线上500万数据查询时间在37秒,作者将问题解决了,我看到了更大的坑
Posted 谙忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线上500万数据查询时间在37秒,作者将问题解决了,我看到了更大的坑相关的知识,希望对你有一定的参考价值。
线上500万数据查询时间在37秒,作者将问题解决了,我看到了更大的坑
总结
最近看到一篇文章,讲述了一个500万数据查询37秒的问题和解决方案。我先帮大家总结一下解决方案。
另外,看完这篇文章,我觉得虽然问题解决了。但是这个强制索引的解决方案并不是很好。
我就说一说在这个案例中用强制索引在公司团队开发中未来可能会遇到的问题:
- 系统有很多时候是根据系统信息来决定用哪个索引,一般系统是以最优化方式。现在强制用时间,但是下次筛选时间条件一变化,大概率又出问题
- 当查询条件 end_time > and end_time <= 这个区间的数据量达到总表数据量一定比例,强制走索引也会很慢。我的建议是,将end_time条件提前,再与org_id等id建立好联合索引,强制走这个联合索引。其他不必要索引删除掉
- 开发与DBA,在一些职能划分比较明确的公司,这是两个不同的工种。一般而言:开发接触不到数据库的实际命令操作;而DBA也不会了解业务是什么样的。那么,当人员流动,查询条件改变,没人知道这个强制索引的坑。
在这里,如果作者是在公司团队内开发,我的建议是,不要加强制索引,将未来又可能会暴露的问题留给后面接盘的人、而假设那人按照你当前治标不治本的解决方案,解决他遇到的问题后,你现在遇到的问题,后续可能又会出现。
由于我也不知道该作者的数据结构,以及他的业务场景究竟是哪样的。所以只是提一下可以考虑的点。
在这里,我想总结的一点是,如果遇到查询慢的情况,首先要做的事情,就是检查有没有走索引!
如果走索引,检查索引是否合适,或者是优化SQL语句,优化查询顺序等。最后再考虑分表、分库、缓存。
对于索引选择性低的字段,没必要单独建立索引(例如:给bool型加索引的目的是什么?索引区分度是2,就算加了,估计也是要走全表扫描的。也就是说加了索引带来写性能的下降和存储空间的增大,但对读性能提升没什么帮助。),联合索引可以考虑。
另外,特殊情况也可以考虑,例如:比如要对一个 bool 字段索引,首先你要保证其中 99.9% 的值都是 false,而你恰恰仅需要依靠索引找到其中值为 true 的那些行。(这里,不知道能不能对单独的数据,当字段为true时的数据建立索引即可。希望知道的朋友能在评论区给下解答)
以下为原文地址的内容:https://www.cnblogs.com/dijia478/p/11550902.html
一、问题背景
现网出现慢查询,在500万数量级的情况下,单表查询速度在30多秒,需要对sql进行优化,sql如下:
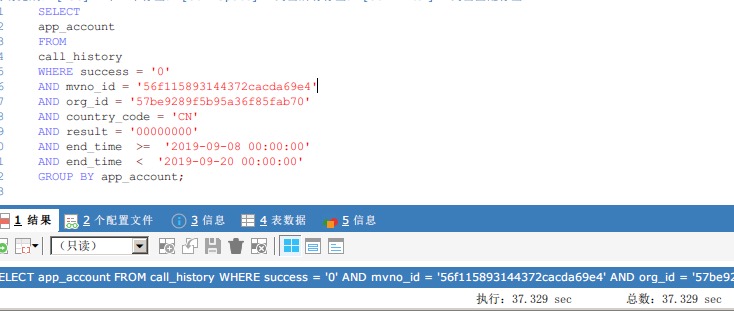
我在测试环境构造了500万条数据,模拟了这个慢查询。
简单来说,就是查询一定条件下,都有哪些用户的,很简单的sql,可以看到,查询耗时为37秒。
说一下app_account字段的分布情况,随机生成了5000个不同的随机数,然后分布到了这500万条数据里,平均来说,每个app_account都会有1000个是重复的值,种类共有5000个。
二、看执行计划
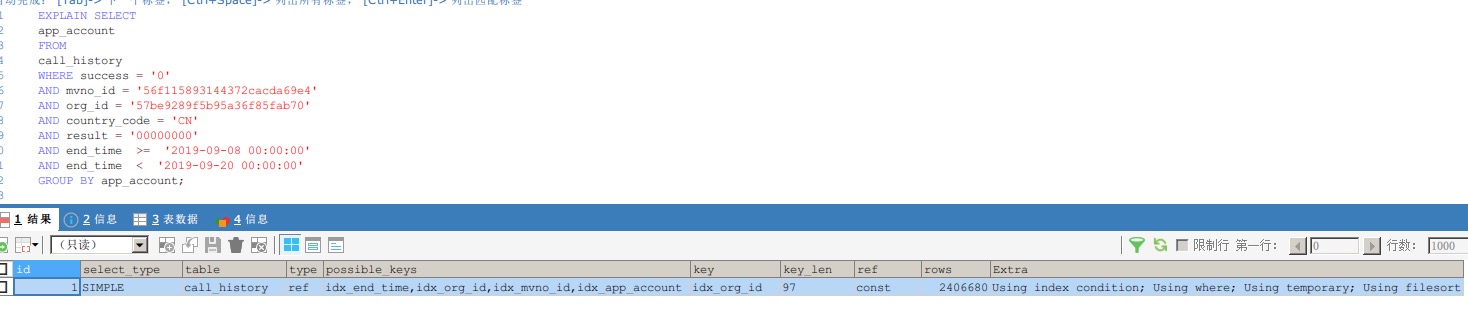
可以看到,group by字段上我是加了索引的,也用到了。
三、优化
说实话,我是不知道该怎么优化的,这玩意还能怎么优化啊!先说下,下面的思路都是没用的。
思路一:
后面应该加上 order by null;避免无用排序,但其实对结果耗时影响不大,还是很慢。

思路二:
where条件太复杂,没索引,导致查询慢,但我给where条件的所有字段加上了组合索引,也还是没用
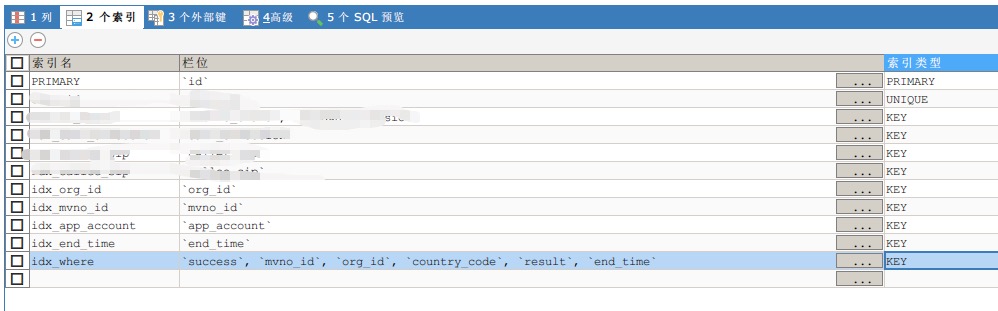
思路三:
既然group by慢,换distinct试试??(这里就是本篇博客里说的神奇的地方了)
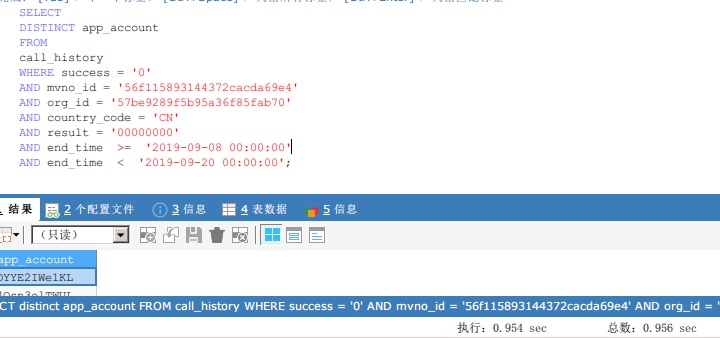
卧槽???!!!这是什么情况,瞬间这么快了??!!!
虽然知道group by和distinct有很小的性能差距,但是真没想到,差距居然这么大!!!大发现啊!!
四、你以为这就结束了吗
我是真的希望就这么结束了,那这个问题就很简单的解决了,顺便还自以为是的发现了一个新知识。
但是!
这个bug转给测试后,测试一测,居然还是30多秒!?这是什么情况!!???
我当然是不信了,去测试电脑上执行sql,还真是30多秒。。。
我又回我的电脑上,连接同一个数据库,一执行sql,0.8秒!?
什么情况,同一个库,同一个sql,怎么在两台电脑执行的差距这么大!
后来直接在服务器上执行:
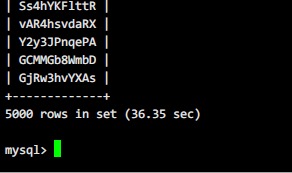
醉了,居然还是30多秒。。。。
那看来就是我电脑的问题了。
后来我用多个同事的电脑实验,最后得出的结论是:
是因为我用的SQLyog!
哎,现在发现了,只有用sqlyog执行这个“优化后”的sql会是0.8秒,在navicat和服务器上直接执行,都是30多秒。
那就是sqlyog的问题了,现在也不清楚sqlyog是不是做什么优化了,这个慢查询的问题还在解决中(我觉得问题可能是出在mysql自身的参数上吧)。
这里只是记录下这个坑,sqlyog执行sql速度,和服务器执行sql速度,在有的sql中差异巨大,并不可靠。
五、后续(还未解决)
感谢大家在评论里出谋划策,我来回复下问题进展:
1.所谓的sqlyog查询快,命令行查询慢的现象,已经找到原因了。是因为sqlyog会在查询语句后默认加上limit 1000,所以导致很快。这个问题不再纠结。
2.我已经试验过的方法(都没有用):
①给app_account字段加索引。
②给sql语句后面加order by null。
③调整where条件里字段的查询顺序,有索引的放前面。
④给所有where条件的字段加组合索引。
⑤用子查询的方式,先查where条件里的内容,再去重。
测试环境和现网环境数据还是有点不一样的,我贴一张现网执行sql的图(1分钟。。。):

六、最终解决方案
感谢评论里42楼的@言枫大佬!
经过你的提醒,我确实发现,explain执行计划里,索引好像并没有用到我创建的idx_end_time。
然后果断在现网试了下,强制指定使用idx_end_time索引,结果只要0.19秒!
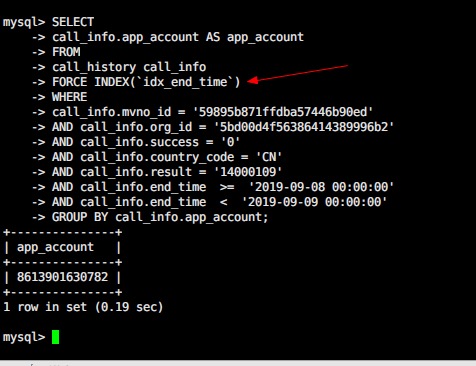
至此问题解决,其实同事昨天也在怀疑,是不是这个表索引建的太多了,导致用的不对,原本用的是idx_org_id和idx_mvno_id。
现在强制指定idx_end_time就ok了!
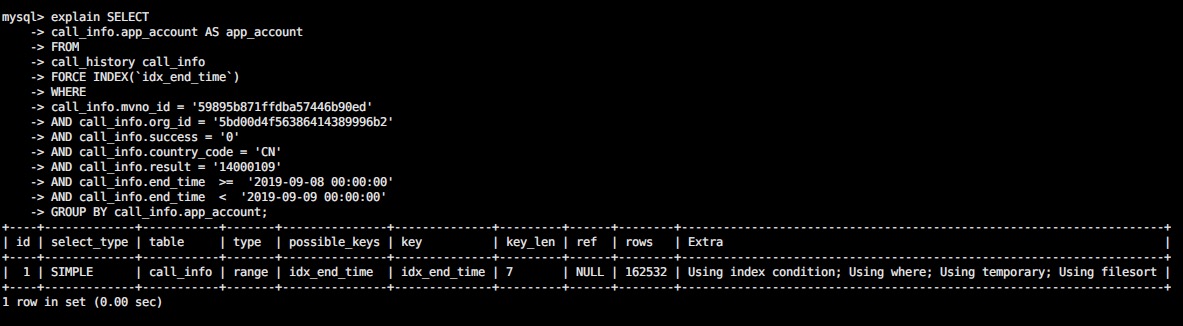
最后再对比下改前后的执行计划:
改之前(查询要1分钟左右):

改之后(查询只要几百毫秒):
以上是关于线上500万数据查询时间在37秒,作者将问题解决了,我看到了更大的坑的主要内容,如果未能解决你的问题,请参考以下文章