数据科学之 如何找到指标的最 佳分裂点的几个想法
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据科学之 如何找到指标的最 佳分裂点的几个想法相关的知识,希望对你有一定的参考价值。
1 问题定义
一类问题:
影响整体用户活跃度,的因素中有单次打开时长这一指标,
如何找到打开多久是比较好的阈值?
这个可以看成是一个有监督的寻找合理分裂点的过程,这里就抛砖引玉几种可能性
- 决策树来找分裂点
- 有监督分箱(卡方/决策树)
- 离散回归模型(比较好的一种)
- shap值
另一类问题(下篇给出最近的想法):
张三是一个连锁店的老板,他想知道每个门店店员做的好/坏,
光看销售额是最简单粗暴,比较有利的能不能看到店员的画像,
比如服务态度、工龄、所在区域等;
另外有没有一种可能,工龄从青年 -> 中年,销售额可以量化提升多少?
最终可以给每个门店设置KPI。
2 关联方法
2.1 决策树来找分裂点
盗图来看一下:非常fancy的可视化决策树dtree_viz
这个是比较传统的决策树分裂的图,可以从其中看到重要特征的分裂点:
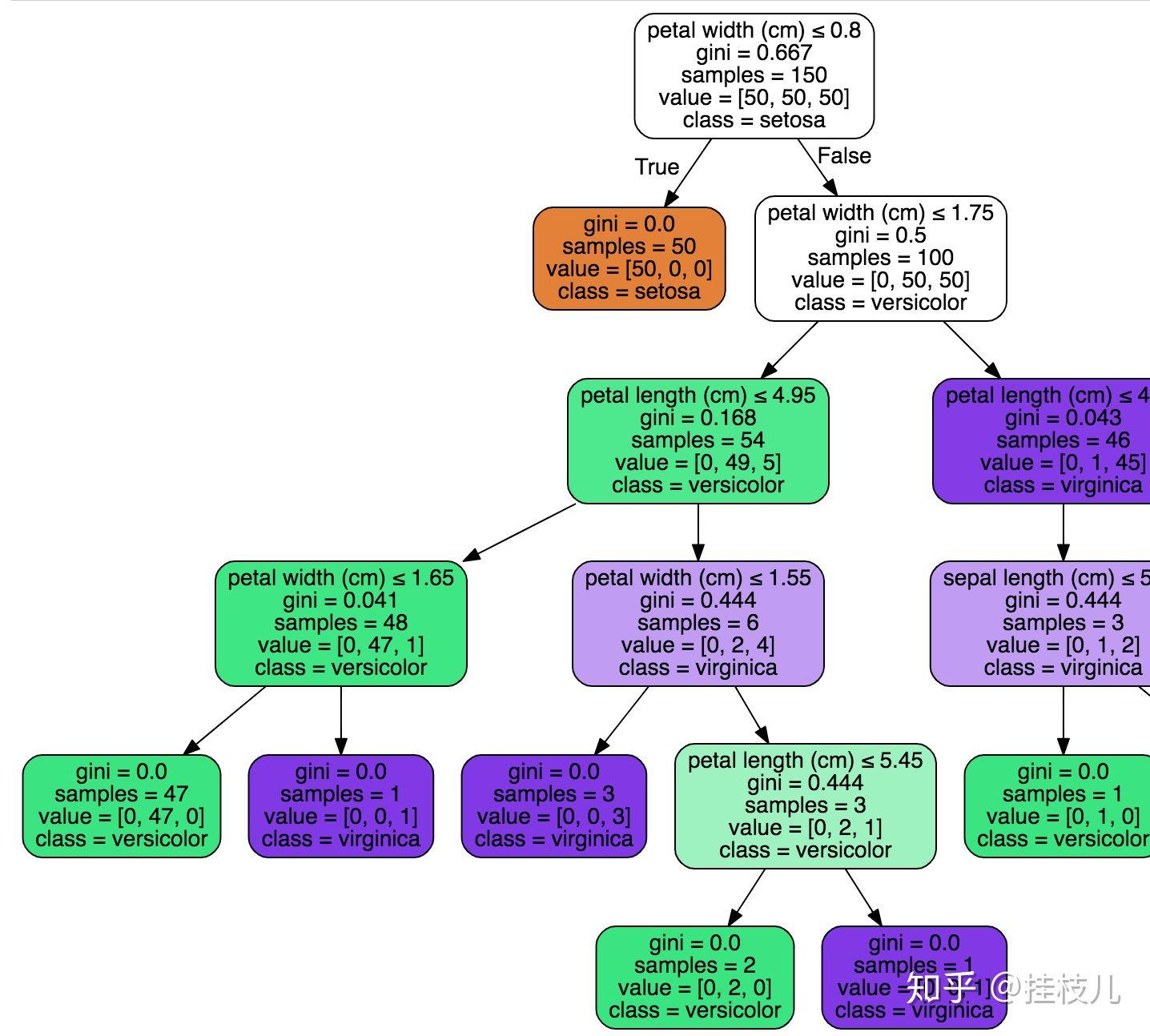
当然还有可视化效果更好的就是:

依照上面的寻找分裂点,那就是petal length这个指标,[1.75,4.85,4.95]是分割点;
当然这个分割点的由来是由GINI最小的作为分割点,而且有可能一个单一指标,可以细分很碎,取到什么层级是比较好的?
可以要从指标的覆盖度等角度来衡量取到什么粒度了。
2.2 有/无 监督分箱(等比/等宽-卡方/决策树)
参考:评分卡应用 - 利用Toad进行有监督分箱(卡方分箱/决策树分箱)
影响整体用户活跃度,的因素中有单次打开时长这一指标,
如何找到打开多久是比较好的阈值?
无监督分箱那就非常简单了,等比/等宽进行处理 单次打开时长 后,在每个分区计算用户活跃度的差异,来找到比较比较好的分裂点。
这里还有有监督的方式,也是一种比较科学的,用户活跃度(是否活跃1/0) ~ 单词打开时长,根据IV来寻找分割点,这里分割的几个准则:每箱样本量、固定箱数等来判定。
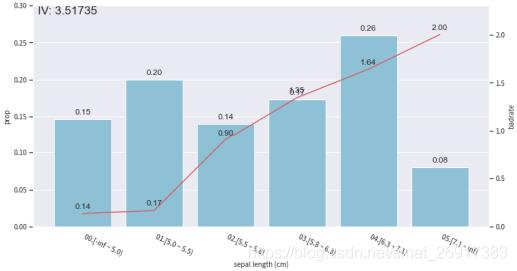
比如此时,依图可以这么划分:
单次打开时长,[0,5.5],占所有样本的35%,在这里面都是label = 2的样本;
单次打开时长[7.1,+ ),占所有样本的8%,这里面 y label的平均值为1.64
这里最佳的分裂点其实是可以“自我调节”出来的
2.3 离散回归模型(比较好的一种)
重复事件(表现形态:活跃、留存、复购)建模的案例学习笔记
来到文章的【1.3.2 PWP-GT 重复事件建模在看点业务中的实际应用】,可以看到:

这里YY一下,比如打开时长a,均等切分为,[a0,a1,…,a6],可能实际含义是[0h,1h,…,5h],然后对活跃度=Y做回归,
这里的回归系数的显著性,就是指标合理的表现,
来YY解读一下这个图,[a0,a1],[a1,a2]是不显著的,其他都是显著的;代表,打开时长在2h以上的是明显的,这是一个非常重要的阈值。
而且,还可以量化出来说,如果打开时长在[a4,a5]([4h,5h])那么活跃度会比[a0,a1]高出40%
如果要在显著的时间里面再画一个阈值,可以观察系数的增长幅度,比如:
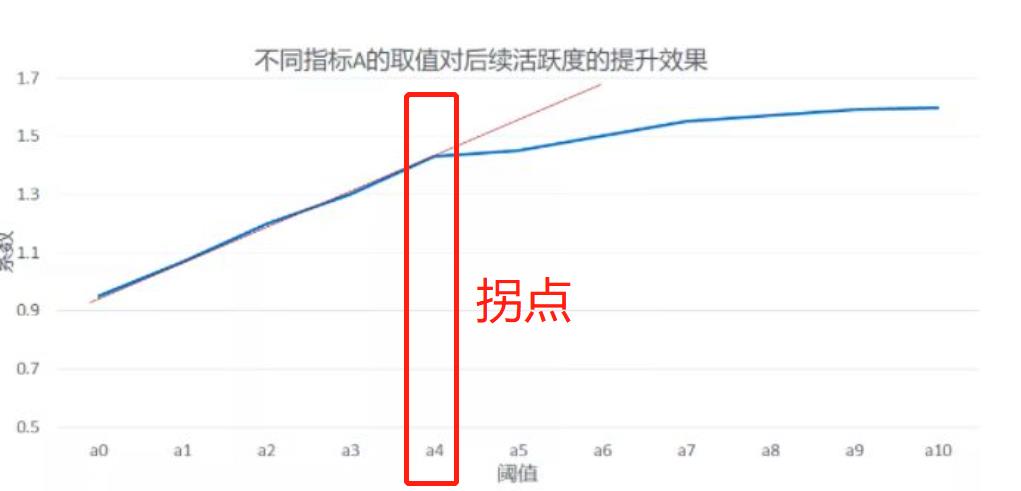
那a4,4H就是一个非常好的新阈值点;
所以离散回归是非常好的可以找到阈值、量化指标水平的方式。
2.4 shap值
重复事件(表现形态:活跃、留存、复购)建模的案例学习笔记在【2.2 指标阈值确定下腾讯看点与快手的差别】小节,有提到shap值的方式
用特征密度散点图:beeswarm:

假设LSTAT这个指标,越大(红)可能导致SHAP约低,则选择蓝/红渐变那个阶段,作为阈值;
那么YY成这次的命题,RM是打开时长,整体Y是活跃度;
这里代表,打开时长越长(越红),对活跃度越有利(SHAP值为正);
分割点应该就是shap值=0时,打开时长的值,比如是3H,这里可以看到:
- 3H以上的用户比较少
- 3H以下的用户,比较多
以上是关于数据科学之 如何找到指标的最 佳分裂点的几个想法的主要内容,如果未能解决你的问题,请参考以下文章