datax源码解析-任务调度机制解析
Posted 犀牛饲养员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了datax源码解析-任务调度机制解析相关的知识,希望对你有一定的参考价值。
写在前面
完成任务的拆分后,就该进入任务的调度阶段了(shedule)。关于拆分阶段的解析请点击下方的链接阅读:
任务调度阶段总结起来做的事情其实就是,把前一个阶段拆分出来的task,按照一定的规则进行分组(taskGroup),然后每组单独分配独立的线程进行调度处理。
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
下面就基于源码分析下具体的过程。这里要说明下,schedule阶段的代码比较多,我后面在解析过程中,只贴出来关键的代码。
正文
/**
* 这里的全局speed和每个channel的速度设置为B/s
*/
//每个taskgroup运行的task数量
int channelsPerTaskGroup = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);
//task总数
int taskNumber = this.configuration.getList(
CoreConstant.DATAX_JOB_CONTENT).size();
//防止指定的并发数量比task数量多
this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);
PerfTrace.getInstance().setChannelNumber(needChannelNumber);
/**
* 通过获取配置信息得到每个taskGroup需要运行哪些tasks任务
*/
//平均分配具体的task到具体的taskGroup
List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,
this.needChannelNumber, channelsPerTaskGroup);
...
这里是根据task和配置的并发数量,确定taskGroup的数量。assignFairly方法就是执行具体的分配策略,核心的分配源码是:
for (int i = 0; i < mapValueMaxLength; i++)
for (String resourceMark : resourceMarks)
if (resourceMarkAndTaskIdMap.get(resourceMark).size() > 0)
int taskId = resourceMarkAndTaskIdMap.get(resourceMark).get(0);
taskGroupConfigList.get(taskGroupIndex % taskGroupNumber).add(contentConfig.get(taskId));
taskGroupIndex++;
resourceMarkAndTaskIdMap.get(resourceMark).remove(0);
最终实现的效果就是,
/**
* /**
* 假如:
* <pre>
* a 库上有表:0, 1, 2
* a 库上有表:3, 4
* c 库上有表:5, 6, 7
*
* 如果有 4个 taskGroup
* 则 assign 后的结果为:
* taskGroup-0: 0, 4,
* taskGroup-1: 3, 6,
* taskGroup-2: 5, 2,
* taskGroup-3: 1, 7
*
* </pre>
*/
完成任务分配后我们就需要根据运行模式决定调度器,这里的运行模式我现在看的3.0版本只有一种了:
executeMode = ExecuteMode.STANDALONE;
scheduler = initStandaloneScheduler(this.configuration);
initStandaloneScheduler方法生成了一个StandAloneScheduler的调度器实例,同时初始化了JobContainerCommunicator类,这个类的作用是用来在任务执行过程中共享一些通讯的参数,比如配置,任务执行的状态上报等。
然后就可以启动任务了,
scheduler.schedule(taskGroupConfigs);
该方法主要是调用父类AbstractScheduler的startAllTaskGroup方法,来完成taskGroup的启动,
@Override
public void startAllTaskGroup(List<Configuration> configurations)
//启动一个线程池,大小为taskGroup的数量
this.taskGroupContainerExecutorService = Executors
.newFixedThreadPool(configurations.size());
for (Configuration taskGroupConfiguration : configurations)
//就是一个runner而已,无它
TaskGroupContainerRunner taskGroupContainerRunner = newTaskGroupContainerRunner(taskGroupConfiguration);
this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);
this.taskGroupContainerExecutorService.shutdown();
这里可以看到,分配了一个线程池,线程池的大小就是taskGroup的数量,也就是一个线程处理一个taskGroup。任务的具体逻辑在TaskGroupContainerRunner中,
@Override
public void run()
try
Thread.currentThread().setName(
String.format("taskGroup-%d", this.taskGroupContainer.getTaskGroupId()));
//每个线程里面,其实是启动了一个taskGroupContainer,用来运行一个taskGroup的全部任务
this.taskGroupContainer.start();
this.state = State.SUCCEEDED;
catch (Throwable e)
this.state = State.FAILED;
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
TaskGroupContainerRunner 线程启动后,会启动TaskGroupContainer的start方法来运行一个taskgroup里的全部任务,start方法比较长,这里只分析一些关键的逻辑。
首先有几个队列,分别存放不同状态的任务:
Map<Integer, Configuration> taskConfigMap = buildTaskConfigMap(taskConfigs); //taskId与task配置
List<Configuration> taskQueue = buildRemainTasks(taskConfigs); //待运行task列表
Map<Integer, TaskExecutor> taskFailedExecutorMap = new HashMap<Integer, TaskExecutor>(); //taskId与上次失败实例
List<TaskExecutor> runTasks = new ArrayList<TaskExecutor>(channelNumber); //正在运行task
Map<Integer, Long> taskStartTimeMap = new HashMap<Integer, Long>(); //任务开始时间
对于taskGroup中的每个待执行的任务,分配一个TaskExecutor实例执行任务,
Iterator<Configuration> iterator = taskQueue.iterator();
while(iterator.hasNext() && runTasks.size() < channelNumber)
Configuration taskConfig = iterator.next();
Integer taskId = taskConfig.getInt(CoreConstant.TASK_ID);
....
Configuration taskConfigForRun = taskMaxRetryTimes > 1 ? taskConfig.clone() : taskConfig;
TaskExecutor taskExecutor = new TaskExecutor(taskConfigForRun, attemptCount);
taskStartTimeMap.put(taskId, System.currentTimeMillis());
//开始执行任务
taskExecutor.doStart();
iterator.remove();
//添加到正在执行的任务列表
runTasks.add(taskExecutor);
总结下start方法做的事情:
- 初始化task执行相关的状态信息,分别是taskId与其对应的Congifuration的map映射集合、待运行的任务队列taskQueue、运行失败任务taskFailedExecutorMap、正在执行的任务集合runTasks等
- 进入循环,循环判断各个任务执行的状态:
- 判断是否有失败的task,如果有则放入taskFailedExecutorMap中,并查看当前的执行是否支持重跑和failOver,如果支持则重新放回执行队列中;如果没有失败,则标记任务执行成功,并从状态轮询map中移除
- 如果发现有失败的任务,则向容器汇报状态,抛出异常
- 查看当前执行队列的长度,如果发现执行队列还有通道,则构建TaskExecutor加入执行队列,并从待运行移除
- 检查执行队列和所有的任务状态,如果所有的任务都执行成功,则汇报taskGroup的状态并从循环中退出
- 检查当前时间是否超过汇报时间,如果超过了,就需要向全局汇报当前状态
- 所有任务成功之后,向全局汇报当前的任务状态。
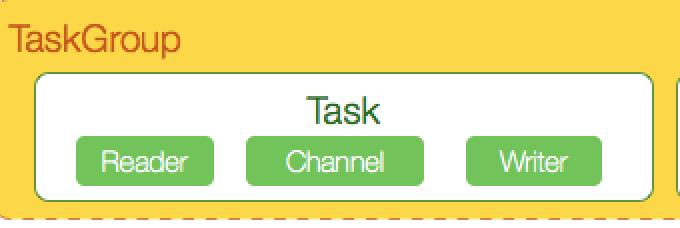
上面提到TaskExecutor,它是TaskGroupContainer的内部类,是一个基本单位task的具体执行管理的地方。看下它的成员就能窥探一二:
class TaskExecutor
private Configuration taskConfig;
private int taskId;
private int attemptCount;
private Channel channel;
private Thread readerThread;
private Thread writerThread;
private ReaderRunner readerRunner;
private WriterRunner writerRunner;
...
它包含一个reader线程,工作是把从数据库中读出来的每条数据封装为一个个Record放入Channel中。包含一个writer线程,不断从Channel中读取Record。
参考:
- https://juejin.cn/post/7006619232641220616
- gitgithub.com/alibaba/DataX/blob/master/introduction.md
以上是关于datax源码解析-任务调度机制解析的主要内容,如果未能解决你的问题,请参考以下文章