Numpy与PandasSklearn中one-hot快速编码方法
Posted 肖永威
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Numpy与PandasSklearn中one-hot快速编码方法相关的知识,希望对你有一定的参考价值。
1. 前言
在机器学习、深度学习分类算法中,需要把分类标识转换为数值,例如客户留存、流失、预计流失、新客户分别对应数字【0、1、2、3】。这样离散型编码数据,数值大小在算法没有实际意义,还容易造成负面影响。对于这种情况,常用解决方案是使用one_hot编码。
例如:一组客户生命周期状态数据:
| carduser_id | 状态 | 编码 |
|---|---|---|
| 12345 | 预计流失 | 2 |
| 223432 | 流失 | 1 |
| 343424 | 新客户 | 3 |
对应one_hot编码解决方案
| 客户留存 | 流失 | 预计流失 | 新客户 |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 0 | 0 | 1 |
什么是 one-hot 编码?
独热编码即 One-Hot 编码,又称一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
One-Hot 编码是分类变量作为二进制向量的表示。
(1) 将分类值映射到整数值。
(2) 然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
在构建分类算法的时候,客户标签通常都要求是one_hot编码,实际上标签可能各种离散形式,当然也包括整数值。
例如:
性别特征:["男","女"]
省份特征:["黑龙江","湖北","四川"]
运动特征:["马拉松","足球","篮球","羽毛球","乒乓球"]
2. 如何使用Numpy快速编码
在numpy中,可以使用eye()函数,便捷生成one_hot编码,先简单介绍eye()函数的功能。
函数:np.eye(N, M=None, k=0, dtype=float, order=‘C’)
功能说明:用来返回一个2维的对角数组
参数:
- N:int型,用来控制输出二维数组的行数
- M:int型,用来控制输出二维数组的列数,如果M为None,则M等于N
- k:int型,可选项,主对角线的index,默认是0,如果k为正数,则对角线往上移动,如果k为负数,则对角线往下移动
- dtype:数据的类型,可选项,返回的数据的数据类型
- order:‘C’,‘F’,可选项,也就是输出的数组的形式是按照C语言的行优先’C’,还是按照Fortran形式的列优先‘F’存储在内存中。
例如:生成one-hot形式数组
#设置类别的数量
num_classes = 4
#需要转换的整数
arr = [2,3,1]
#将整数转为一个4位的one hot编码
print(np.eye(num_classes )[arr])
输出如下:
[[0. 0. 1. 0.]
[0. 0. 0. 1.]
[0. 1. 0. 0.]]
3. 在Pandas中快速编码方法
3.1. 使用pd.get_dummies
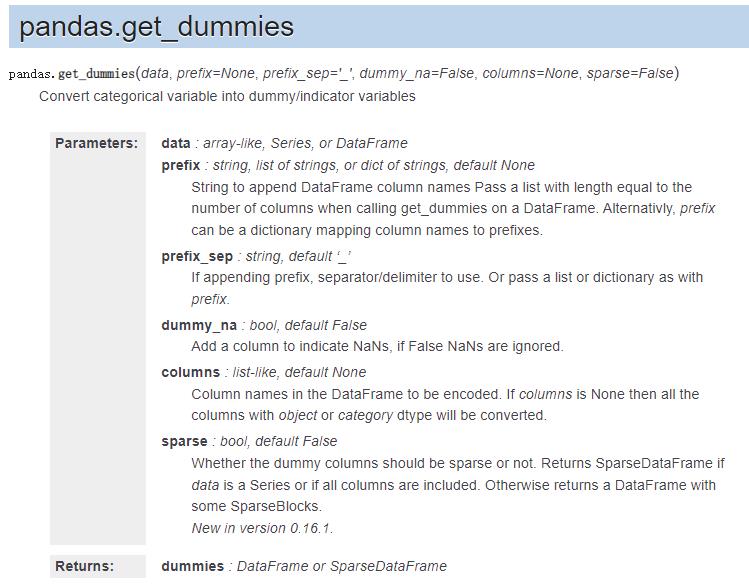
import pandas as pd
df = pd.DataFrame('carduser_id': [12345,223432,343424],
'gender': ['男','男','女'])
dummies = pd.get_dummies(df)
dummies = dummies.rename(columns='gender_女':'female','gender_男':'male')
dummies
从输入(下图左1),执行过程如下图所示。

注:不知列名有没有很好的命名方法。
3.2. 自己控制编码
import pandas as pd
df = pd.DataFrame('carduser_id': [12345,223432,343424],
'gender': ['男','男','女'])
df['male']= df['gender'].apply(lambda x:1 if x=='男' else 0)
df['female']= df['gender'].apply(lambda x:1 if x=='女' else 0)
df = df.drop(['gender'], axis=1)
df

4. Sklearn中OneHotEncoder方法
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
df = pd.DataFrame('carduser_id': [12345,223432,343424],
'gender': ['男','男','女'])
gender = df['gender'].values
encoder=OneHotEncoder(sparse=False) # One-Hot编码
ans=encoder.fit_transform(gender.reshape((-1,1)))
ans
array([[0., 1.],
[0., 1.],
[1., 0.]])
5. 总结
在机器学习、深度学习过程中,针对类别、分类离散型数据,one hot encoding是常用的方案,在numpy、pandas、SKlearn中分别给出了便捷解决方案,建议优先考虑。
参考:
[1]. 修炼之路. numpy快速生成one hot编码. CSDN博客. 2019.01
[2]. 梦dancing. 机器学习数据预处理1:独热编码(One-Hot)及其代码. CSDN博客. 2019.04
[3]. 肖永威. 大数据人工智能常用特征工程与数据预处理Python实践(1). CSDN博客. 2020.12
以上是关于Numpy与PandasSklearn中one-hot快速编码方法的主要内容,如果未能解决你的问题,请参考以下文章