模型魔改---基于SETR模型的边缘检测
Posted 鼠标滑轮不会动
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型魔改---基于SETR模型的边缘检测相关的知识,希望对你有一定的参考价值。
系列文章目录
- 跑通代码—CVPR2020–StegaStamp: Invisible Hyperlinks in Physical Photographs
- 跑通代码—WACV2020-Dense Extreme Inception Network: Towards a Robust CNN Model for Edge Detection
- 跑通代码-ICCV2021-HiNet: Deep Image Hiding by Invertible Network
前言
跑通代码是第一步,接下来的工作是做个合格的 ”模型小裁缝“,将现有的优秀网络通过缝缝补补的操作应用到新的任务上。今天准备使用2021年CVPR论文(Zheng S, Lu J, Zhao H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 6881-6890.)中的Transformers模型,实验中没有对模型进行任何的修改,直接迁移到边缘提取的任务上,原始论文使用的24层,本次实验使用了1层和16层两种参数。论文提供多种Decode的方式,实验选择的是Naive upsampling,下图1中的b,将特征还原到原始图像的尺寸。SETR主要为多层ViT的堆叠,然后设计了几种Decode的结构,很多blog多说论文的创新性不够,我个人觉得,论文的题目就是Rethinking……说明是一篇探索性的论文,而不是精度提升的论文,宗旨是告诉我们ViT在实例分割、图像分类上能work,并且存在很大的优势,至于提升到SOTA是后面的工作。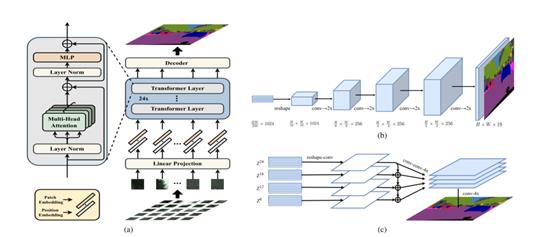
使用的训练构架为2020年CVPR论文(Poma, X. S., Riba, E., & Sappa, A. (2020). Dense extreme inception network: Towards a robust cnn model for edge detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 1923-1932).)原始代码的跑通结果可以参考博客跑通代码—WACV2020-Dense Extreme Inception Network: Towards a Robust CNN Model for Edge Detection
一、实验的具体细节
1.1 SETR代码的选择
由于SETR的官方代码是基于 MMsegmentation实现的,很难快速上手,所以选择了较为简单的开源代码实现项目920232796/SETR-pytorch
from SETR.transformer_seg import SETRModel
import torch
if __name__ == "__main__":
net = SETRModel(patch_size=(32, 32),
in_channels=3,
out_channels=1,
hidden_size=1024,
num_hidden_layers=8,
num_attention_heads=16,
decode_features=[512, 256, 128, 64])
t1 = torch.rand(1, 3, 256, 256)
print("input: " + str(t1.shape))
# print(net)
print("output: " + str(net(t1).shape))
给出的代码能很好的实现输入与输出图像尺寸的不变,相当于整个SETR的块代码都写好了,只需要设置相应的参数即可直接使用。将Dense Extreme Inception Network中的模型部分整个替换掉,换成上面的SETR模型。其他的参数可以保持不变,依然是Dense Extreme Inception Network的训练设置。
1.2 “剪裁”的细节
首先需要注意的是,Dense Extreme Inception Network中的模型输出具有多尺度融合的设置,所以对应的Loss位置,设置不同尺度损失函数的权重,由于SETR改之后,没有多尺度的输出,所以Loss权重地方需要修改为无权重,并且Loss加和取平均的地方也需要修改为单层输出的Loss。对应main.py中修改的位置在第42行上下。
原始Loss代码
loss = sum([criterion(preds, labels, l_w)/args.batch_size for preds, l_w in zip(preds_list,l_weight)])
修改之后的
loss = criterion(preds_list, labels, l_weight[0])/args.batch_size
接着是模型的部分,只需要将原始的模型替换成SETR的模型,其他的都不需要修改。由于没有预训练的参数,所以不需要导入参数,从头开始训练。
原始的代码
# Instantiate model and move it to the computing device
model = DexiNedVit().to(device)
修改之后的
model = SETRModel(patch_size=(32, 32),
in_channels=3,
out_channels=1,
hidden_size=1024,
sample_rate=5,
num_hidden_layers=1,
num_attention_heads=16,
decode_features=[512, 256, 128, 64, 32]).to(device)
二、训练结果
2.1 单层SETR边缘检测结果


上述训练使用BIPED数据集进行训练,batchsize是16,上图为训练8156个epoch的结果,Loss在0.023左右。每三列是一组,第一列是原始图像,第二列是边缘的真值(groundtruth),第三列为模型提取的边缘。从图中的结果可以看出,边缘的提取结果能看出来是图像的边缘,简单一点的纹理还可以提取出来,但是对于较为丰富的纹理提取的效果不是很好,主要有几个原因。第一、使用单层的SETR对纹理细节的表征能力还不够,参数欠缺,无法表达更加丰富的纹理特征。第二、没有多尺度的融合,相当于只做了一个回归任务,强行套用了SETR的模型。第三、没有使用SETR的预备训练参数,整个模型是从头开始训练的,没有预训练的参数,模型很难达到好的效果。
2.2 多层SETR边缘检测结果
多层SETR模型使用了16层(图1(a)中的块重复16次),训练过程中的输出结果下图。


由上图可以看出,增加SETR的层数能在一定程度上提升效果,只训练4000个epoch的结果已经与单层8000多个epoch的差不多。没有多尺度的融合,效果应该也无法超越现有的最好结果。
总结
结合两篇顶会论文的相关模型结构,使用Transformer实验了边缘提取的相关模型,相比目前性能最好的边缘提取模型,实验的结果还差很远,魔改第一步完成,接下来就是分析魔改效果不好的原因,怎么进一步提升。
以上是关于模型魔改---基于SETR模型的边缘检测的主要内容,如果未能解决你的问题,请参考以下文章