换页符等等,等价于 [ \\f\\n\\r\\t\\v] |
| \\S | 匹配任何非空白字符,等价于 [^ \\f\\n\\r\\t\\v] |
| \\t | 匹配一个制表符,等价于 \\x09 和 \\cI。 |
| \\v | 匹配一个垂直制表符,等价于 \\x0b 和 \\cK。 |
1.2.3 特殊字符
| 特别字符 | 描述 |
| $ | 匹配输入字符串的结尾位置 |
| ( ) | 标记一个子表达式的开始和结束位置 |
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次,要匹配 + 字符,请使用 \\+ |
| . | 匹配除换行符 \\n 之外的任何单字符 |
| [ | 标记一个中括号表达式的开始 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符 |
| \\ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集 |
| 标记限定符表达式的开始 | |
| | | 指明两项之间的一个选择 |
大数据系列文章后期首发公众号:“涤生手记大数据”
欢迎大家关注交流哈,有优秀的原创文章也投递给我,有偿知识分享。
1.2.4 限定字符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 n 或 n, 或 n,m 共6种。
| 字符 | 描述 |
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次 |
| ? | 匹配前面的子表达式零次或一次 |
| n | n 是一个非负整数。匹配确定的 n 次 |
| n, | n 是一个非负整数。至少匹配n 次 |
| n,m | m 和 n 均为非负整数,其中n <= m |
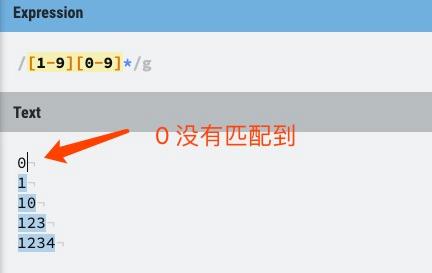
如下,匹配一个正整数,[1-9]设置第一个数字不是 0,[0-9]* 表示任意多个数字:
/[1-9][0-9]*/
1.3 Python正则运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 描述 |
| \\ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, n, n,, n,m | 限定符 |
| ^, $, \\任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,"或"操作,字符具有高于替换运算符的优先级 |
2 Re正则模块
正则表达式一般涉及了许多复杂的过滤规则与匹配条件,我们在此不做过多的赘述。主要目的想夸一夸Python中 re 模块的强大功能!自从1.5版本增加了re 模块后,Python语言自此拥有了全部的正则表达式功能。
2.1 re.match函数
该函数主要从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none;
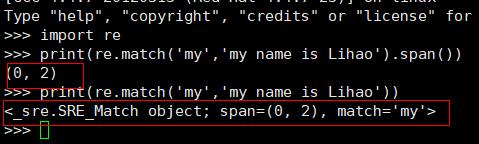
import re
string = "Banana are samller than durian "
# .* 表示任意匹配除换行符(\\n、\\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
match_test = re.match( r'(.*) are (.*?) .*', string, re.M|re.I)
print(match_test.group())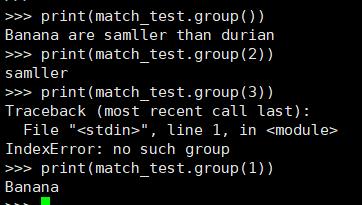
注意:以下我们修改了string字符串内容,同样的匹配规则在这里就报了错误异常,这是因为match函数只能从头开始匹配,不能从中间开始。而当返回值为none时,再次调用group()方法就会出现AttributeError: 'NoneType' object has no attribute 'group',其中,re.I:是匹配对大小写不敏感;re.M:多行匹配 (用到的时候最好用去模块中查询)。
import re
string = "My favourite color is blue"
match_test = re.match( r'(.*) are (.*?) .*', string, re.M|re.I)
print(match_test.group())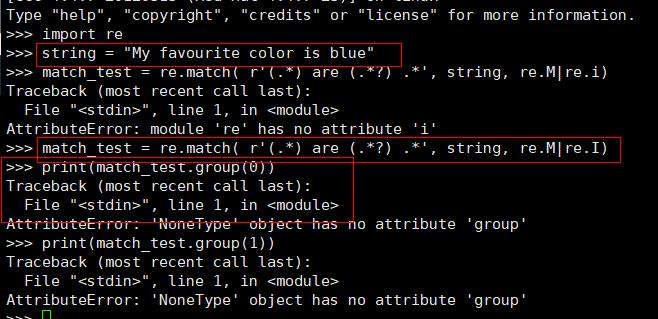
可能有些同学不太理解match函数中的group等参数的含义,这就需要我们去阅读模块内的参数作用及用法,本次给出match函数相关参数、匹配对象方法及作用,如下表:
参数说明:
| 参数 | 描述 |
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等 |
匹配对象方法说明:
| 匹配对象方法 | 描述 |
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号 |
2.2 re.search函数
re.search 扫描整个字符串并返回第一个成功的匹配。
import re
string = "Banana are samller than durian "
match_test = re.search( r'(.*) are (.*?) .*', string, re.M|re.I)
print(match_test.group())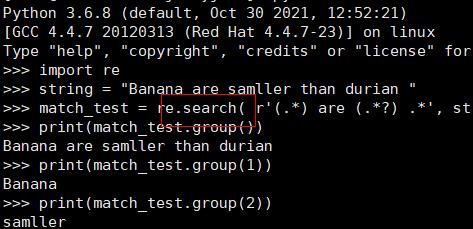
将上一个示例match函数修改为search,可以看到执行结果是一样的。这二者的区别只是在于re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
Re 模块也提供了其它功能,如re.sub()函数提供了替换字符串的功能,re.compile()函数则用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。各位感兴趣的可以自行深入re模块官网学习,最后再留一个关于正则表达式的小练习:匹配出以下字符串所有url。不要用循环去判断哦,最好使用Python Re模块实现,需要自定义complie方法实现过滤规则哦。
str1 = '你好哇 大佬 www.google.com'
str2 = '哇 www.baidu.com 打不开了'
str3 = 'python网址在哪儿 https://www.python.com 找到了'以上是关于Python正则表达式使用的主要内容,如果未能解决你的问题,请参考以下文章