几分钟让小孩的人物涂鸦「动起来」,Meta AI创建了一个奇妙的火柴人世界
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了几分钟让小孩的人物涂鸦「动起来」,Meta AI创建了一个奇妙的火柴人世界相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
Meta AI 让儿童手绘「活」了起来。
你有没有想过将一张儿童绘画制作成动画?就如下图,儿童能够绘制出独特和富有创造力的人物和动物:长着双脚的星星、腿超级长的鸟……

父母和老师可以很容易地理解孩子绘画想要表达什么,但 AI 很难完成这项任务,因为儿童绘画通常以抽象、奇特的方式构建,就以儿童绘画中的「人」来说,绘画中的「人」有许多不同的形式、颜色、大小和比例,在身体对称性、形态和视角方面几乎没有相似之处。对 AI 来说,识别儿童绘画还存在一定的困难。
目前,出现了许多 AI 工具和技术来处理逼真的绘图,但儿童绘画增加了一定程度的多样性和不可预测性,这使得识别所描绘的内容变得更加复杂。
许多 AI 研究人员正在试图克服这一挑战,以便 AI 系统能够更好地识别儿童创作的各种人物绘画。
近日,Meta 宣布首创了一种 AI 系统,该系统可以在没有任何人工指导的情况下,高成功率的自动为儿童手绘人物和类人角色(即有两条胳膊、两条腿、一个头等的角色)制作动画,几分钟就可以实现从一张静态图到动画的转变。
例如,儿童绘制的小猫咪和小蜜蜂,上传到 Meta AI,你就会看到绘画变成会跳舞的角色,动作非常逼真。
试玩地址:https://sketch.metademolab.com/
通过将绘画上传到 Meta 原型系统,用户就可以体验绘画变成会跳跃的角色。此外,用户还可以下载动画与朋友家人分享。如果用户愿意,他们也可以提交这些绘画以帮助改进 AI 模型。
Meta 通过四个步骤来完成从绘画到动画的转变:目标检测识别人形;使用角色 mask 从场景中提升人形;通过「rigging」为动画做准备;使用 3D 动作捕捉制作 3D 人形动画。

目标检测识别人形图
第一步是将绘画中的人物与背景以及绘画中的其他类型的角色区分开来。使用现有的目标检测方法在儿童绘画上识别效果较好,但分割掩码不够准确,无法用于动画。为了解决这个问题,Meta 改为使用从目标检测器获得的边界框(bounding boxes),并应用一系列形态学操作和图像处理步骤来获得掩码。
Meta AI 采用基于卷积神经网络的目标检测模型 Mask R-CNN 来提取儿童绘画中的人物。虽然 Mask R-CNN 是在最大的分割数据集上进行了预训练,但该数据集是由真实世界物体照片组成,而不是绘画。为了让模型能够处理绘图,需要对模型进行微调,Meta AI 使用 ResNet-50+FPN 进行了微调,以预测单个类别「人形图」。 Meta AI 在大约 1,000 幅绘画上微调了模型。
微调后,模型很好地检测到了测试数据集中的人形图。但是也有失败的案例,如下图可分为四类:检测到的人形图没有包含整个图像(例如图中尾巴没有包含);没有把人形图和背景分开;没有把几个凑在一起的人形图分开;错误地识别非人类人物(例如树)。

使用角色 mask 从场景中提升人形
从画作中识别和提取人物后,生成动画的下一步是将其与场景的其他部分和背景分离,该过程被称为 masking。mask 必须准确映射人物的轮廓,因为它将被用于创建网格,然后变形以生成动画。一切妥当后,mask 将包含角色的所有组件,而消除任何背景内容。
尽管 Mask R-CNN 可以输出 mask,但 Meta AI 发现它们并不适合动画。当身体部位的外观变化很大时,预测的 mask 通常无法捕捉到整个人物。如下图下行图例所示,一个大的黄色三角形代表身体,一个铅笔笔画代表手臂,使用 Mask R-CNN 预测 mask 时,通常会漏掉连接双手的铅笔笔画部分。
基于此,Meta AI 开发了一种基于经典图像处理的方法,该方法对人物变化具有更强的稳健性。基于这种方法,Meta AI 使用预测到的人形边界框来裁剪图像。然后,使用自适应阈值和形态学 closing/dialating 操作,从边界框边缘填充,并假设 mask 是未被填充的最大多边形。

Mask R-CNN 与基于经典图像处理方法的效果比较。
然而,这种方法虽然对于提取适合动画的准确 mask 来说简单有效,但当背景杂乱、人物靠得太近或者纸张页面上有褶皱撕裂或阴影时,也有可能会失败。
通过「rigging」为动画做准备
儿童会画出千奇百怪的身体形状,远远超出了具有完整头部、手臂、腿和躯干的传统人形概念。一些儿童画出来的火柴人没有躯干,只有手臂和腿直接与头部相连。另一些儿童画下的人形更诡异,腿从头部延伸出来,手臂从大腿眼神出来。
因此,Meta AI 需要找到一种能够出来身形变化的 rigging 方法。

他们选择使用了人体姿态检测模型 AlphaPose,用来识别人画中作为臀部、肩膀、肘部、膝盖、手腕和脚踝的关键点。该模型是在真人图像上训练的,因此在将它调整以检测儿童画作中人形姿势之前,Meta AI 必须重新训练以处理儿童画作中存在的变化(variation)类型。
具体地,Meta AI 通过内部收集和注释儿童人形画面的小数据集实现了上述目标。然后,使用这些初始数据集上训练的姿态检测器创建了一个内部工具,使得父母可以上传并对他们孩子的画作进行动画处理。随着更多数据的加入,Meta AI 迭代地对模型进行再训练,直到达到较高的准确度。
使用 3D 动作捕捉制作 3D 人形动画
有了蒙版和联合预测,就有了制作动画所需要的一切。Meta AI 首先使用提取的蒙版生成网格,并使用原始画作进行纹理化处理。利用预测到的关节位置,他们为角色创建骨骼。之后,通过旋转骨骼并使用新的关节位置使网格变形,将角色移植到各种姿态中。通过将角色移植到一系列连续的姿态中,然后就可以创建动画了。
儿童作画时很常见的一种情况是从他们最容易辨认的角度来画身体部位,比如倾向于从侧面画腿和脚,从正面画头部和躯干。Meta AI 在动作重定位步骤中利用到了这一现象。对于下半身和生半身,他们会自动确定是从正面还是侧面来对动作进行识别。
具体地,他们将动作映射到单个 2D 平面并使用它来驱动角色,并使用 Mechanical Turk 运行的感知用户研究来对这种动作重定位的结果进行验证。分段检测流程如下图所示:
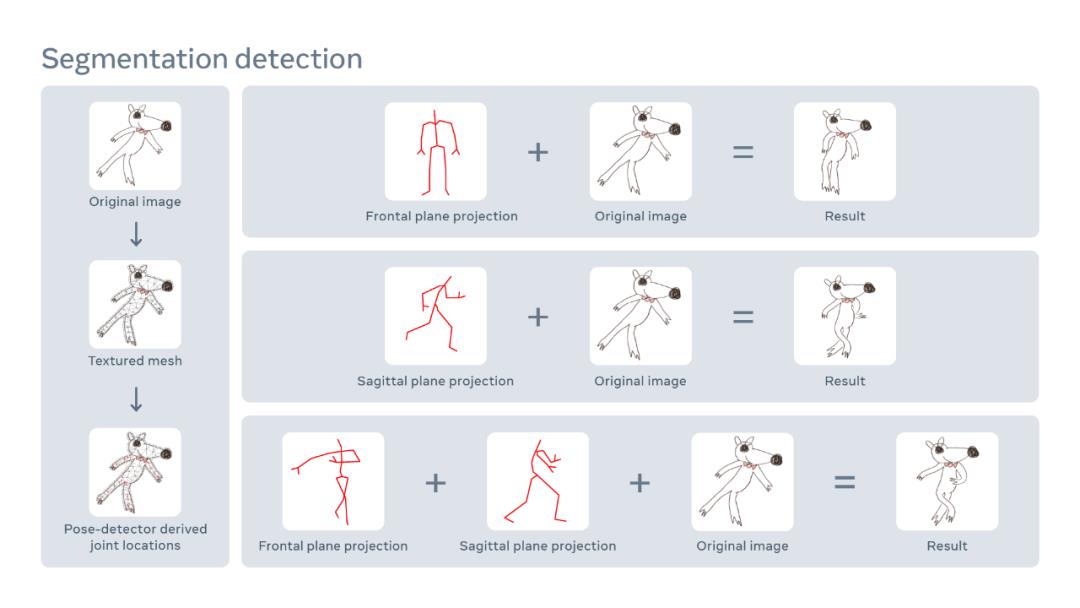
Meta AI 表示,将扭曲视角考虑在内是有帮助的,因为很多类型的动作并不会完成落在单个投影平面上。比如跳绳时,手臂和手腕主要在额平面内运动,弯曲的腿则倾向于在矢状平面内运动。因此,Meta AI 并没有为动作捕捉姿态确定单个动作平台,而是分别确定上半身和下半身的投影平面。
与此同时,有了 AR 眼睛,画作中的故事可以在现实世界中栩栩如生,画中的角色更可以与画出它的儿童一起跳舞或说话。
原文链接:https://ai.facebook.com/blog/using-ai-to-bring-childrens-drawings-to-life/
© THE END
投稿或寻求报道微信:MaiweiE_com
更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!
GitHub中文开源项目《计算机视觉实战演练:算法与应用》,“免费”“全面“”前沿”,以实战为主,编写详细的文档、可在线运行的notebook和源代码。
项目地址 https://github.com/Charmve/computer-vision-in-action
项目主页 https://charmve.github.io/L0CV-web/
推荐阅读
(更多“抠图”最新成果)
迈微AI研习社
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve

如果觉得有用,就请点赞、转发吧!
以上是关于几分钟让小孩的人物涂鸦「动起来」,Meta AI创建了一个奇妙的火柴人世界的主要内容,如果未能解决你的问题,请参考以下文章
使用关键点检测打造小工具Padoodle,让涂鸦小人跟随真人学跳舞