TensorFlow 对数据集标记的xml文件解析记录
Posted ʚVVcatɞ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow 对数据集标记的xml文件解析记录相关的知识,希望对你有一定的参考价值。
环境
- Windows:10
- Python 3.7.10
- TensorFlow:2.3
- matplotlib:3.3.4
- lxml:4.7.1
最近要用TensorFlow做20种水果识别,对刚入手的数据集,开始对数据集进行检验。
原图如下:

以下是通过精灵标注助手生成的xml 文件
<?xml version="1.0" ?>
<annotation>
<folder>菠萝</folder>
<filename>pineapple.jpg</filename>
<path>C:\\Users\\Desktop\\pineapple.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>730</width>
<height>413</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>菠萝</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>125</xmin>
<ymin>112</ymin>
<xmax>543</xmax>
<ymax>400</ymax>
</bndbox>
</object>
<object>
<name>菠萝</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>547</xmin>
<ymin>97</ymin>
<xmax>721</xmax>
<ymax>390</ymax>
</bndbox>
</object>
</annotation>
通过以下代码将xml中绘画的矩形框显示到图片中。
import tensorflow as tf
import matplotlib.pyplot as plt
from lxml import etree
from matplotlib.patches import Rectangle # 绘制矩形框
img = tf.io.read_file(r'./pineapple.jpg')
img = tf.image.decode_jpeg(img) # 对图像进行解码
print(img.shape)
plt.imshow(img)
plt.show()
xml = open(r'./pineapple.xml').read() # 读取 xml文件
sel = etree.html(xml) # 对 xml 文件进行解析
width = sel.xpath('//size/width/text()')[0] # 获取图片的宽
height = sel.xpath('//size/height/text()')[0] # 获取图片的高
bndbox = sel.xpath('//bndbox')
ax = plt.gca() # 获取当前图像
for i in range(0, len(bndbox)):
xmin = sel.xpath('//bndbox/xmin/text()')[i]
ymin = sel.xpath('//bndbox/ymin/text()')[i]
xmax = sel.xpath('//bndbox/xmax/text()')[i]
ymax = sel.xpath('//bndbox/ymax/text()')[i]
xmin = int(xmin)
ymin = int(ymin)
xmax = int(xmax)
ymax = int(ymax)
plt.imshow(img.numpy())
rect = Rectangle((xmin, ymin), (xmax - xmin), (ymax - ymin), fill=False, color='red') # fill=False 不需要填充
ax.axes.add_patch(rect) # 添加矩形框
plt.show()
还原出入手的数据集用精灵标注助手标记的效果如下:

由于发现数据集中有多边形和矩形框数据混合,所以通过以下代码区分开来
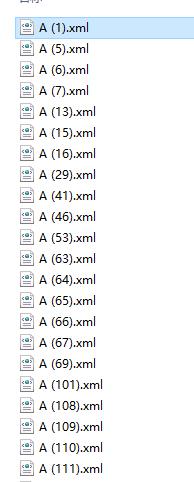
以上xml文件一个一个的点开查看比较麻烦,用以下代码进行处理查看:
import os
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
# xml文件路径
txt_path = 'C:\\\\Users\\\\vvcat\\\\Desktop\\\\xxx\\\\xxxxx\\\\outputs2\\\\'
for txt_file in os.listdir(txt_path):
txt_name = os.path.splitext(txt_file)[0] #获取文件名
txt_suffix = os.path.splitext(txt_file)[1] # 获取后缀
# print(txt_name, txt_suffix)
file_name_path = txt_path + txt_name + txt_suffix
root = ET.parse(file_name_path)
bndboxs = root.getiterator("bndbox")
if bndboxs == []:
print(txt_name + txt_suffix) # 打印包含多边形框的xml文件
效果如下:
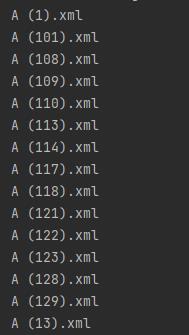
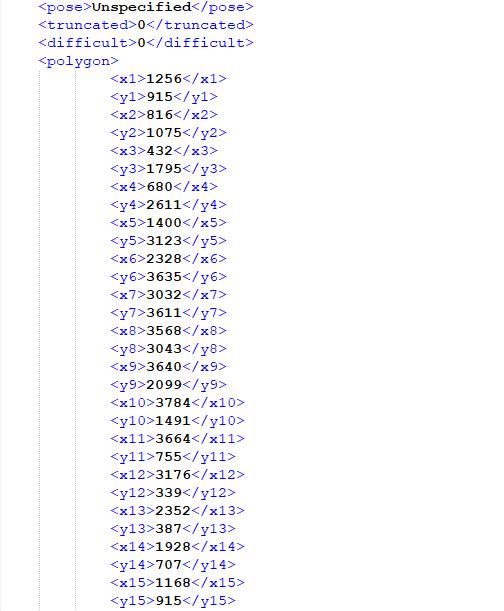
打开A(1).xml文件,内容如下:
以上是关于TensorFlow 对数据集标记的xml文件解析记录的主要内容,如果未能解决你的问题,请参考以下文章