Python 刷英语六级段落匹配仅需 3 秒?
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 刷英语六级段落匹配仅需 3 秒?相关的知识,希望对你有一定的参考价值。

作者 | 叶庭云
来源 | AI庭云君
一、前言
一年二度的四六级考试就此落下帷幕,本次考试体验感极强,反手就是一个 "五星好评"

本文利用 Python 的模糊匹配方法来刷英语六级段落匹配,仅需要3秒!Python的 FuzzyWuzzy 库,是一个易用而又强大的模糊字符串匹配工具包。它依据 Levenshtein Distance 算法,计算两个序列之间的差异。Levenshtein Distance算法,又叫 Edit Distance 算法,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。
后面的编程都是在 jupyter notebook 环境中,安装 FuzzyWuzzy 库如下所示:
pip install fuzzywuzzy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com二、fuzz模块
导入方法,直接导入这个模块的话,系统会提示UserWarning,这不代表报错,程序依旧可以运行(使用的默认算法,执行速度较慢),可以按照系统的提示安装 python-Levenshtein 库进行辅助,这有利于提高计算的速度。

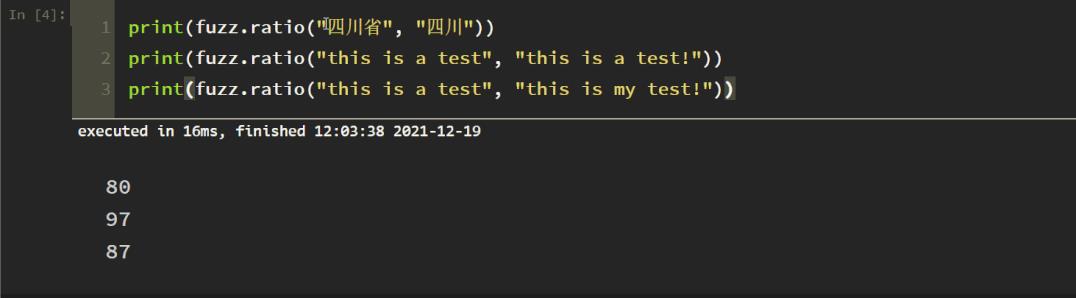
1. 简单匹配
这个其实不怎么精确,也不常用,测试如下:
2. 部分匹配(Partial Ratio)
尽量使用部分匹配,精度较高!测试如下:

可以发现,fuzz.partial_ratio(S1, S2)部分匹配,如果 S2 是 S1 的子串依然返回100
3. 忽略顺序匹配(Token Sort Ratio)
原理:以 空格 为分隔符,小写化所有字母,无视空格外的其它标点符号,测试如下:
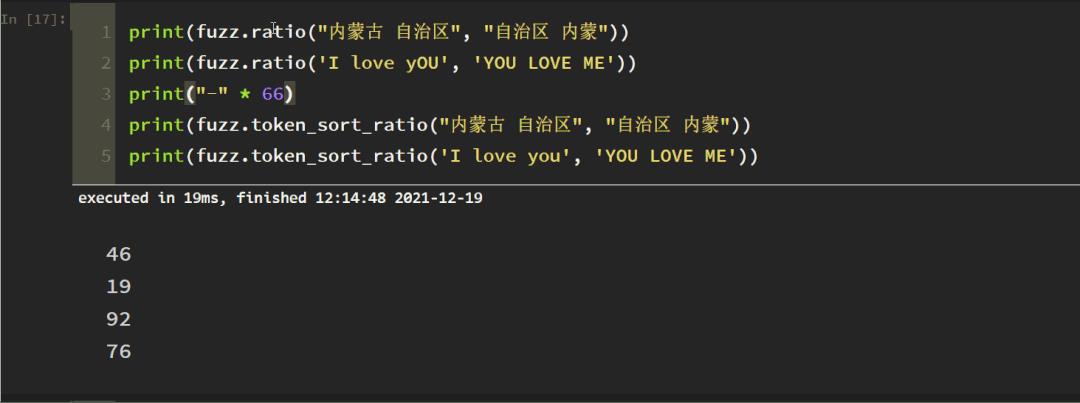
fuzz.token_sort_ratio(S1,S2)比较S1,S2单词是否相同,不考虑词语之间的顺序。
4. 去重子集匹配(Token Set Ratio)
相当于比对之前有一个集合去重的过程,注意最后两个,可理解为该方法是在 token_sort_ratio 方法的基础上添加了集合去重的功能,下面三个匹配的都是倒序。

fuzz的这几个 ratio 函数最后得到的结果都是匹配数值,如果需要获得匹配度最高的字符串结果,还需要依旧自己的数据类型选择不同的函数,然后再进行结果提取,如果但看文本数据的匹配程度使用这种方式是可以量化的,但是对于我们要提取匹配的结果来说就不是很方便了,因此就有了 process 模块。
三、process模块
用于处理备选答案有限的情况,返回模糊匹配的字符串和相似度。测试如下:

四、实践
实践当然就是利用 fuzz 模块来刷英语六级段落匹配,看看结果怎么样!!
知乎找到一个网址可以下载六级真题PDF:
https://pan.uvooc.com/Learn/CET/
它的 PDF 直接编辑不了,貌似是扫描的。这里我们用 Adobe Acrobat Pro DC 识别后,将阅读材料和要匹配的选项直接复制粘贴到 txt 里面。


顺便说一下:利用 Adobe Acrobat Pro DC 裁剪页面提取 PDF 里的矢量图保存下来,图像放大不会失真,你直接截图的话,放大肯定会失真的。
读取 txt 数据,组织成字典:
with open("Englishreading.txt", "r", encoding="utf-8") as f1:
con1 = f1.read().split("\\n")
dic1 =
for i in con1:
data = i.split(":")
dic1[data[0]] = data[1]
print(dic1)with open("match.txt", "r") as f2:
con2 = f2.read().split("\\n")
dic2 =
for i in con2:
data = i.split(":")
dic2[data[0]] = data[1]
print(dic2)先简单测试一个,比如一个是匹配F,如下所示:

test_str = "Marconi was central to our present-day understanding of communication."
# test_str = "As an adult, Marconi had an intuition that he had to be loyal to politicians in order to be influential."
big_lst = []
for k, v in dic1.items():
sentence = [x.strip(" ") for x in v.split(".")]
scores = []
for a in sentence:
score = fuzz.partial_ratio(a, test_str)
scores.append(score)
# print(scores, sum(scores), round(sum(scores) / len(scores), 2))
k_score = sum(scores) * 0.2 + sum(scores) / len(scores)
big_lst.append((k, scores, round(k_score, 2)))
results = sorted(big_lst, key=lambda x: x[2], reverse=True)
print(results)
print(results[0][0])
得到答案也是 F,我们的算法做对了!最后刷整个英语六级段落匹配(10个题),结果如下:
# -*- coding: UTF-8 -*-
"""
@Author :叶庭云
@公众号 :AI庭云君
@CSDN :https://yetingyun.blog.csdn.net/
"""
answers = []
for idx, ans in dic2.items():
big_lst = []
for k, v in dic1.items():
sentence = [x.strip(" ") for x in v.split(".")]
scores = []
for a in sentence:
# score = fuzz.token_sort_ratio(a, ans)
score = fuzz.partial_ratio(a, ans)
if score > 30:
scores.append(score)
scores.sort()
if len(scores) >= 2:
max_ = max(scores) + scores[-2]
else:
max_ = max(scores)
big_lst.append((k, max_, scores))
results = sorted(big_lst, key=lambda x: x[1], reverse=True)
print(results)
print("-" * 66)
answers.append(results[0][0])
print("answer:", answers)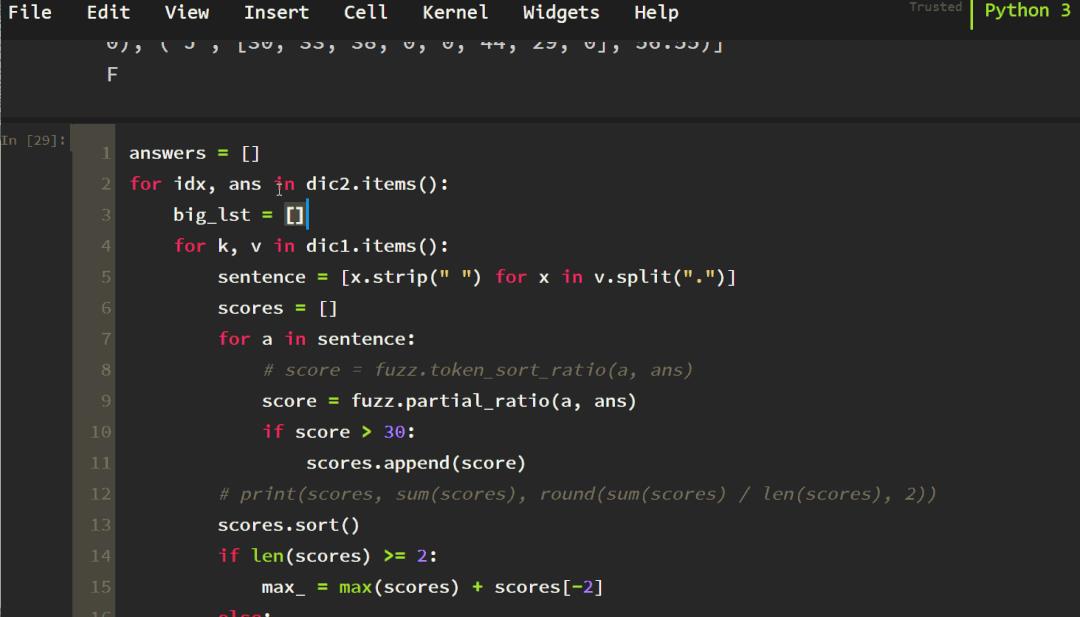

感兴趣的读者后面可以自行动手实践呀,看看能对多少个。


往
期
回
顾
资讯
技术
资讯
技术

分享

点收藏

点点赞

点在看
以上是关于Python 刷英语六级段落匹配仅需 3 秒?的主要内容,如果未能解决你的问题,请参考以下文章