论文阅读CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding
Posted 桥本环奈粤港澳分奈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding相关的知识,希望对你有一定的参考价值。
目录

发表于EMNLP 2021
paper地址:https://aclanthology.org/2021.emnlp-main.685.pdf
代码地址:https://github.com/salesforce/CodeT5
一、简介
当前的方法要么依赖于仅编码器(或仅解码器)的预训练,这对于生成(或理解)任务来说是次优的,要么以与 NL 相同的方式处理代码片段,而忽略了 PL 的特性,例如 token 类型。论文提出的 CodeT5,是一个统一的预训练 encoder-decoder Transformer 模型,它可以更好地利用从开发人员分配的标识符传达的代码语义。模型采用统一的框架来无缝支持代码理解和生成任务,并允许多任务学习。此外,论文还提出了一种新的标识符感知预训练任务,使模型能够区分哪些代码 token 是标识符,并在它们被 mask 时恢复它们。
此外,论文还利用用户编写的代码注释和双峰双生成任务进行更好的 NL-PL 对齐。实验表明,CodeT5 在理解代码缺陷检测和克隆检测等任务以及包括 PL-NL、NL-PL 和 PL-PL 在内的各个方向的生成任务方面明显优于先前的方法。

二、预训练
a. Identifier-aware Denoising Pre-training
用了类似于T5的Masked Span目标,该目标随机掩蔽具有任意长度的Span,然后在解码器中结合一些sentinel tokens预测这些Masked Span。(图中的a. Masked Span Prediction (MSP))
b. Identifier Tagging (IT)
告知模型该代码token是否为标识符,与一些开发辅助工具中语法高亮显示的精神类似。
c. Masked Identifier Prediction (MIP)
与MSP中的随机span mask 不同,MIP屏蔽PL段中的所有标识符,并对所有出现的特定标识符使用唯一的标记 (obfuscation,混淆的思想,,即改变标识符名称不会影响代码语义)。然后将唯一标识符和sentinel tokens排列到目标序列I中再预测。
d. Bimodal Dual Generation
预训练阶段解码器只看到离散的masked spans和标识符,但在下游任务中解码器需要生成流畅的NL文本或语法正确的代码片段。为了缩小预训练和微调的差距,利用NL-PL双向数据训练模型的双向转换和优化模型,将NL→PL生成和PL→NL生成视为两项任务,对每对NL-PL双峰数据,构造两个方向相反的训练实例,并添加语言id、Bimodal Dual Generation可以视为一种特殊的span mask(屏蔽来自双峰输入的全部NL或PL段)。目的是提高NL和PL之间的一致性。
三、实验
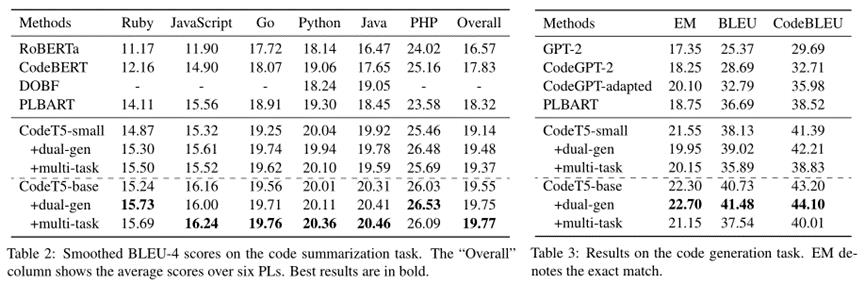


以上是关于论文阅读CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding的主要内容,如果未能解决你的问题,请参考以下文章