图文详解 Spark 总体架构 [禅与计算机程序设计艺术]
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图文详解 Spark 总体架构 [禅与计算机程序设计艺术]相关的知识,希望对你有一定的参考价值。
前言
本文对Spark总体架构进行描述,本文读者需要一定的Spark的基础知识,至少了解Spark的RDD和DAG。
Spark 架构图
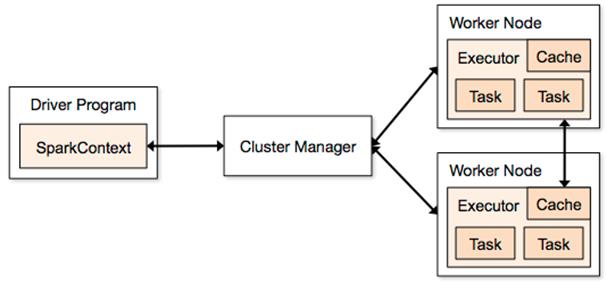
术语说明:
Driver
Driver的主要功能,总结如下:
- 运行应用程序的main函数
- 创建spark的上下文
- 划分RDD并生成有向无环图(DAGScheduler)
- 与spark中的其他组进行协调,协调资源等等(SchedulerBackend)
- 生成并发送 Task到 Executor(TaskScheduler)
官网上说:There are two deploy modes that can be used to launch Spark application on Yarn.In cluster mode,the Spark driver run inside an application master process.And in the client mode,the driver runs in the client process.
yarn-cluster模式下
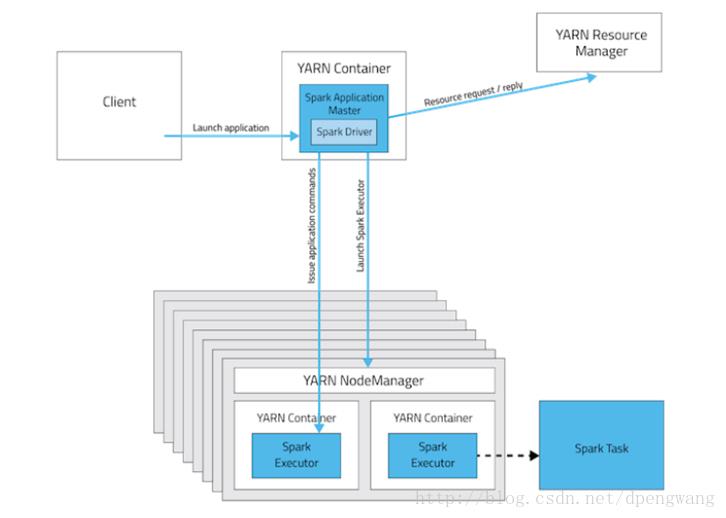
yarn-cluster模式下,client将用户程序提交到到spark集群中就与spark集群断开联系了,此时client将不会发挥其他任何作用,仅仅负责提交。在此模式下。AM和driver是同一个东西,但官网上给的是driver运行在AM里,可以理解为AM包括了driver的功能就像Driver运行在AM里一样,此时的AM既能够向AM申请资源并进行分配,又能完成driver划分RDD提交task等工作.
Executor
Executor是spark任务(task)的执行单元,运行在worker上,但是不等同于worker,实际上它是一组计算资源(cpu核心、memory)的集合。一个worker上的memory、cpu由多个executor共同分摊。
spark.executor.cores:顾名思义这个参数是用来指定executor的cpu内核个数,分配更多的内核意味着executor并发能力越强,能够同时执行更多的task.
spark.cores.max :为一个application分配的最大cpu核心数,如果没有设置这个值默认为spark.deploy.defaultCores
spark.executor.memory:指定每个executor的内存大小. 默认是 1G. 该配置项默认单位是MB,也可以显示指定单位 (如2g,8g). 如果运行过程中发现GC时间变红(管理界面可以看到),应该适当调大spark.executor.memory
指定 spark executor 数量的公式:
spark.executor.instances = spark.max.cores / spark.executor.cores集群的executor个数由spark.max.cores、spark.executor.cores共同决定. 其中,
spark.cores.max 是指你的spark程序需要的总核数,
spark.executor.cores 是指每个executor需要的核数.
Task
指定并行的task数量
spark.default.parallelism=1000参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。
通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!
Spark官网建议的设置原则是,设置该参数为 num-executors * executor-cores 的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
DAG 调度器
DAG: 有向无环图
1、用户提交的应用程序,Spark底层会根据宽依赖、窄依赖自动生成DAG。
2、反应出RDD之间的依赖关系
Executor:进程——运行在工作节点上,负责运行Task
Task:Executor的工作单元,也叫任务
Job:用户提交的作业,Job包含多个Task
Stage:是Job的基本调用单元,Job根据宽窄依赖划分不同的Stage,一个Stage中包含一个或者多个同种Task
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其它数据库中.
JVM堆空间下Spark的内存分配
任何Spark的进程都是一个JVM进程,既然是一个JVM进程,那么就可以配置它的堆大小(-Xmx和-Xms),但是进程怎么使用堆内存和为什么需要它呢?下面是一个JVM堆空间下Spark的内存分配情况

默认情况下,Spark进程的堆空间是512mb,为了安全考虑同时避免OOM,Spark只允许利用90%的堆空间,spark中使用spark.storage.safetyFraction用来配置该值(默认是0.9). Spark作为一个内存计算工具,Spark可以在内存中存储数据,如果读过http://0x0fff.com/spark-misconceptions/, 就会明白Spark不是一个真的内存工具,它只是把内存作为他的LRU缓存,这样大量的内存被用来缓存正在计算的数据,该部分占safe堆的60%,Spark使用spark.storage.memoryFraction控制该值,如果想知道Spark中能缓存了多少数据,可以统计所有Executor的堆大小,乘上safeFraction和memoryFraction,默认是54%,这就是Spark可用缓存数据使用的堆大小,
该部分介绍shuffle的内存使用情况,它通过 堆大小 * spark.shuffle.safetyFraction * spark.shuffle.memoryFraction。 spark.shuffle.safetyFraction的默认值是0.8, spark.shuffle.memoryFraction的默认值是0.2,所以最终只能最多使堆空间的16%用于shuffle,关于怎么使用这块内存,参考https://github.com/apache/spark/blob/branch-1.3/core/src/main/scala/org/apache/spark/shuffle/ShuffleMemoryManager.scala ,但是通常spark会使用这块内存用于shuffle中一些别的任务,当执行shuffle时,有时对数据进行排序,当进行排序时,需要缓冲排完序后的数据(注意不能改变LRU缓冲中的数据,因为后面可能要重用),这样就需要大量的RAM存储排完序后的数据块,当没有足够的内存用于排序,参考外排的实现,可以一块一块的排序,然后最终合并。
最后要讲到的一块内存是"unroll",该快内存用于unroll计算如下:spark.storage.unrollFraction * spark.storage.memoryFraction * spark.storage.safetyFraction 。当我们需要在内存展开数据块的时候使用,那么为什么需要展开呢?因为spark允许以序列化和非序列化两种方式存储数据,序列化后的数据无法直接使用,所以使用时必须要展开。该部分内存占用缓存的内存,所以如果需要内存用于展开数据时,如果这个时候内存不够,那么Spark LRU缓存中的数据会删除一些快。
YARN模式下的 JVM 堆内存
此时应该清楚知道spark怎么使用JVM中堆内存了,现在切换到集群模式,当你启动一个spark集群,如何看待它,下图是YARN模式下的

当运行在yarn集群上时,Yarn的 ResourceMananger 用来管理集群资源,集群上每个节点上的NodeManager用来管控所在节点的资源,从yarn的角度来看,每个节点看做可分配的资源池,当向ResourceManager请求资源时,它返回一些NodeManager信息,这些NodeManager将会提供execution container 给你,每个execution container就是满足请求的堆大小的JVM进程,JVM进程的位置是由ResourceMananger管理的,不能自己控制,如果一个节点有64GB的内存被yarn管理(通过yarn.nodemanager.resource.memory-mb配置),当请求10个4G内存的executors时,这些executors可能运行在同一个节点上。
当在yarn上启动spark集群上,可以指定:
executors的数量(-num-executors 或者 spark.executor.instances),
每个executor使用的内存(-executor-memory 或者 spark.executor.memory),
每个executor使用的cpu核数(-executor-cores 或者 spark.executor.cores),
每个task执行使用的core数( spark.task.cpus ),
driver应用使用的内存(-driver-memory 和 spark.driver.memory)当在集群上执行应用时,job会被切分成stages,每个stage切分成task,每个task单独调度,可以把executor的jvm进程看做task执行池,每个executor有
spark.executor.cores / spark.task.cpus execution个执行槽. 例子:集群有12个节点运行Yarn的NodeManager,每个节点有64G内存和32的cpu核,每个节点可以启动2个executor,每个executor的使用26G内存,剩下的内用系统和别的服务使用,每个executor有12个cpu核用于执行task,这样整个集群有
12 machines
* 2 executors per machine
* 12 cores per executor / 1 core = 288个task执行槽,这意味着spark集群可以同时跑288个task,整个集群用户缓存数据的内存有:
0.9 spark.storage.safetyFraction
* 0.6 spark.storage.memoryFraction
* 12 machines
* 2 executors per machine
* 26 GB per executor = 336.96 GB.到目前为止,我们已经了解了spark怎么使用JVM的内存以及集群上执行槽是什么,目前为止还没有谈到task的一些细节,这将在另一个文章中提高,基本上就是spark的一个工作单元,作为exector的jvm进程中的一个线程执行,这也是为什么spark的job启动时间快的原因,在jvm中启动一个线程比启动一个单独的jvm进程块(在hadoop中执行mapreduce应用会启动多个jvm进程)
Spark 抽象:partition
spark处理的所有数据都会切分成 partition,一个parition是什么以及怎么确定,partition的大小完全依赖数据源,spark中大部分用于读取数据的方法都可以指定生成的RDD中partition的个数,当从hdfs上读取一个文件时,会使用Hadoop的InputFormat来处理,默认情况下InputFormat返回每个InputSplit都会映射RDD中的一个Partition,大部分存储在HDFS上的文件每个数据块会生成一个InputSplit,每个数据块大小为64mb和128mb,因为HDFS上面的数据的块边界是按字节来算的(64mb一个块),但是当数据被处理是,它又要按记录进行切分,对于文本文件来说切分的字符就是换行符,对于sequence文件来说,他是块结束,如果是压缩文件,整个文件都被压缩了,它不能按行进行切分了,整个文件只有一个inputsplit,这样spark中也会只有一个parition,在处理的时候需要手动的repatition。
Hive on Spark调优 : 参数配置样例
set hive.execution.engine=spark;
set spark.executor.memory=4g;
set spark.executor.cores=2;
set spark.executor.instances=40;
set spark.serializer=org.apache.spark.serializer.KryoSerializer;之前在Hive on Spark 跑100g的数据量要跑十几个小时,一看CPU和内存的监控,发现POWER_TEST`阶段(依次执行30个查询)CPU只用了百分之十几,也就是没有把整个集群的性能利用起来,导致跑得很慢。因此,如何调整参数,使整个集群发挥最大性能显得尤为重要。
Spark作业运行原理
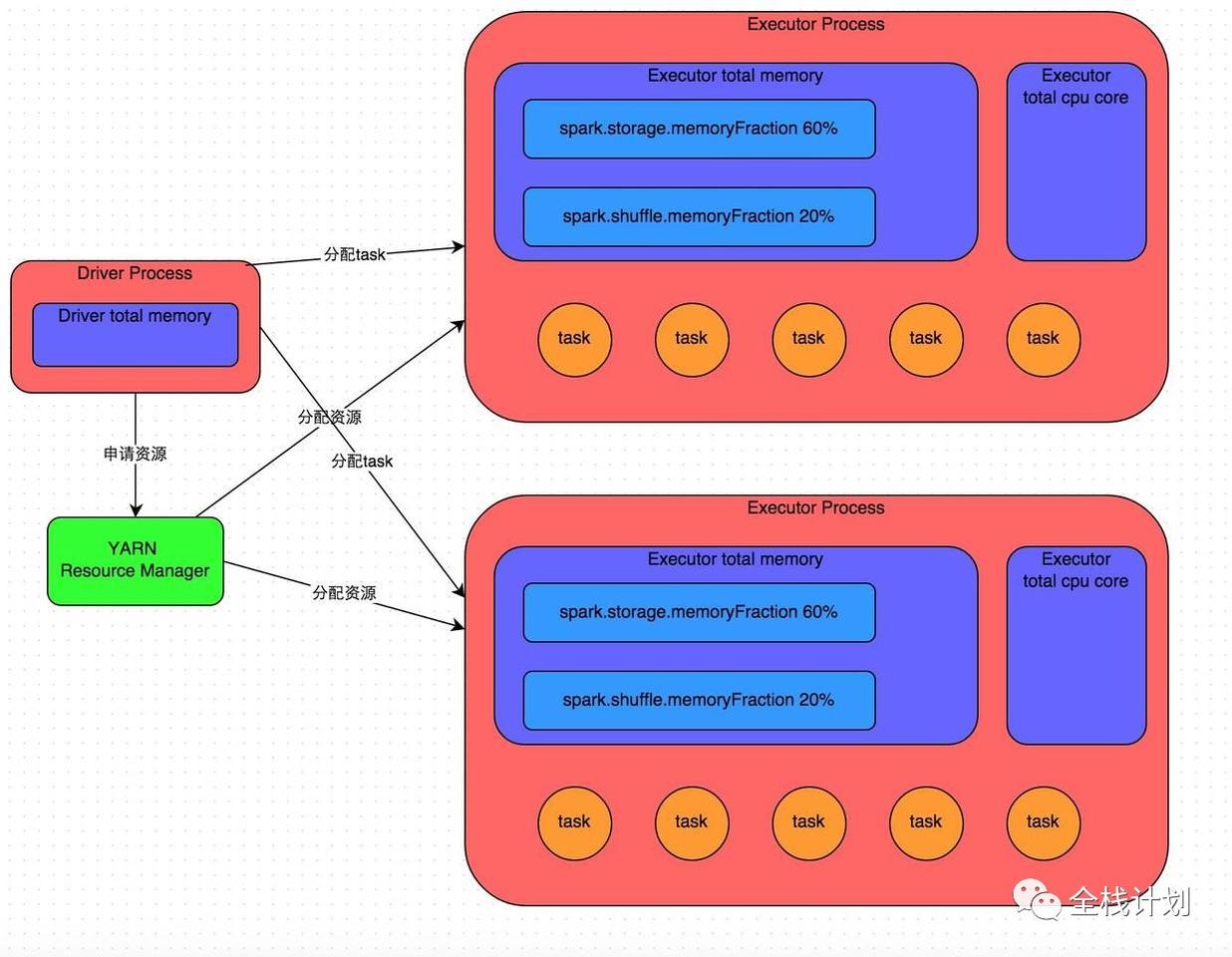
详细原理见上图。我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,美团•大众点评使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
以上就是Spark作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
参数调优
了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。以下参数就是Spark中主要的资源参数,每个参数都对应着作业运行原理中的某个部分。
num-executors/spark.executor.instances
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory/spark.executor.memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/31/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores/spark.executor.cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
- 参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
以上是关于图文详解 Spark 总体架构 [禅与计算机程序设计艺术]的主要内容,如果未能解决你的问题,请参考以下文章
啥是 SpringCloud 体系!图文详解,一起来看看吧!
对于maven创建spark项目的pom.xml配置文件(图文详解)
FineBI学习系列之FineBI与Spark数据连接(图文详解)