Python下实现Tesseract OCR训练字符库(OpenCV-python边缘检测代替jTessBoxEditor手动矫正)
Posted Mirrracle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python下实现Tesseract OCR训练字符库(OpenCV-python边缘检测代替jTessBoxEditor手动矫正)相关的知识,希望对你有一定的参考价值。
(OpenCV 边缘检测代替 jTessBoxEditor 手动矫正)
一、概述
本文详细介绍在Python下实现Tesseract-OCR训练字符库的方法。如果数据集较大,使用jTessBoxEditor对字符进行一一矫正工作量巨大,因此本文讲解如何利用opencv-python对字符进行边缘检测并自动获取最小矩形框坐标,最终生成.box文件,从而完全脱离jTessBoxEditor。
二、环境搭建
1. 下载 Tesseract OCR:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-3.05.01.exe
2. 下载 opencv-python 和 pytesseract(可直接在cmd中下载)
pip install opencv-python
pip install pytesseract
三、生成数据集和训练所需文件
1. 导入需要的包,以及自己写的一个简单的data_agumentation.py
import os
import cv2
import numpy as np
from data_augmentation import *
2. 看一下生成数据集函数的形参和函数内部我预设的参数
def dataset_producing(path, text_list, lang, fontname, exp_num=0, italic=0, bold=0, fixed=0, serif=0, fraktur=0):
# 一、预设参数
space = 80 # 一个字符所占区域大小
row = 64 # 数据增强后排列组合的总数
img_size = (row * space, len(text_list) * space) # 画布大小(h, w)
img = np.zeros(img_size, np.uint8) # (h, w)
img.fill(255) # 填充白色背景
x_box = 0 # 左上角坐标 x
y_box = 0 # 左上角坐标 y
3. 生成 font_properties.txt 文件
with open(os.path.join(path, 'font_properties.txt'), 'w') as fp:
fp.write('%s %d %d %d %d %d'
% (fontname, italic, bold, fixed, serif, fraktur))
文件内的格式:< fontname > < italic > < bold > < fixed > < serif > < fraktur >
此处参考:https://blog.csdn.net/qq_30534935/article/details/83794638
- fontname:字体名称
- italic:斜体(0/1)
- bold:粗体(0/1)
- fixed:默认字体(0/1)
- serif:衬线字体(0/1)
- fraktur:德文黑体(0/1)
4. 生成.tif图像和.box文件 (写字符、扩充数据集、检测边缘、获取最小外接矩形框)
这里我们直接生成一张大图,并用opencv在图中依次写字符并进行增强,最后存储为.tif。当然如果是识别手写字符的话,可以掠过下述代码的1和2,直接从3开始。
下面我对每一个步骤做一个详细的解释(由于是生成一张很大的图像,有多行字符,所以这一部分代码在for循环中,以下先对for循环中的代码片段进行逐个的解释,这一块的完整代码在这一部分的最后)
1) 获取字体大小和基准线
text_size = cv2.getTextSize(text=text_list[j], fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=get_scale(i) / 22, thickness=get_thickness(i))
w, h, baseline = text_size[0][0], text_size[0][1], text_size[1]
因为是一行一行地写字符(第 i 行,第 j 列),所以先在写下字符之前通过 getTextSize() 获取到当前正准备写的字符的 w, h, baseline,以供后面计算每个字符在每个小格子里居中时的起始位置。
getTextSize()中各参数的定义可参考这篇博客:https://blog.csdn.net/u010970514/article/details/84075776
我简单手画了一个图,方便理解 getTextSize() 获取的 baseline 的含义(但真正意义上的baseline指的是第二条红线):

2) 写字符
top_left = (x_box, y_box) # 方框左上角绝对坐标
subImg = img[top_left[1]:top_left[1] + space, top_left[0]:top_left[0] + space] # 获取方框子图
text_org = (int((space - w) / 2), int((space - baseline + h) / 2)) # 字符转成左下角相对坐标并居中
cv2.putText(img=subImg, text=text_list[j], org=text_org, fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=get_scale(i) / 22, color=(0, 0, 0), thickness=get_thickness(i))
我们将整张图看成一个个的小方格,并将每个方格作为一个子图,然后依次在每个子图里进行一系列操作:
- 先获取每个方格左上角的坐标 top_left
- 获取子图 subImg 以便直接对每张子图进行操作
- 计算居中后的字符相对于每个 subImg 的坐标 text_org,转成左下角坐标(因为 putText() 函数中的 org 为字符左下角的坐标。
下图中红色的 baseline 指的是真正意义上的 baseline,而黄色的 baseline 指的是 opencv 中 getTextSize() 函数获取到的 baseline 这个值。对于英文字母而言,所有大写字母和绝大部分小写字母都在 baseline 之上(如下图的 ‘b’ ),而少数小写字母会延伸到baseline之下(如下图的 ‘g’ )。但 getTextSize() 取到的 height 并不包含 baseline 之下的部分,因此如果要使每个字符都居中,则分别对两类字符进行不同的居中操作即可。但为了使生成的图像和我们平时看到的文字排列相同(以baseline为基准写的字),我们选择以延伸到baseline之下的这类字母为标准来居中,居中后的字符左下角坐标计算过程如下图。
(图中字符的边框并不是其最小外接矩形,而是通过 getTextSize() 获取到的,并没有紧贴字符,由于此时还没有开始写字符,因此起始坐标只能通过这种方式获得)
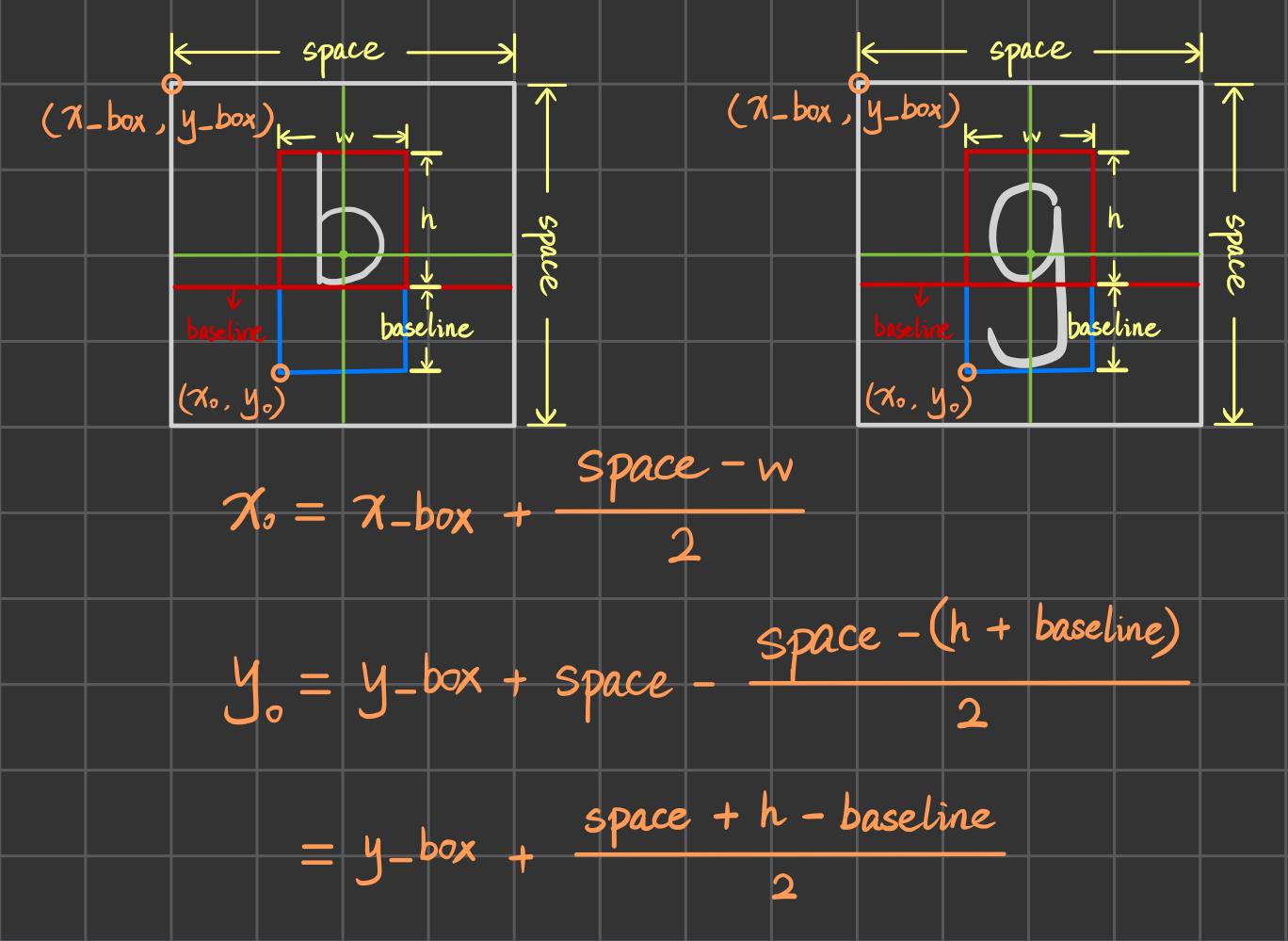
- 计算出可以使字符居中的左下角起始坐标后,使用 putText() 函数对 subImg 进行写字符的操作,org=text_org
3)均值滤波
ksize = (get_ksize(i))
cv2.blur(src=subImg, ksize=ksize, dst=subImg)
使用 blur() 函数对每张 subImg 进行均值滤波(当然也可以选择其它类型的滤波,并排列组合)。ksize 是核的大小,我在另一个文件 data_augmentation.py 中写了一个简陋的 get_ksize() 函数,根据是第几行来选取不同的 ksize,这里大家可以自己设计。
4)图像二值化
ret, binary = cv2.threshold(src=subImg, thresh=254, maxval=255, type=cv2.THRESH_BINARY_INV)
- 由于滤波之后,字符边缘会往外扩散,所以如果直接用 getTextSize() 得到的 w, h, baseline 和 2) 中算到的起始坐标 text_org 来定位并框出字符的话,box的位置必然是不准确的:
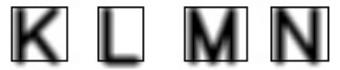
- 且经过实验发现,即使不进行滤波,getTextSize() 得到的 w, h, baseline本身也有一定偏差,框出的框并不是字符的(不旋转的)最小外接矩形:

- 因此,为了找到字符轮廓并画出最小外接矩形,我们需要先通过图像二值化来凸显字符的轮廓:

5)寻找字符的边缘轮廓
contours, hierarchy = cv2.findContours(image=binary, mode=cv2.RETR_EXTERNAL, method=cv2.CHAIN_APPROX_NONE)
binary 是 4) 中得到的二值化图像,**返回值 contours 是 n 组轮廓坐标( n 指该字符由 n 个连通的部分组成,对于大多数英文字母,n=1,对于 i 和 j,n=2)
6)寻找字符的最小外接矩形
方法一(使用 boundingRect() 函数来找到最小外接矩形)(不推荐):
bounding_boxes = [cv2.boundingRect(cnt) for cnt in contours] # x, y 为矩形左上角坐标
if len(bounding_boxes) > 1: # 组合两个不连通的图
x0, y0, w0, h0 = bounding_boxes[0][0], bounding_boxes[0][1], bounding_boxes[0][2], bounding_boxes[0][3]
x1, y1, w1, h1 = bounding_boxes[1][0], bounding_boxes[1][1], bounding_boxes[1][2], bounding_boxes[1][3]
bounding_boxes = [(min(x0, x1), min(y0, y1), max(w0, w1), max(y1 - y0 + h1, y0 - y1 + h0))]
xmin, ymin, w, h = bounding_boxes[0][0], bounding_boxes[0][1], bounding_boxes[0][2], bounding_boxes[0][3]
xmax, ymax = xmin + w, ymin + h
- 使用 boundingRect() 函数获取最小外接矩形的左上角坐标 x, y 以及 w, h。
- 如果获取的 bounding box 长度大于1(即有不止一组轮廓最小外接矩形,如 i 和 j ),则我们需要将其组合。计算过程如下,其中 h 的计算,由于不确定两组坐标的先后,所以选取最大的。(此处只考虑了由两个不连通的图组成的情况,因为英文字母中,一个字母最多也只有两个不连通的图,而数字 0-9 更是不存在这种情况,因此 > 2 的情况暂时不考虑)
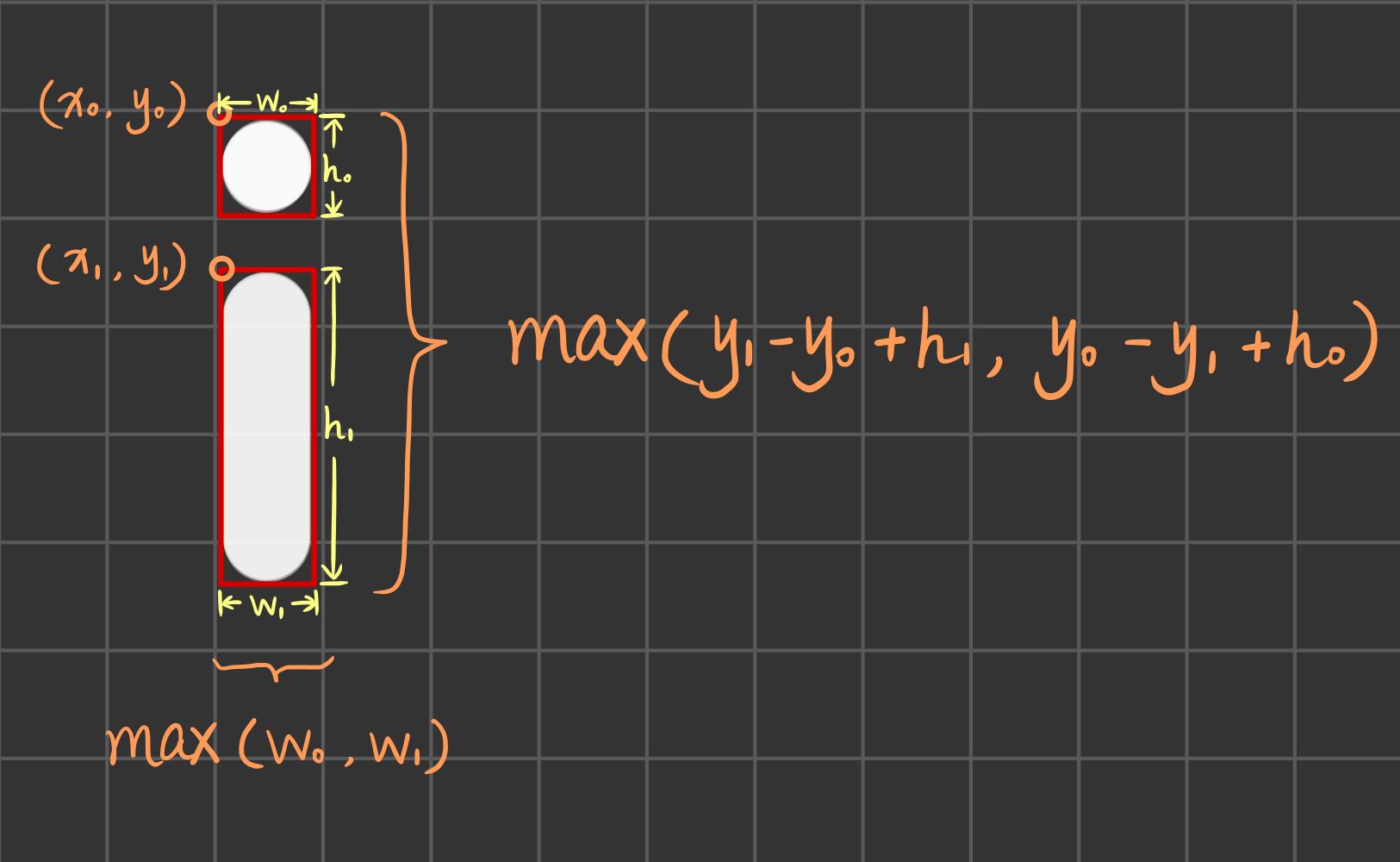
若一个字符由2个以上的不连通的部分组成,则上述方法较为麻烦,因此,我决定不用 boudingRect() 函数。
方法二(寻找xmin, xmax, ymin, ymax)(推荐使用):
pts_x = [] # 存储所有的轮廓横坐标
pts_y = [] # 存储所有的轮廓纵坐标
for part in contours:
for pts in range(len(part)):
pts_x.append(part[pts][0][0])
pts_y.append(part[pts][0][1])
xmin, ymin, xmax, ymax = min(pts_x), min(pts_y), max(pts_x), max(pts_y) # 找到最小外接矩形
该方法直接遍历在一个subImg中找到的所有轮廓坐标,并找出横纵坐标分别的最小和最大值,即可确定最小外接矩形。
7) 生成.box文件
xmin_new, xmax_new = x_box + xmin, x_box + xmax # 将子图坐标转成相对于原图的坐标
ymin_new, ymax_new = img_size[0] - y_box - ymax, img_size[0] - y_box - ymin # 转换成以左下角为原点的坐标系的坐标 (.box文件中以左下角为原点)
fp.write('%s %d %d %d %d %d'
% (text_list[j], xmin_new, ymin_new, xmax_new, ymax_new, 0)) # 将(字符、x、y-h、x+w、y、页码)写入txt文件
fp.write('\\n')
这个步骤主要在做一些坐标转换。由于我们之前的操作都是以左上角为原点的,而 .box 文件中的坐标是以左下角为原点的,因此需要做一个转换。
- 首先看一下 .box 文件的格式:

- 坐标转换计算:

8)将图像存储为.tif
tif = font + '.tif'
cv2.imwrite(filename=os.path.join(path, tif), img=img)
print('%s.tif generated successfully!' % font)
5. 生成train.bat批处理文件
这一部分的问题还未解决,问题写在最后两行的注释里了,如果有人知道原因和解决方法,希望可以与我交流。
train_bat = 'echo Run Tesseract for Training.. \\r' \\
'tesseract.exe %s.tif %s nobatch box.train \\r\\n' \\
'echo Compute the Character Set.. \\r' \\
'unicharset_extractor.exe %s.box \\r' \\
'mftraining -F font_properties.txt -U unicharset -O %s.unicharset %s.tr \\r\\n' \\
'echo Clustering.. \\r' \\
'cntraining.exe %s.tr \\r\\n' \\
'echo Rename Files.. \\r' \\
'rename normproto %s.normproto \\r' \\
'rename inttemp %s.inttemp \\r' \\
'rename pffmtable %s.pffmtable \\r' \\
'rename shapetable %s.shapetable \\r\\n' \\
'echo Create Tessdata.. \\r' \\
'combine_tessdata.exe %s. \\r\\n' \\
'echo. & pause' \\
% (font, font, font, lang, font, font, lang, lang, lang, lang, lang)
with open(os.path.join(path, 'train.bat'), 'w') as fp:
fp.write(train_bat)
print('train.bat generated successfully!')
# 上述生成的.bat文件无法直接执行、具体原因尚不明确,需要将文件以编辑的形式打开、复制下来,粘贴到新建的txt文件中,再更改后缀为.bat
# 已经过多次排查,只有上述方法可以得到可以执行的批处理文件,即使文件内容由复制粘贴得来完全一样,文件大小相差14kb,原因未知
第三部分的完整代码:
import os
import cv2
import numpy as np
from data_augmentation import *
def dataset_producing(path, text_list, lang, fontname, exp_num=0, italic=0, bold=0, fixed=0, serif=0, fraktur=0):
# 一、预设参数
space = 80 # 一个字符所占区域大小
row = 64 # 数据增强后排列组合的总数
img_size = (row * space, len(text_list) * space) # 画布大小(h, w)
img = np.zeros(img_size, np.uint8) # (h, w)
img.fill(255) # 填充白色背景
x_box = 0 # 左上角x
y_box = 0 # 左上角y
# 二、生成font_properties.txt文件
with open(os.path.join(path, 'font_properties.txt'), 'w') as fp:
fp.write('%s %d %d %d %d %d' % (fontname, italic, bold, fixed, serif, fraktur))
print('font_properties.txt generated successfully!')
# 三、生成.tif图像和.box文件 (写字符、检测边缘、获取最小外接矩形框)
font = '%s.%s.exp%d' % (lang, fontname, exp_num)
with open(os.path.join(path, '%s.box' % font), 'w') as fp:
for i in range(int(img_size[0] / space)): # 写第i行
for j in range(int(img_size[1] / space)): # 写第j列
# 1、获取字体大小和基准线
text_size = cv2.getTextSize(text=text_list[j], fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=get_scale(i) / 22, thickness=get_thickness(i))
w, h, baseline = text_size[0][0], text_size[0][1], text_size[1]
# 2、写字符
top_left = (x_box, y_box) # 方框左上角绝对坐标
subImg = img[top_left[1]:top_left[1] + space, top_left[0]:top_left[0] + space] # 获取方框子图
text_org = (int((space - w) / 2), int((space - baseline + h) / 2)) # 字符转成左下角相对坐标并居中
cv2.putText(img=subImg, text=text_list[j], org=text_org, fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=get_scale(i) / 22, color=(0, 0, 0), thickness=get_thickness(i))
# 3、均值滤波 (对子图进行滤波操作时需要加上dst,否则不对原图产生改变)
ksize = (get_ksize(i))
cv2.blur(src=subImg, ksize=ksize, dst=subImg)
# 4、图像二值化
ret, binary = cv2.threshold(src=subImg, thresh=254, maxval=255, type=cv2.THRESH_BINARY_INV)
# 5、寻找字符边缘轮廓
contours, hierarchy = cv2.findContours(image=binary, mode=cv2.RETR_EXTERNAL, method=cv2.CHAIN_APPROX_NONE)
# 6、寻找字符最小外接矩形
# # 方法一:
# bounding_boxes = [cv2.boundingRect(cnt) for cnt in contours] # x, y 为矩形左上角坐标
# if len(bounding_boxes) > 1: # 组合两个不连通的图
# x0, y0, w0, h0 = bounding_boxes[0][0], bounding_boxes[0][1], bounding_boxes[0][2], bounding_boxes[0][3]
# x1, y1, w1, h1 = bounding_boxes[1][0], bounding_boxes[1][1], bounding_boxes[1][2], bounding_boxes[1][3]
# bounding_boxes = [(min(x0, x1), min(y0, y1), max(w0, w1), max(y1 - y0 + h1, y0 - y1 + h0))]
# xmin, ymin, w, h = bounding_boxes[0][0], bounding_boxes[0][1], bounding_boxes[0][2], bounding_boxes[0][3]
# xmax, ymax = xmin + w, ymin + h
# 方法二:
pts_x = [] # 存储所有的轮廓横坐标
pts_y = [] # 存储所有的轮廓纵坐标
for part in contours:
for pts in range(len(part)):
pts_x.append(part[pts][0][0])
pts_y.append(part[pts][0][1])
xmin, ymin, xmax, ymax = min(pts_x), min(pts_y), max(pts_x), max(pts_y) # 找到最小外接矩形
# # 画出最小外接矩形 (测试时可用)
# cv2.rectangle(img=subImg, pt1=(xmin, ymin), pt2=(xmax, ymax), color=(0, 255, 0), thickness=1)
# 7、生成box文件
xmin_new, xmax_new = x_box + xmin, x_box + xmax # 将子图坐标转成相对于原图的坐标
ymin_new, ymax_new = img_size[0] - y_box - ymax, img_size[0] - y_box - ymin # 转换成以左下角为原点的坐标系的坐标 (.box文件中以左下角为原点)
fp.write('%s %d %d %d %d %d'
% (text_list[j], xmin_new, ymin_new, xmax_new, ymax_new, 0)) # 将(字符、x、y-h、x+w、y、页码)写入txt文件
fp.write('\\n')
x_box += space # 写下一列
x_box = 0 # x返回第一列
y_box += space # 写下一行
print('%s.box generated successfully!' % font)
# # 画网格(测试居中时使用)
# y = 0
# for i in range(int(img_size[0] / space)): # 画横线
# cv2.line(img=img, pt1=(0, y), pt2=(img_size[1], y), color=(0, 0, 0), thickness=1) # 画网格
# y += space
# x = 0
# for i in range(int(img_size[1] / space)): # 画竖线
# cv2.line(img=img, pt1=(x, 0), pt2=(x, img_size[0]), color=(0, 0, 0), thickness=1) # 画网格
# x += space
# 8、将图像存储为.tif以供训练
tif = font + '.tif'
cv2.imwrite(filename=os.path.join(path, tif), img=img)
print('%s.tif generated successfully!' % font)
# 四、生成train.bat批处理文件
train_bat = 'echo Run Tesseract for Training.. \\r' \\
'tesseract.exe %s.tif %s nobatch box.train \\r\\n' \\
'echo Compute the Character Set.. \\r' \\
'unicharset_extractor.exe %s.box \\r' \\
'mftraining -F font_properties.txt -U unicharset -O %s.unicharset %s.tr \\r\\n' \\
'echo Clustering.. \\r' \\
'cntraining.exe %s.tr \\r\\n' \\
'echo Rename Files.. \\r' \\
'rename normproto %s.normproto \\r' \\
'rename inttemp %s.inttemp \\r' \\
'rename pffmtable %s.pffmtable \\r' \\
'rename shapetable %s.shapetable \\r\\n' \\
'echo Create Tessdata.. \\r' \\
'combine_tessdata.exe %s. \\r\\n' \\
'echo. & pause' \\
以上是关于Python下实现Tesseract OCR训练字符库(OpenCV-python边缘检测代替jTessBoxEditor手动矫正)的主要内容,如果未能解决你的问题,请参考以下文章