MySQL性能,杀疯了
Posted Hollis Chuang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL性能,杀疯了相关的知识,希望对你有一定的参考价值。
今天,我们就来到了mysql的最后一部分——MySQL性能!
下图是我们涉及到的知识点,主要也是根据我们实际工作中运用比较多,或者经常遇到的问题提出的。相比之前的理论知识,可以说实用性和实战性非常强了!
MySQL上手起来其实很快,但是要深入研究还是不容易,性能调优就是最大的拦路虎,搞定了这只拦路虎,我们就能把MySQL运用自如了。
好了,话不多说,现在,我们就继续来体验这场MySQL的沉浸式面试吧!



性能常识和调优思路

MySQL性能怎么样?


嗯……我之前做过测试,在MySQL5.5版本,普通8核16G的机器,一张100万的常规表,顺序写性能在2000tps,读性能的话,如果索引有效,tps在5000左右。


当然,实际性能取决于表结构、SQL语句以及索引过滤等具体情况,需要以测试结果为准。

不同版本的MySQL性能差距非常大,不同云厂商提供MySQL做的优化也不尽相同,不同业务数据模型也有区别,只有经过测试的数据才有意义。
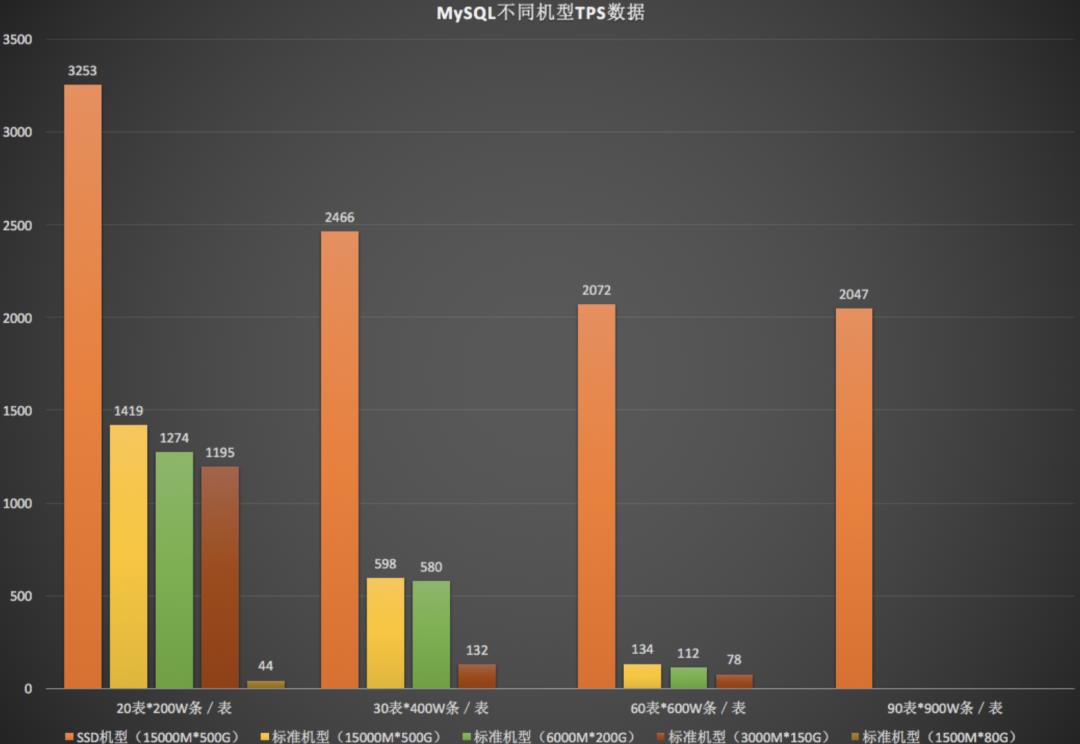
下图是ucloud团队针对MySQL的基础测试,我们在实际使用中最好也实测一下。

那下面来谈谈MySQL的调优思路吧。


主要有三个维度:首先,针对SQL语句进行优化,包括索引优化、特定查询优化;其次,是对频率控制优化,包括读缓存,写缓冲;最后,如果规模过大,就分库分表。


那要怎么找到MySQL执行慢的语句呢?


我们可以看慢查询日志,它是MySQL提供的一种日志记录,用来记录在MySQL中响应时间超过阀值的语句,这个阈值通常默认为10s,也可以按需配置。


Mysql是默认关闭慢查询日志的,所以需要我们手动开启。



那找到慢语句之后,怎么查看它的执行计划?


使用explain命令,它可以获取到MySQL语句的执行计划 ,包括会使用的索引、扫描行数、表如何连接等信息。


通过这个命令,我们很容易就看出一条语句是否使用了我们预期的索引,并进行相应的调整。



怎么调整呢?


数据是在不断变化的,同时执行器也有判断失误的情况,MySQL有时候的执行计划,会出乎意料。


这种情况,我们可以使用语句强行指定索引:
select xx from table_name force index (index_name) where ...


那MySQL索引对性能影响大吗?


索引可以说是给MySQL的性能插上了翅膀。没有索引查找一个Key时间复杂度需要O(n),有索引就降低到了O(logn)。


在数据少的时候还不明显,多一些数据,比如100万条数据,不走索引需要遍历100万条数据,如果能走索引,只需要查找1000条数据。所以有无索引,性能天差地别。

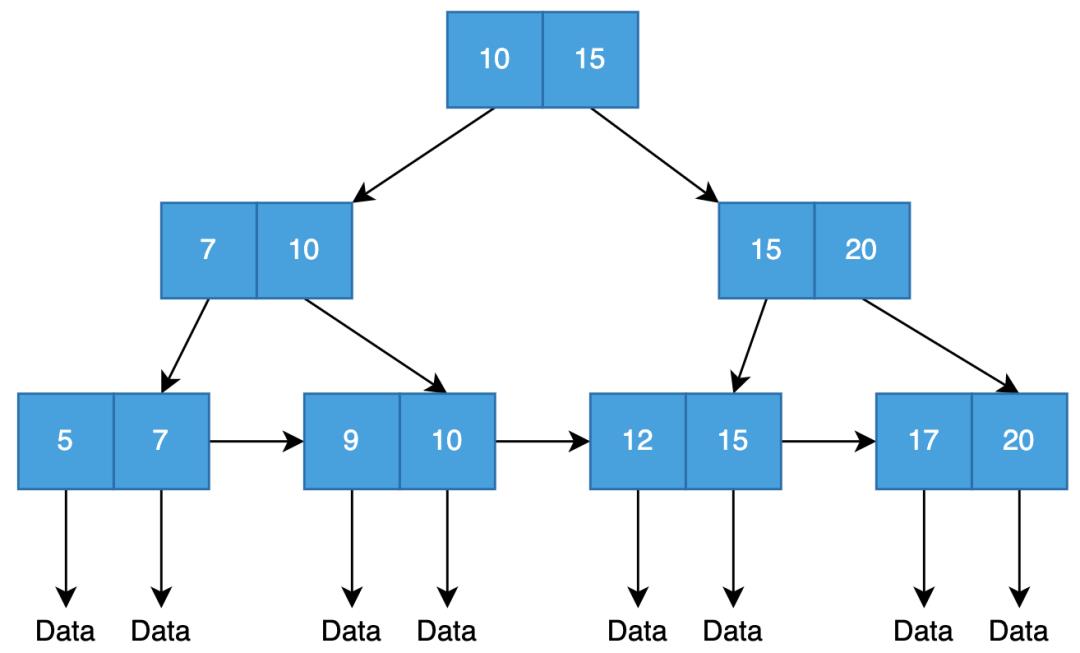

MySQL如果查询压力太大该怎么办?


如果SQL语句已经足够优秀。那么就看请求压力是否符合二八原则,也就是说80%的压力都集中在20%的数据。


如果是,我们可以增加一层缓存,常用的实现是在MySQL前加个Redis缓存。当然,如果实在太大了,那么只能考虑分库分表啦。

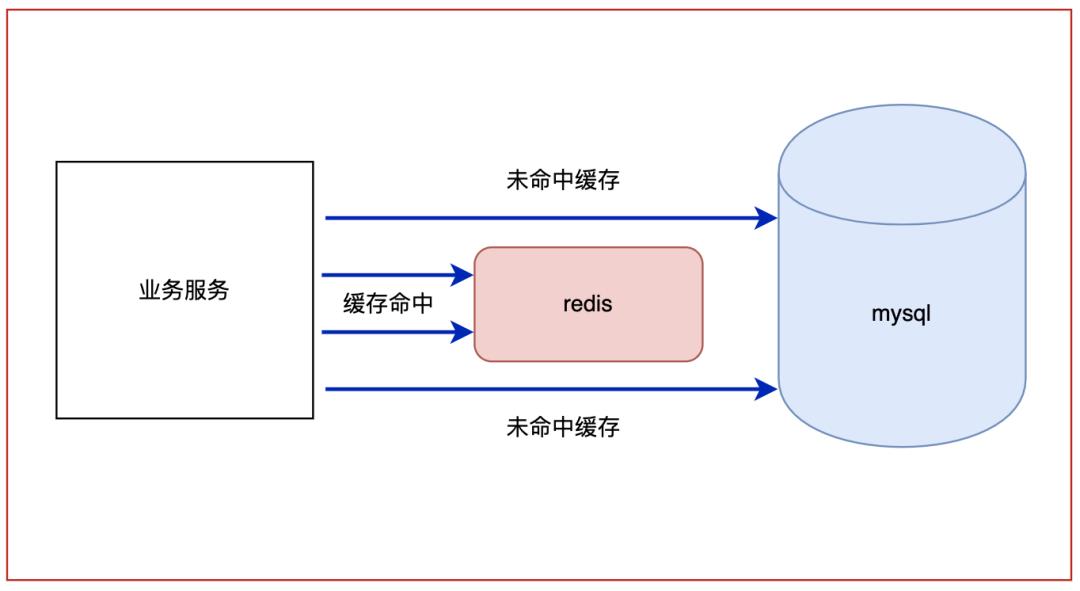

如果是写入压力太大呢?


写缓冲。一般而言可以增加消息队列来缓解。这样做有两个好处,一个是缓解数据库压力,第二个可以控制消费频率。

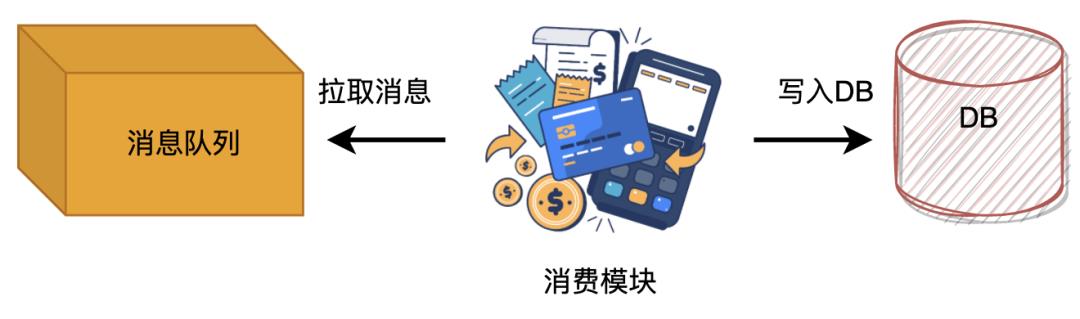



性能实战

如果发现线上Insert导致cpu很高,你会怎么解决?


1.查看是不是请求量突然飙升导致,如果是攻击,则增加对应的防护;


2.查看是否因为数据规模达到一个阈值,导致MySQL的处理能力发生了下降;


3.查看二级索引是否建立过多,这种情况需要去清理非必要索引。


为什么二级索引过多,会导致性能下降?


因为一个二级索引,就相当于一棵B+树。如果我们建了10个索引,这10个索引就相当于10次随机I/O,那粗略估算性能至少也会慢10倍。


分页操作为什么在offset过大的时候会很慢?


以offset 10000, limit 10为例。慢的原因有两点:第一,由于offset是其实就是先找到第几大的数字,因此没法使用树的结构来快速检索。只能使用底层链表顺序找10000个节点,时间复杂度O(n),

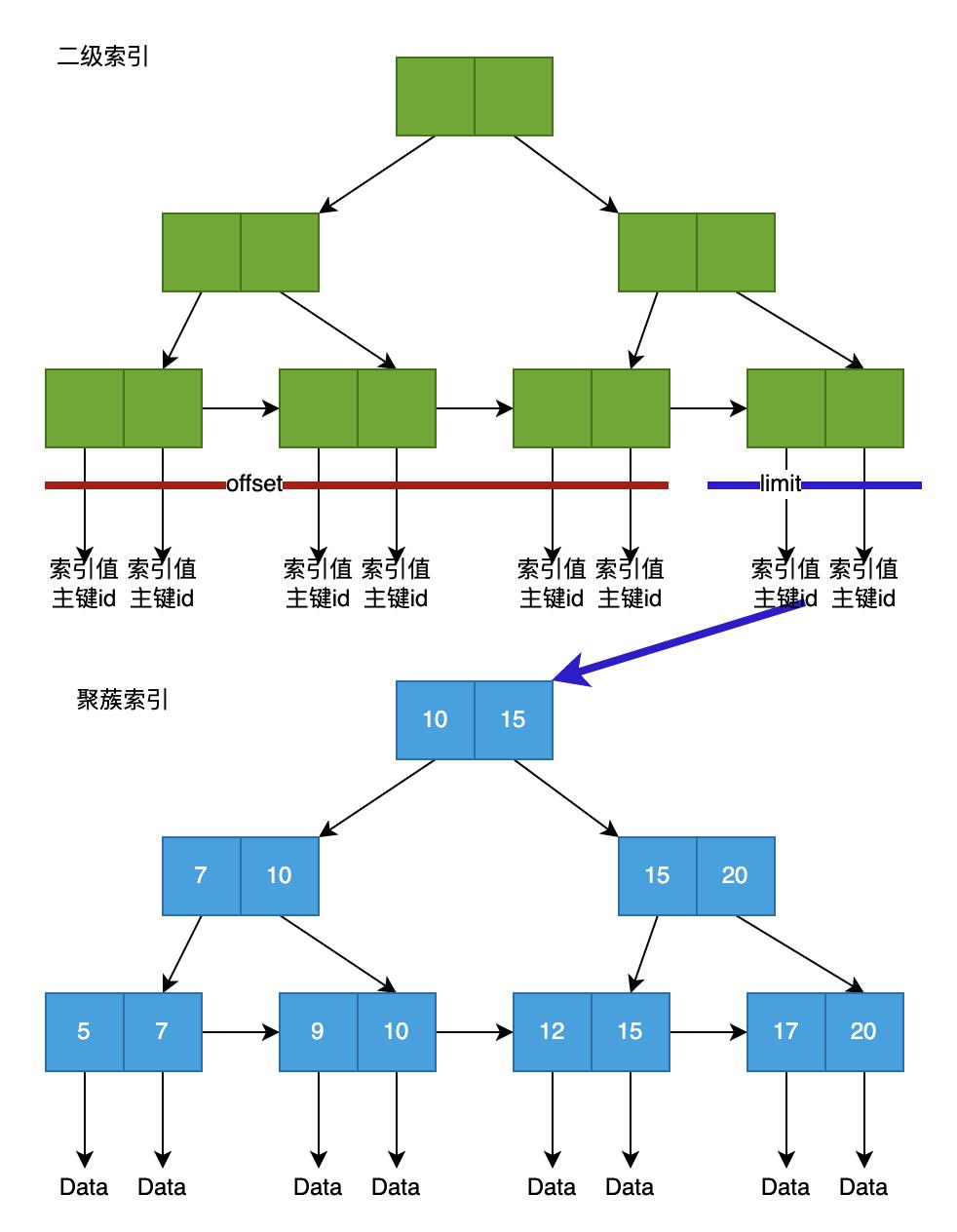

其次,即使这10000个节点是不需要的,MySQL也会通过二级索引上的主键id,去聚簇索引上查一遍数据,这可是10000次随机I/O,自然慢成哈士奇。这和它的优化器有关系,也算是MySQL的一个大坑,时至今日,也没有优化。


那我们怎么优化呢?


一般有两种优化方案:


方案一:绕过去。将分页替换为上一页、下一页。这样子就可以通过和上次返回数据进行比较,搭上树索引的便车。在ios,android端,上下页是很常见的。


方案二:正面刚。有一个概念叫索引覆盖,就是当辅助索引查询的数据只有主键id和辅助索引本身,那么就不必再去查聚簇索引。


如此一来,减少了offset时10000次随机I/O,只有limit出来的10个主键id会去查询聚簇索引,这样只会十次随机I/O,可以大幅提升性能,通常能满足业务要求。


那你说一下这两种方式的优缺点吧。


本质上来说,上下页方案属于产品设计优化。索引覆盖是技术方案优化。


上下页方案能利用树的分支结构实现快速过滤,还能直接通过主键索引查找,性能会高很多。但是它的使用场景受限,而且把主键ID暴露了。


索引覆盖方案维持了分页需求,适用场景更大,性能也提升了不少,但二级索引还是会走下层链表遍历。

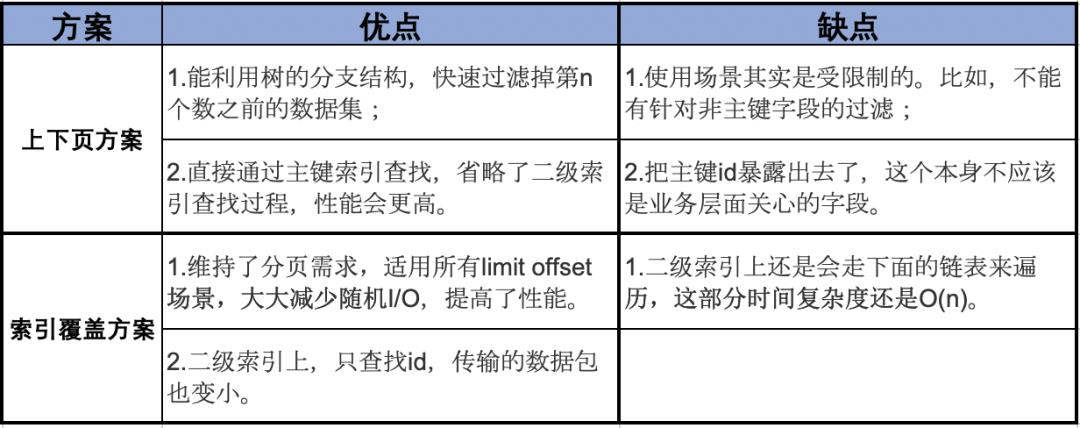

如果产品本身,可以接受上下页页面结构,且没用其它过滤条件,可以用方案一。方案二更具有普适性,同时由于合理分表的大小,一般也就500w,二级索引上O(n)的查找损耗,通常也在可接受范围。

针对分页性能问题,《高性能MySQL》中提到了这两个方案,感兴趣的小伙伴可以去看看。如果想成为高级工程师,那么不仅要知道怎么做,还需要对两者的优缺点进行对比,阐述选型思路。

Count操作的性能怎么优化?


有几种查询场景通用性优化方案。


第一种,是用Redis缓存来计数。每次服务启动,就将个数加载进Redis,当然,无论是Cache Aside还是Write Through,缓存和存储之间都会存在偏差,可以考虑用一个离线任务来矫正Redis中的个数。这种方案适用于对数据精确度,要求不是特别高的场景。

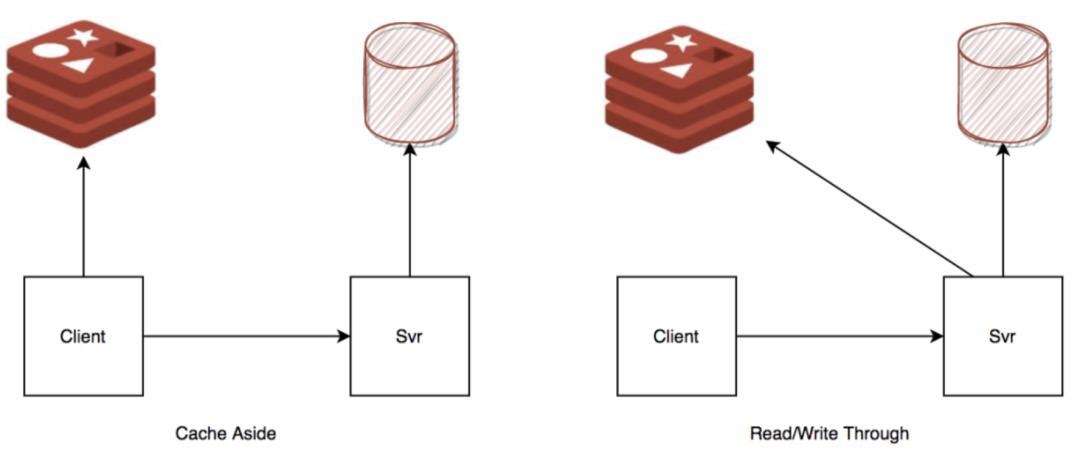

第二种,为count的筛选条件建立联合索引。这样可以实现索引覆盖,在二级索引表中就可以得到结果,不用再回表,回表可是O(n)次随机I/O呢。这种方案适用于有where条件的情况,并且与其它方案不冲突,可共同使用。


第三种,可以多维护一个计数表,通过事务的原子性,维持一个准确的计数。这种方案适用于对数据精度高,读多写少场景。

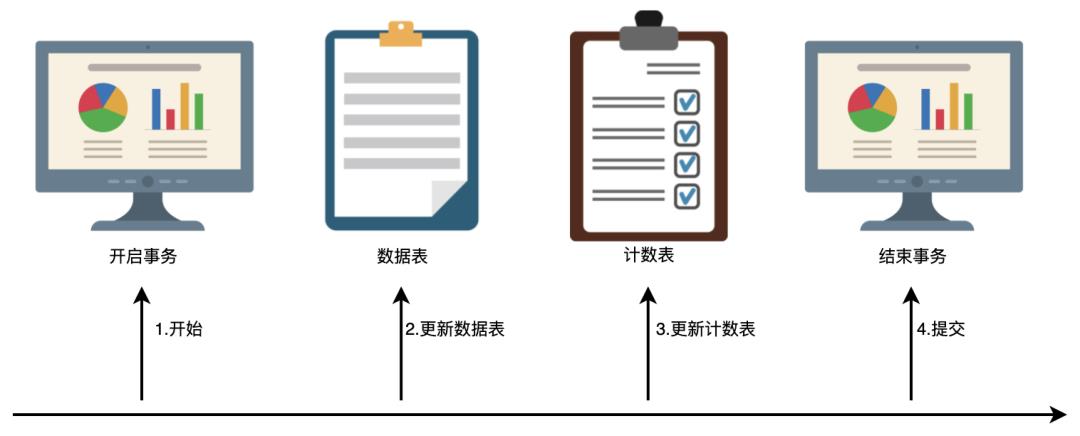

你对MySQL分表有了解吗?


随着业务持续扩张,单表性能一定会达到极限,分表是把一个数据库中的数据表拆分成多张表,通过分布式思路提供可扩展的性能。


那有哪些分表方式?


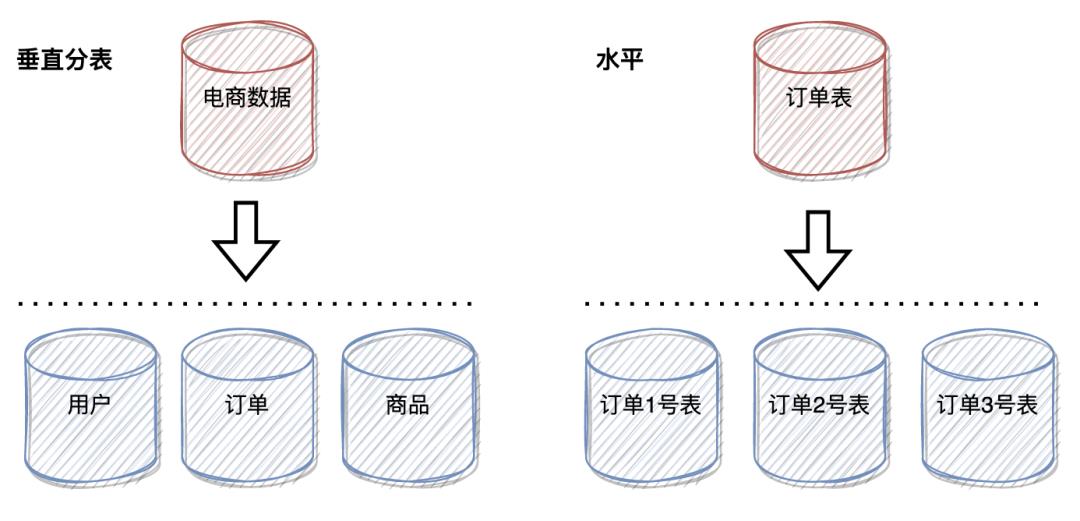
通常来说有水平分表、垂直分表两种划分方式。


垂直分表将一张表的数据,根据场景切分成多张表,本质是由于前期抽象不足,需要将业务数据进一步拆分。


水平分表则是将一张大表拆成多个结构相同的子表。直观来看表结构都是一样的,可以按某个字段来进行业务划分,也可以按照数据量来划分,划分的规则实际就是按某种维度,预判数据量进行拆分。


那你做过的项目中,分表逻辑怎么实现的?


分表逻辑一定是在一个公共的,可复用的位置来实现。我之前做的项目,是实现了一个本地依赖包,即将分表逻辑写在公共的代码库里,每个需要调用服务的客户方都集成该公共包,就接入了自动分表的能力。


优点在于简单,不引入新的组件,不增加运维难度。缺点是公共包更改后每个客户端都需要更新。

能说出优缺点,说明对方案还是比较清楚的。如果想更进一步加分,需要有竞争方案,比如分表是常规地通过中间件,还是放公共包。
小伙伴们日常多结合自己的项目思考,可以说是自己业务有特殊性,比如需要二维分表,很多中间件不支持,也可以说分表逻辑经过评估,是比较固定的,为此引入新的组件反而成本更大,自圆其说,才能凸显能力。
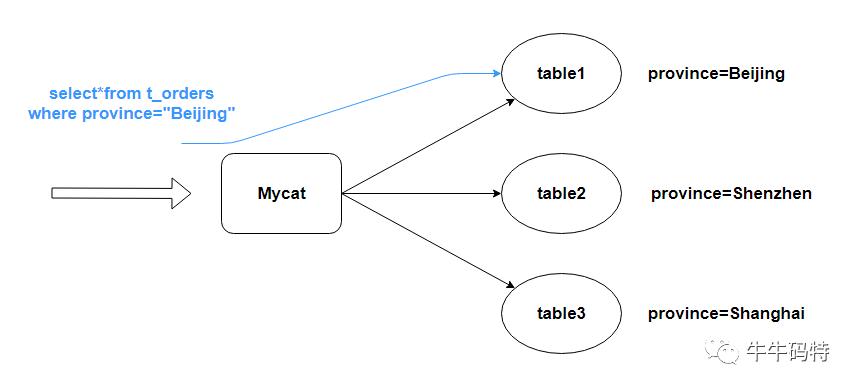
这里给大家推荐一个开源组件——Mycat,它是一个优秀的数据库中间件,其本质就是提供代理服务,对数据库进行访问,提供包括读写分离、分库分表等能力。
部署容易,耦合性低,感兴趣的朋友可以了解一下。

如果初期没做分表,已有3000W数据,此时要分库分表怎么做?


最复杂的情况,持续比较大的访问流量下,并且要求不停服。我们可以分几个阶段来操作:


1. 双写读老阶段:通过中间件,对write sql同时进行两次转发,也就是双写,保持新数据一致,同时开始历史数据拷贝。本阶段建议施行一周;

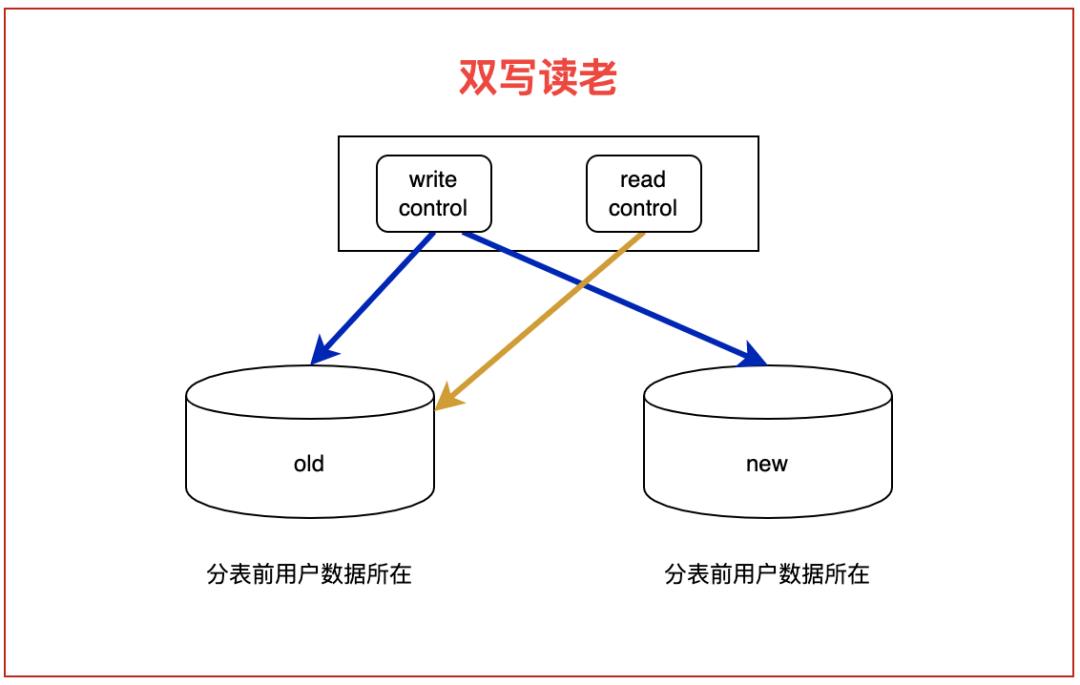

2. 双写双读阶段:采用灰度策略,一部分流量读老表,一部分流量读新表,读新表的部分在一开始,还可以同时多读一次老表数据,进行比对检查,观察无误后,随着时间慢慢切量到新表。本阶段建议施行至少两周;

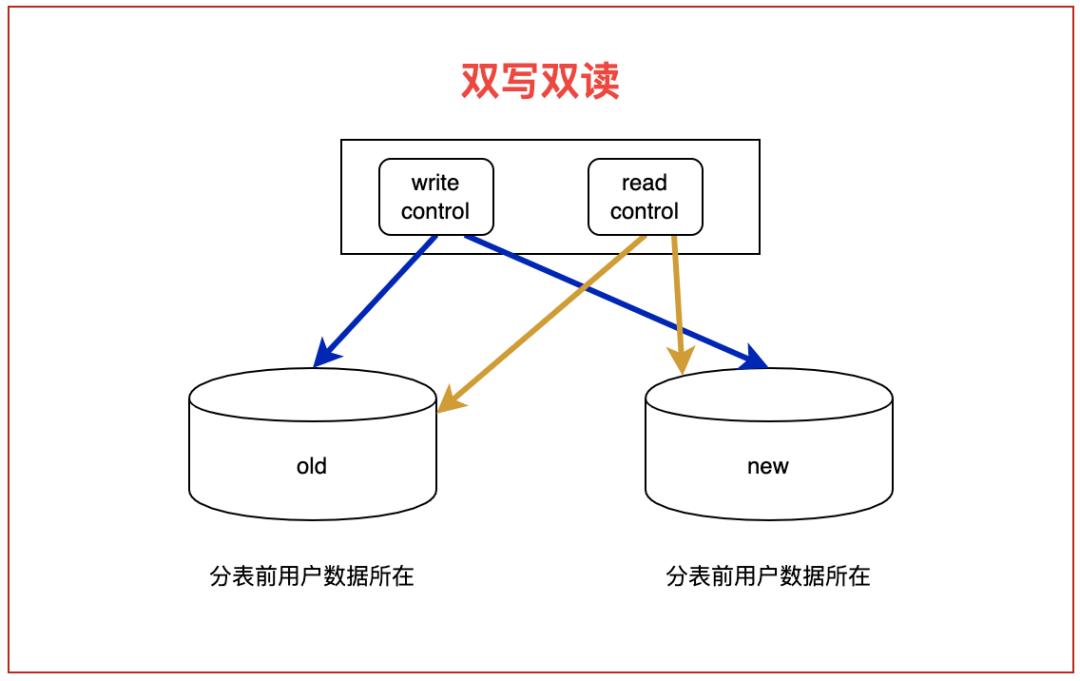

3. 双写读新阶段:此时基本已经稳定,可以只读新表,为了安全保证,建议还是多双写一段时间,防止有问题遗漏。本阶段建议周期一个月;

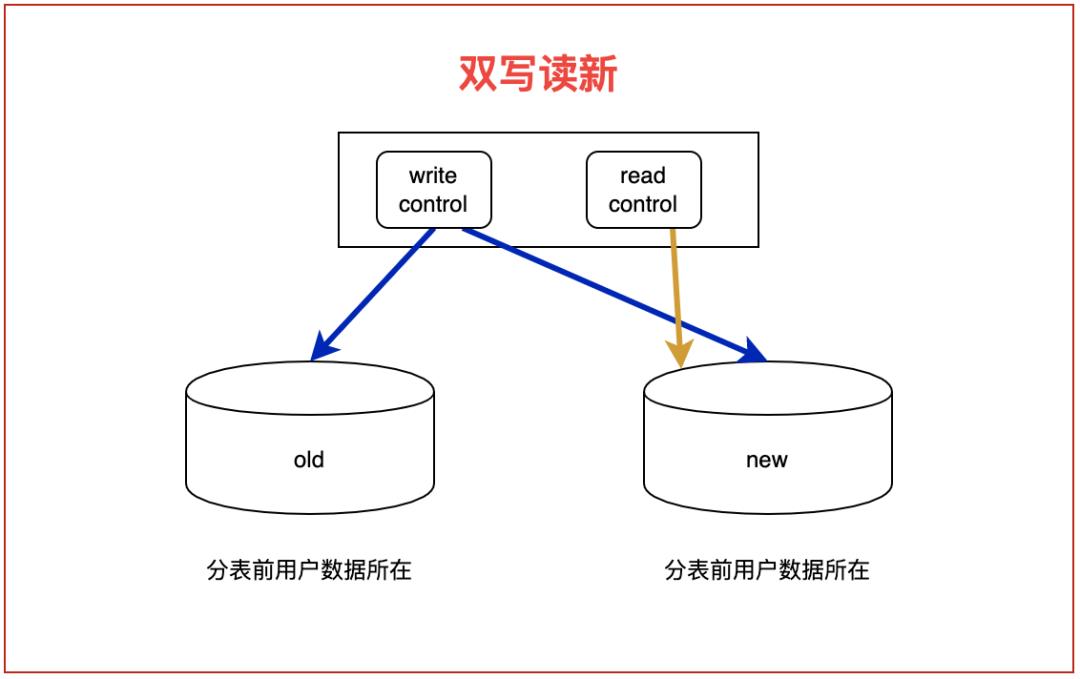

4. 写新读新阶段:此时已经完成了分表的迁移,老表数据可以做个冷备

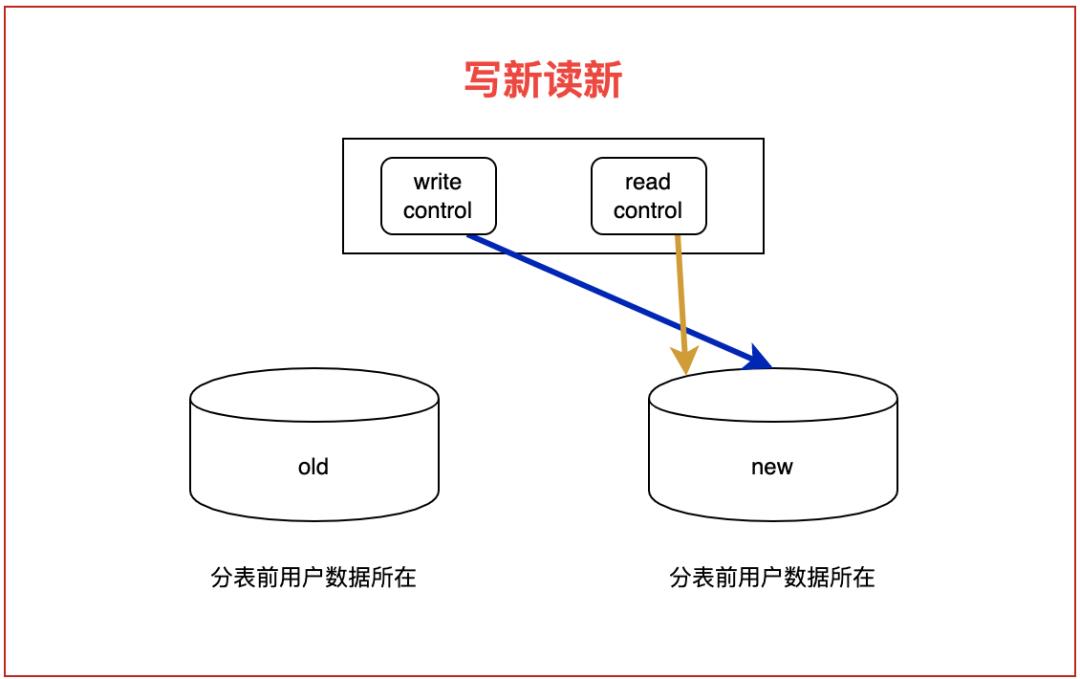
看着很简单的四个步骤,但在业务量已经比较庞大的情况下,操作也是非常复杂的。首先为了安全,每一阶段通常需要比较大的流转时间,也就是说可能已经跨越了多个开发版本。
其次是会带来短期性能损失——无论是双写,还是读检查,都做了额外的数据请求。在同样的请求量下,服务响应时间至少增大了一倍。



面试点评
MySQL的性能测试与调优,是MySQL常见但又高阶的内容,深入理解MySQL的性能与调优,才能良好的胜任相关开发与维护工作。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号

好文章,我在看❤️
以上是关于MySQL性能,杀疯了的主要内容,如果未能解决你的问题,请参考以下文章