快速入门Java爬虫全文搜索引擎Elasticsearch,分析实战项目:仿京东搜索
Posted Ithasd琪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速入门Java爬虫全文搜索引擎Elasticsearch,分析实战项目:仿京东搜索相关的知识,希望对你有一定的参考价值。
hi,大家好,今天我给大家分析一下java爬虫和全文搜索引擎Elasticsearch,我的思路是首先分析用爬虫技术获取京东商场的数据,再将获取的数据放入Elaticsearch中,再体验一下全文搜索引擎的魅力(好比使用百度时,为什么我们只需要输入几个字,就能给我们有关这几个字所有的内容)。
这一篇文章我们先分析一下java爬虫技术:
在使用爬虫技术之前我们需要了解什么是爬虫,爬虫技术说白了点就是拿别人发布再网上的数据,可以是淘宝京东商品,可以是一些文章,再说简单点你去网上复制一篇心得,只不过这一系列操作不用人去做,我们交给代码实现。
今天我分析的内容是爬京东商品,我会获取商品的名称,图片,标签和店名。
(我在网上搜了下,其实使用爬虫获取网上的一些资源使用,在不涉及商业的情况下算合理,但是如果被爬虫方有意见我也会及时修改,我的目的只是记录我的学习知识和分析给那些需要帮助的人)
好的开始进入主题:!!!
(这里需要大家有一点web的知识,如springboot,如果没有那么要有点maven的知识吧,不然都不知道依赖是什么)
第一步我们可以新建一个springboot的项目,这里就用springboot项目来做例子,在pom.xml文件中导入相关的依赖。
首先这是爬虫的依赖为了我们能获取数据
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>这是一个实体类依赖,可以让我省区写get set
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>这是后面我们要的Elasticsearch的依赖,可以先加上
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>第一步我们先写上实体类,我们需要的获取名称、标题、图片、店名:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class goodJD
private String img;
private String title;
private String price;
private String shopnum;
使用lombok就不需要一个个写get和set方法了。
接着我们只需要在使用爬虫就行,我们在test中测试!
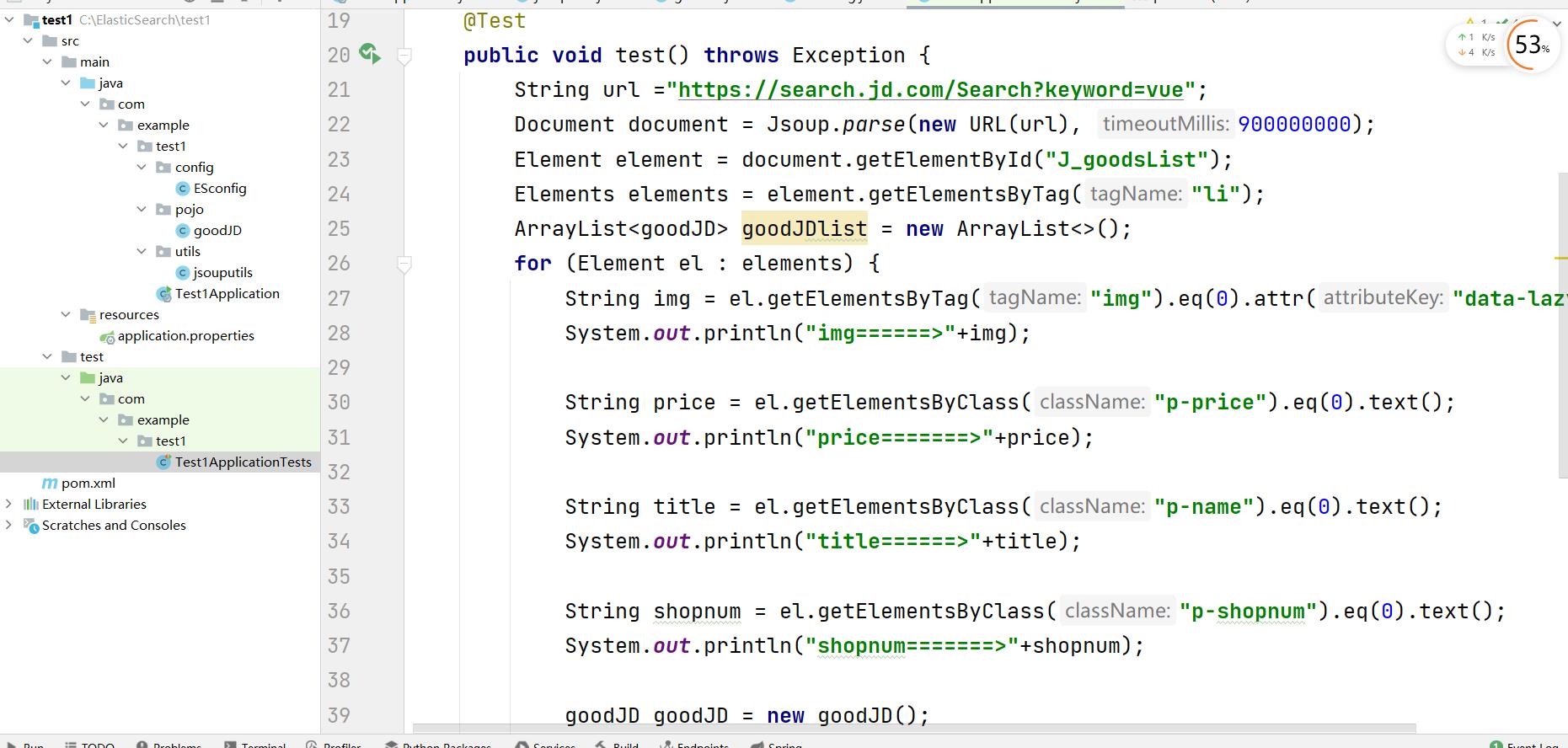
package com.example.test1; import com.example.test1.pojo.goodJD; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; import java.net.URL; import java.util.ArrayList; @SpringBootTest class Test1ApplicationTests @Test public void test() throws Exception String url ="https://search.jd.com/Search?keyword=java"; Document document = Jsoup.parse(new URL(url), 900000000); Element element = document.getElementById("J_goodsList"); Elements elements = element.getElementsByTag("li"); ArrayList<goodJD> goodJDlist = new ArrayList<>(); for (Element el : elements) String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img"); System.out.println("img======>"+img); String price = el.getElementsByClass("p-price").eq(0).text(); System.out.println("price=======>"+price); String title = el.getElementsByClass("p-name").eq(0).text(); System.out.println("title======>"+title); String shopnum = el.getElementsByClass("p-shopnum").eq(0).text(); System.out.println("shopnum=======>"+shopnum); goodJD goodJD = new goodJD(); goodJD.setTitle(title); goodJD.setImg(img); goodJD.setPrice(price); goodJD.setShopnum(shopnum); goodJDlist.add(goodJD);
代码就只有这么多,我们一步步分析下代码
第一步是写上你需要爬虫的网址,这里是京东官网,keyword关键字是java,
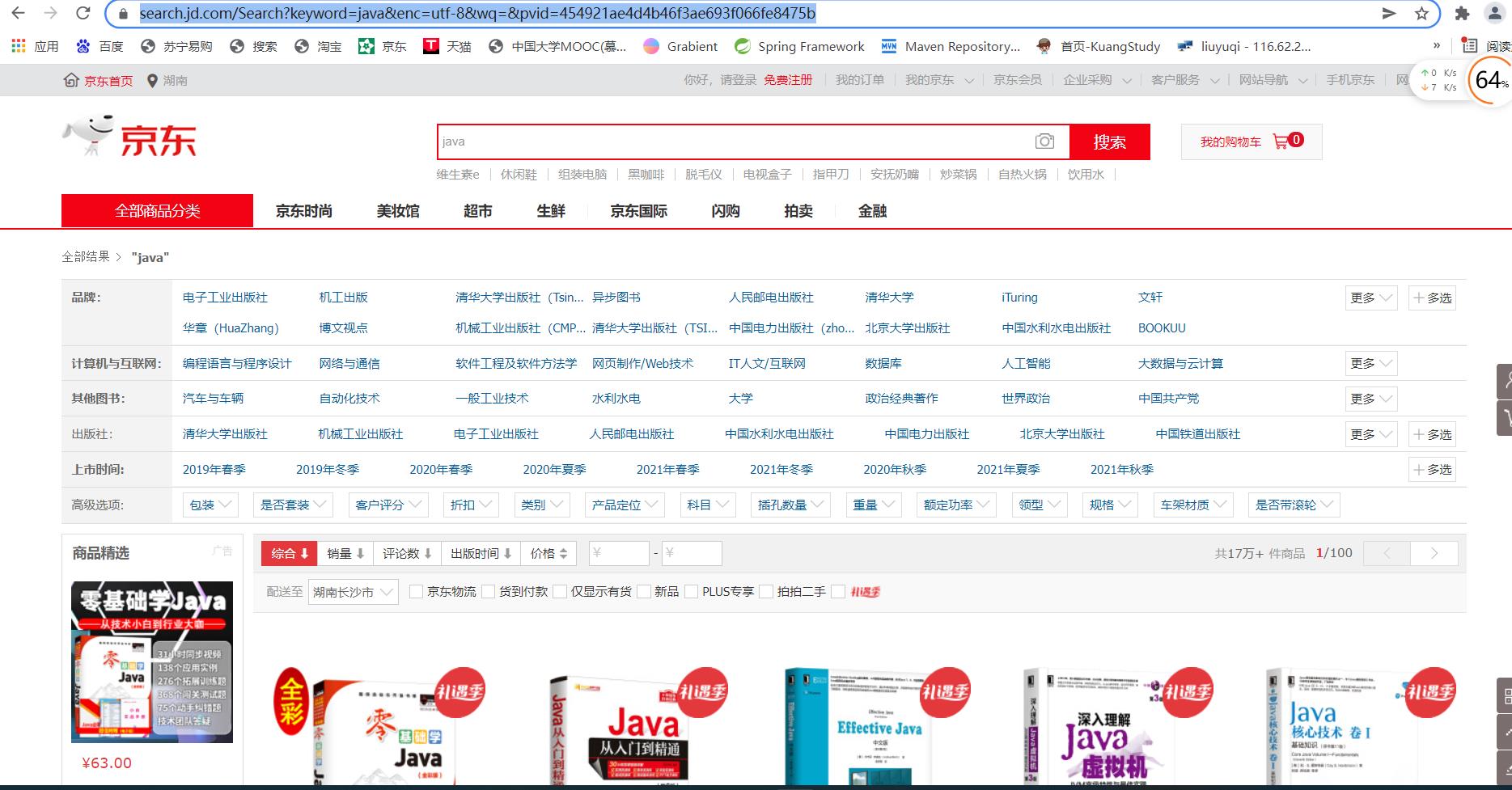
接着我们使用爬虫类进入网站中,随后需要获取你想要的数据,我们可以用F12打开京东商场
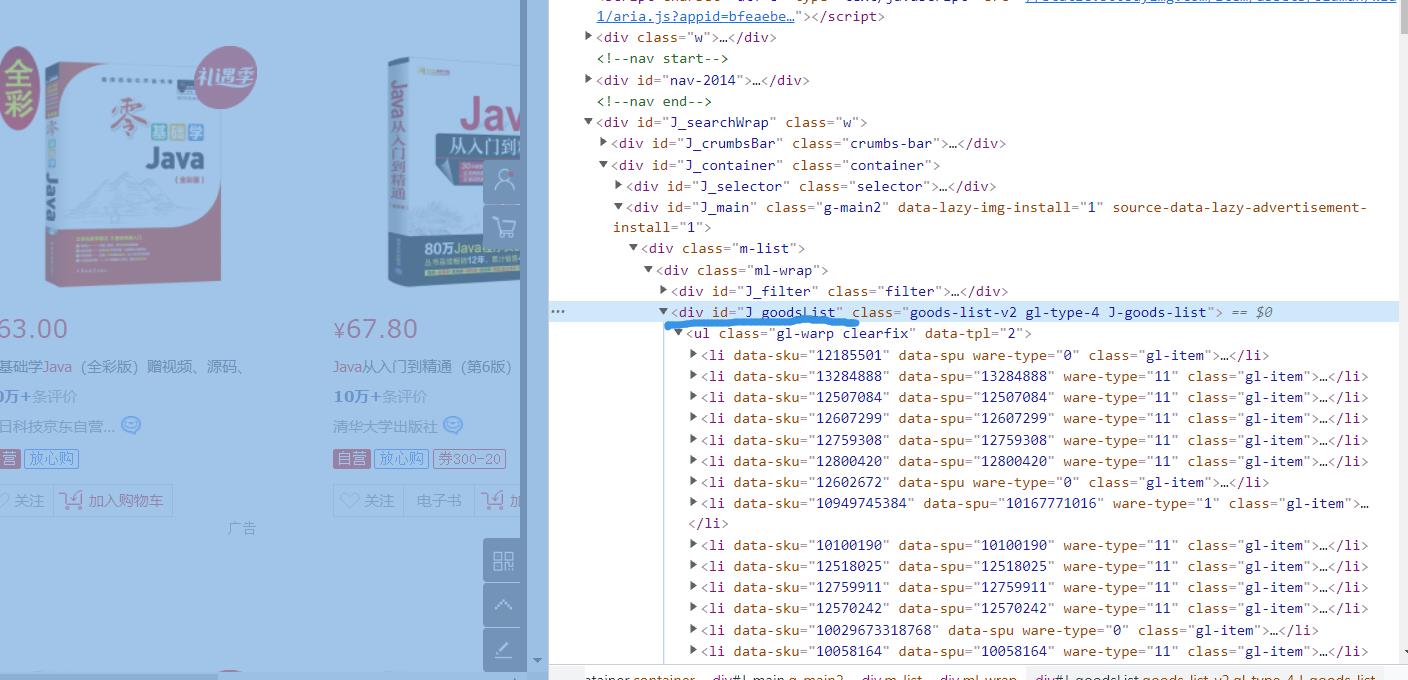
先拿到这个ID,这是整个商品栏,这也是我们代码中绑定获取的ID名。
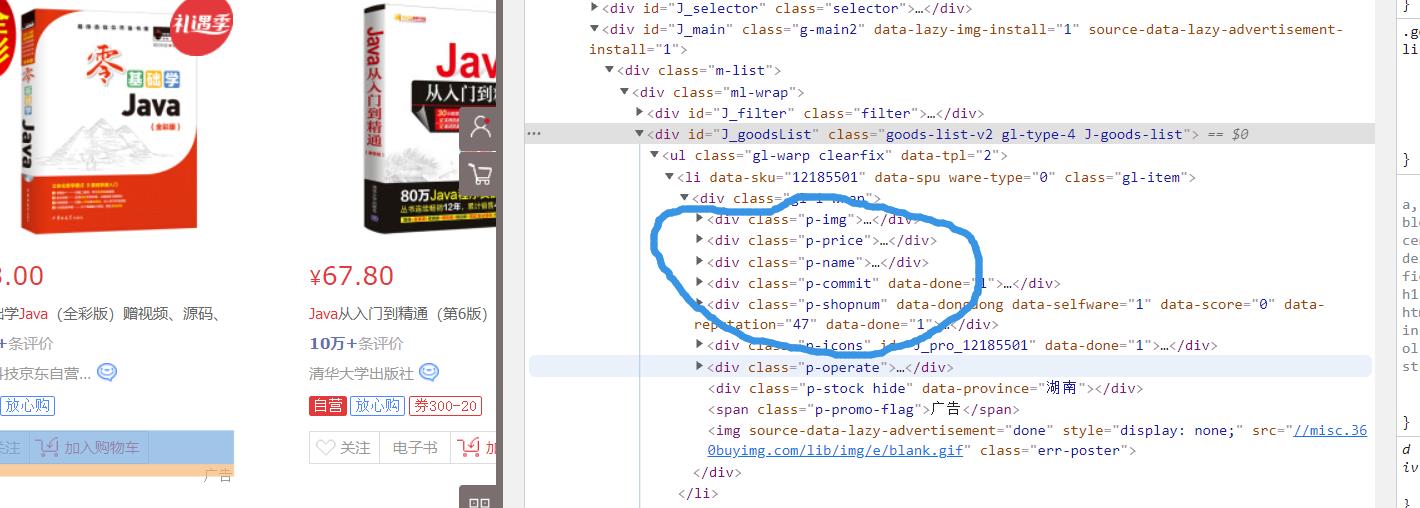 每一个商品的图片、价格、和名称店名也可以看到,这也是我们需要爬的数据,因此在代码中我们使用一个for循环获取这些ID的值。
每一个商品的图片、价格、和名称店名也可以看到,这也是我们需要爬的数据,因此在代码中我们使用一个for循环获取这些ID的值。
代码的运行结果如下:
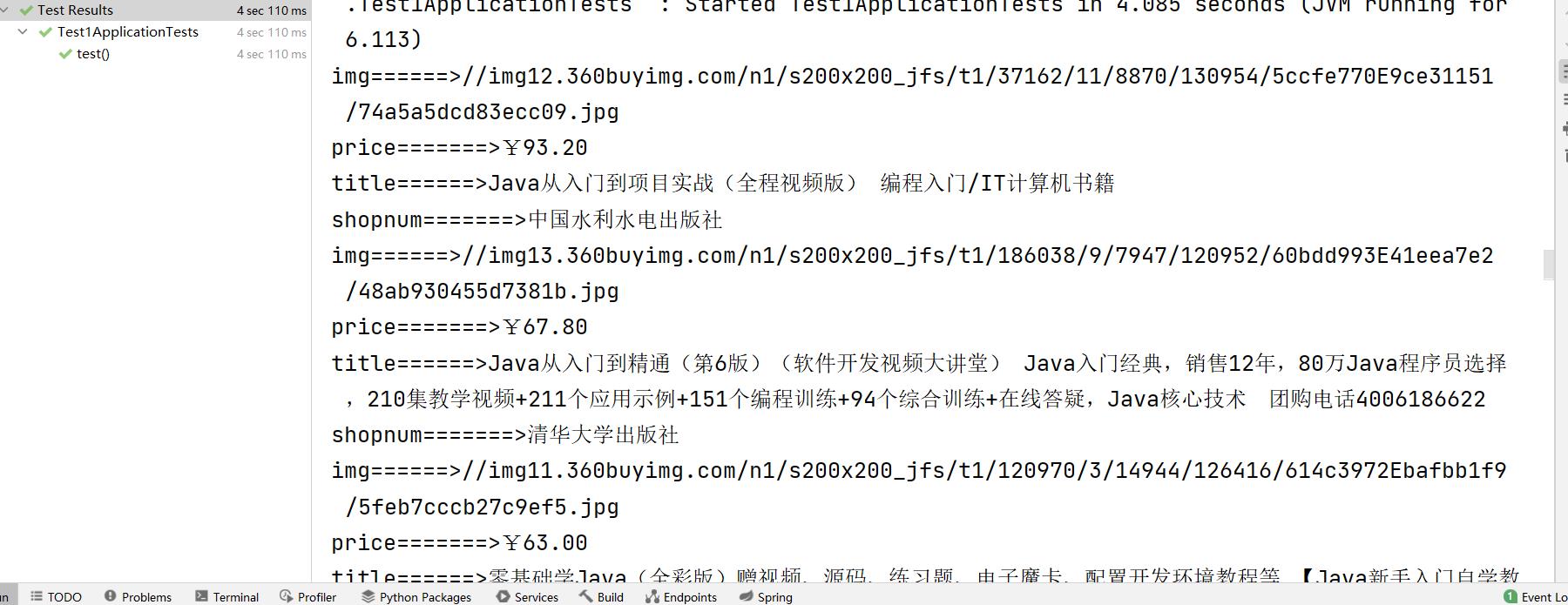
从图中我们可以看到获取的数据就是京东上我们需要的数据
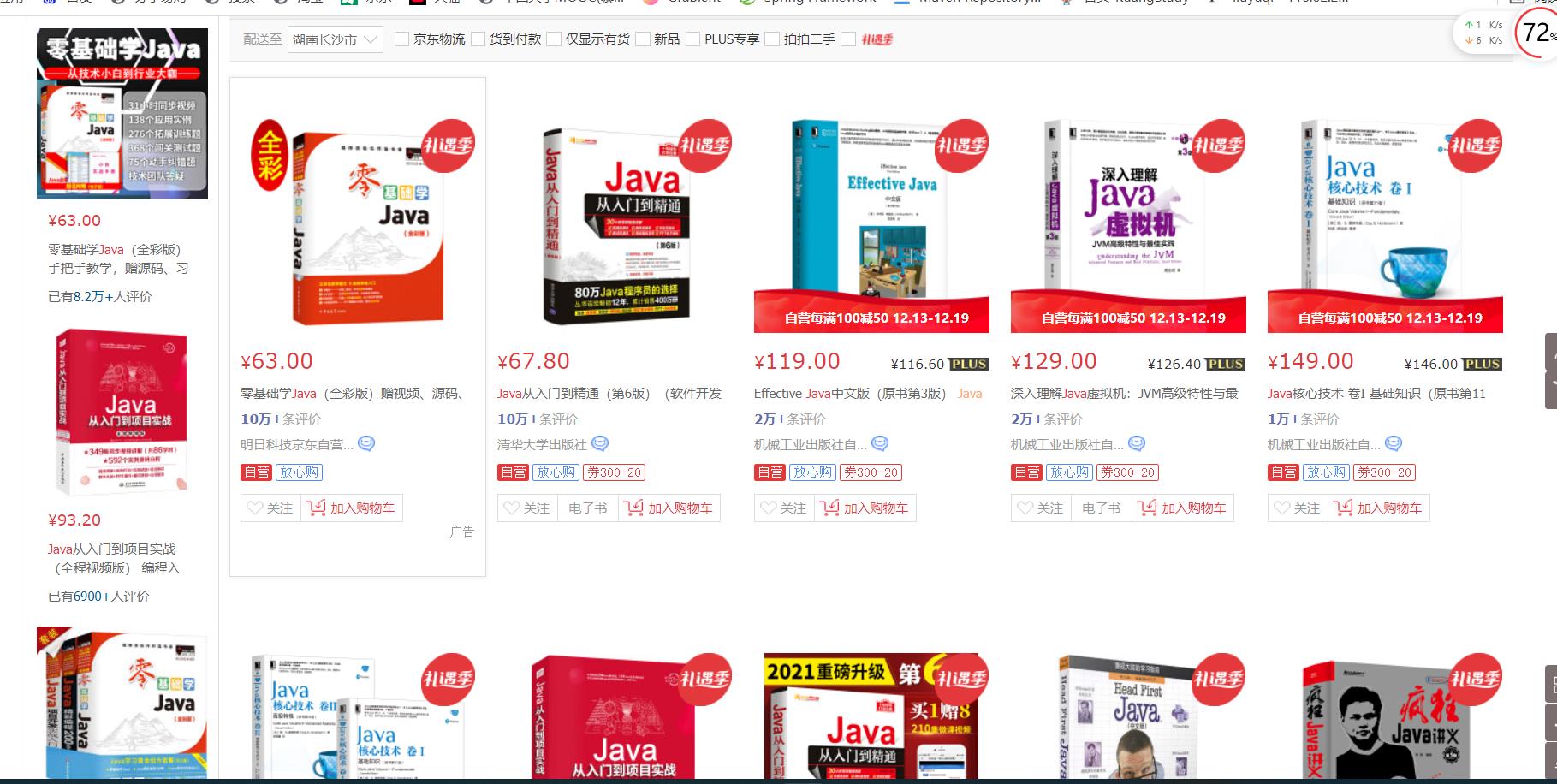
我们看一下图片是不是正常的?
直接将图片地址输入到网址上,可以看出图片能对应上,成功!!!
img12.360buyimg.com/n1/s200x200_jfs/t1/37162/11/8870/130954/5ccfe770E9ce31151/74a5a5dcd83ecc09.jpg

现在我们就已经能够爬到数据了,我们可以将这些数据放入数据库中,如mysql,oracle,解析来一章我会将这些数据放入Elacticsearch全文搜索引擎中。
以上是关于快速入门Java爬虫全文搜索引擎Elasticsearch,分析实战项目:仿京东搜索的主要内容,如果未能解决你的问题,请参考以下文章