AQE中的CoalesceShufflePartitions和OptimizeLocalShuffleReader
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AQE中的CoalesceShufflePartitions和OptimizeLocalShuffleReader相关的知识,希望对你有一定的参考价值。
背景
本文基于spark 3.1.2
在之前的文章spark CTAS nuion all (union all的个数很多)导致超过spark.driver.maxResultSize配置(2G)里我们说到,在AQE开启,且在分区合并初始化分区设置为1000的情况下,为什么了在开启了分区合并和优化本地化shuffle读取的前提下,还是会导致分区很大
默认情况下,分区合并和本地化shuffle都是开启的。且我们这里是AQE下SortMergeJoin转BroadcastHashJoin
划重点说结论
CoalesceShufflePartitions 做的分区合并,reduce端的任务会减少
OptimizeLocalShuffleReader 做的本地读取化,是合并map task任务产生的分区.
听不懂!,下文中我会用图解来给你做解释
分析以及解释
我们以最小的demo来做解释,直接上sql,运行以下sql:
SELECT a1.order_no
,a1.need_column
,a1.join_id
FROM temp.actul_a a1
join temp.actul_a a2 on a1.join_id = a2.join_id and a2.need_column = 'we need it'
WHERE a1.need_column ='others needs it'
只分区合并,不做本地化读取
设置一下参数:
set spark.sql.adaptive.localShuffleReader.enabled=false;
运行的的物理计划,如下:
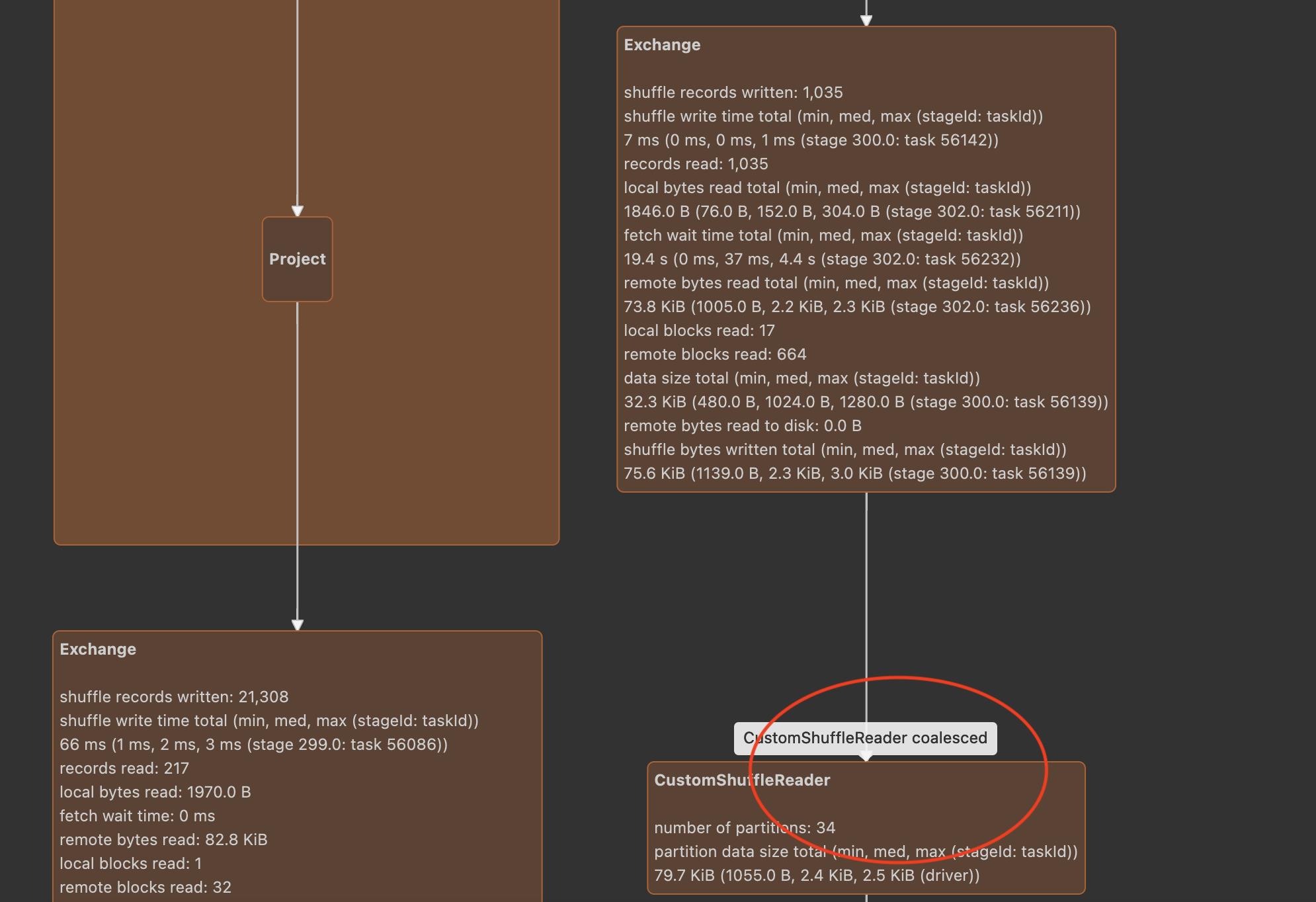
原本shuffle完之后为1000分区的,在经过了分区合并以后直接变成了34个分区,
且分区customerShuffleReader 的标识为coalesced
这说明在分区合并的情况下分区数是大量减少了
既分区合并又优化本地化读取
set spark.sql.adaptive.coalescePartitions.enabled=true;
set spark.sql.adaptive.localShuffleReader.enabled=true;
这两个参数默认都是true,在此设置一下只是为了强调开启这两个参数
运行的物理计划,如下:
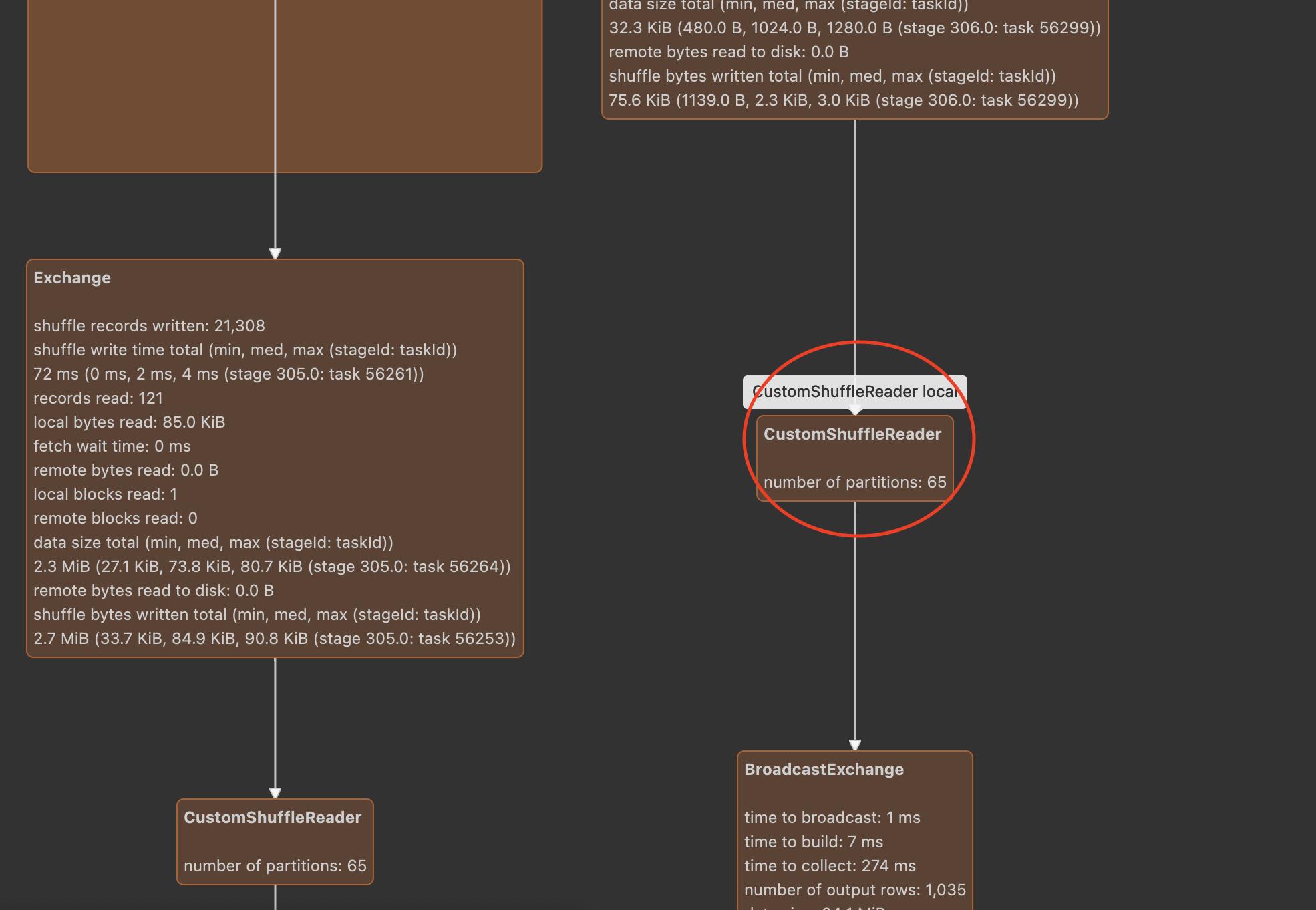
可以看到在经过分区合并和以及本地读取优化以后,直接变成了65个分区,比没有经过本地读取优化多出了一半的分区
不经过分区合并,只本地优化读取
set spark.sql.adaptive.coalescePartitions.enabled=false;
注意,此条件设置完之后,shuffle后的分区数回到了400(我们默认的spark.sql.shuffle.partitions为400)
运行的物理计划如下:
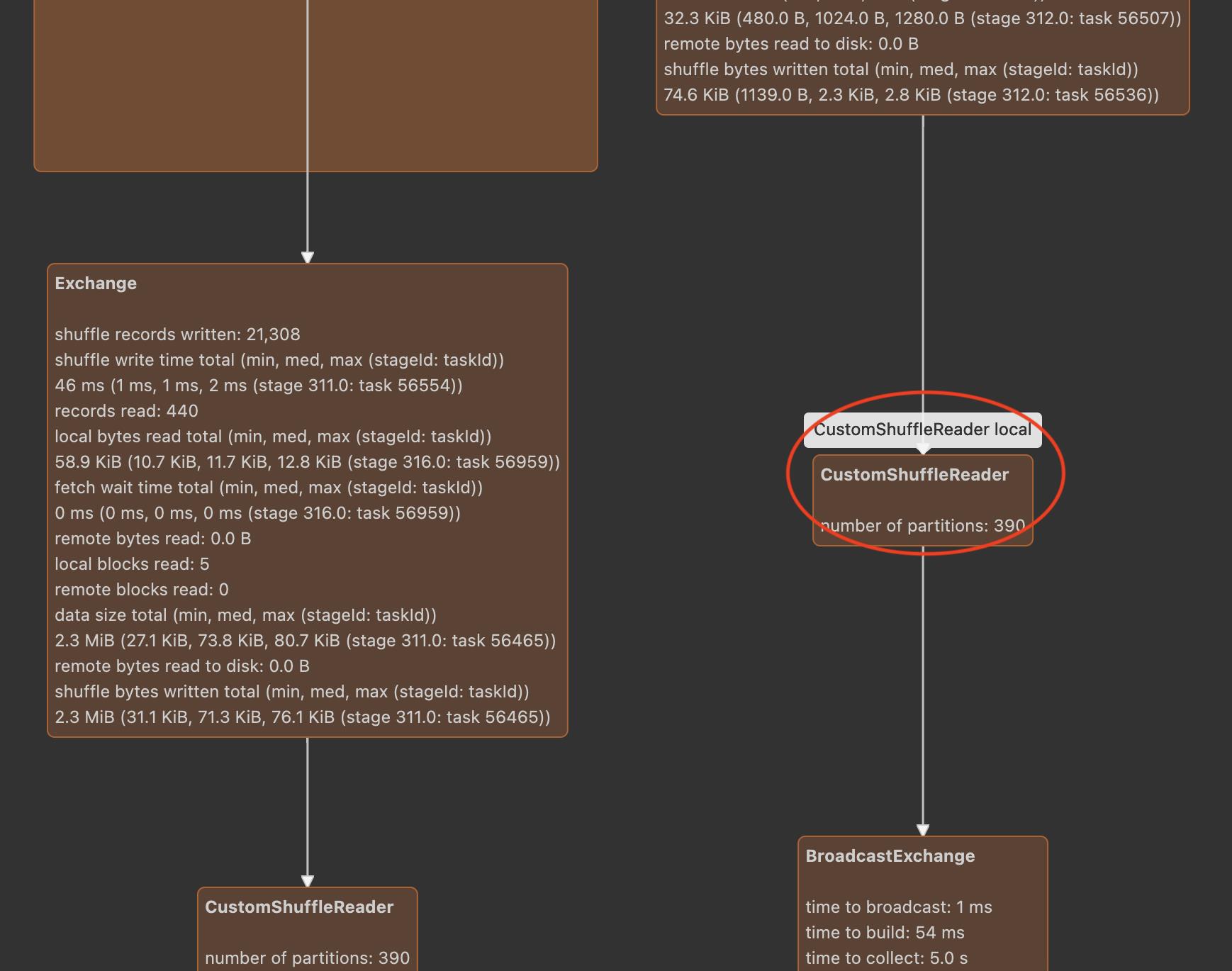
可以看到在只有本地读取优化之后,分区直接变成了395个,和shuffle后的分区数400 没有差多少。
但是为什么合并分区和本地化优化的分区数不一样?他们到底是怎么做的呢?
为什么合并分区和本地化优化的分区数不一样
解释一下:
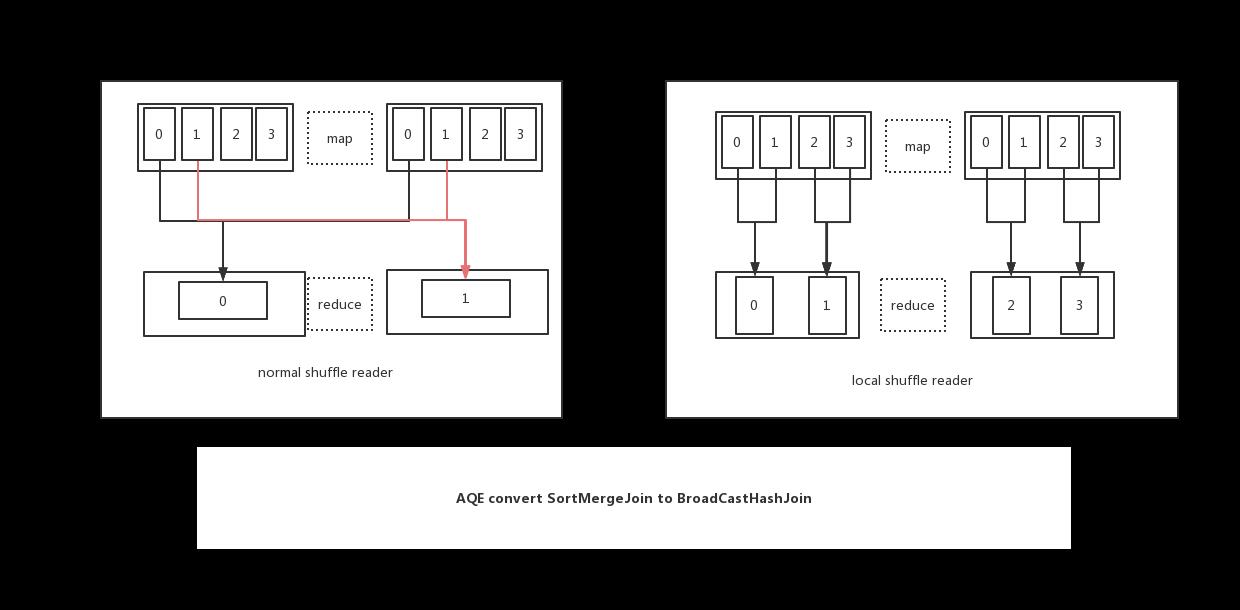
- 从逻辑上:
CoalesceShufflePartitions是把shuffle后的结果集中的各个分区(也是reduce task)定义了一种合并规则,这样在拉取数据的时候,就会按照之前合并的规则来拉取数据
OptimizeLocalShuffleReader也是把shuffle后的结果集中的各个分区定义了一种合并规则,只不过这个规则定义是在一个map task级别,也就是说是定了map任务产生的reduce分区之间的合并
定义好了合并规则以后,就会按照规则执行,如图:
- 从代码上:
CoalesceShufflePartitions的代码在spark 3.0.1 AQE(Adaptive Query Exection)分析有说过,这里不复赘.
我们着重分析一下OptimizeLocalShuffleReader :private def createLocalReader(plan: SparkPlan): CustomShuffleReaderExec = plan match case c @ CustomShuffleReaderExec(s: ShuffleQueryStageExec, _) => CustomShuffleReaderExec(s, getPartitionSpecs(s, Some(c.partitionSpecs.length))) case s: ShuffleQueryStageExec => CustomShuffleReaderExec(s, getPartitionSpecs(s, None)) // TODO: this method assumes all shuffle blocks are the same data size. We should calculate the // partition start indices based on block size to avoid data skew. private def getPartitionSpecs( shuffleStage: ShuffleQueryStageExec, advisoryParallelism: Option[Int]): Seq[ShufflePartitionSpec] = val numMappers = shuffleStage.shuffle.numMappers val numReducers = shuffleStage.shuffle.numPartitions val expectedParallelism = advisoryParallelism.getOrElse(numReducers) val splitPoints = if (numMappers == 0) Seq.empty else equallyDivide(numReducers, math.max(1, expectedParallelism / numMappers)) (0 until numMappers).flatMap mapIndex => (splitPoints :+ numReducers).sliding(2).map case Seq(start, end) => PartialMapperPartitionSpec(mapIndex, start, end)
主要是在getPartitionSpecs这个方法里,PartialMapperPartitionSpec是重点在以下的分析中会用到,这个方法主要就是进行分区规则设定的核心,看不懂?
核心代码拷贝过来,放在IDE中运行:
val numMappers = 33
val numReducers = 400
val expectedParallelism = numReducers
val splitPoints = if (numMappers == 0)
Seq.empty
else
equallyDivide(numReducers, math.max(1, expectedParallelism / numMappers))
val partitionSpecs = (0 until numMappers).flatMap mapIndex =>
(splitPoints :+ numReducers).sliding(2).map
case Seq(start, end) => (mapIndex, start, end)
println(s"splitPoints: $splitPoints")
println(s"splitPoints.length: $splitPoints.length")
println(s"partitionSpecs: $partitionSpecs")
println(s"partitionSpecs.length: $partitionSpecs.length")
---结果---
splitPoints: Vector(0, 34, 68, 102, 136, 169, 202, 235, 268, 301, 334, 367)
splitPoints.length: 12
partitionSpecs: Vector((0,0,34), (0,34,68), (0,68,102), (0,102,136), (0,136,169), (0,169,202), (0,202,235), (0,235,268), (0,268,301), (0,301,334), (0,334,367), (0,367,400), (1,0,34), (1,34,68), (1,68,102), (1,102,136), (1,136,169), (1,169,202), (1,202,235), (1,235,268), (1,268,301), (1,301,334), (1,334,367), (1,367,400), (2,0,34)。。。
partitionSpecs.length: 396
其中splitPoints就是设定一个map任务产生的reduce任务的分区规则,如:0,34,68代表0到33个分区(左闭右开)作为一个分区来读取,34到67作为一个分区来读取。
partitionSpecs就是具体设定一个map任务产生的哪几个分区的读取规则,如:(0,0,34) 索引为0的maptask产生的0到33个分区 由一个任务来读取。
那这种规则读取,spark是怎么实现的?我们直接定位到CustomShuffleReaderExec.scala:
private lazy val shuffleRDD: RDD[_] =
shuffleStage match
case Some(stage) =>
sendDriverMetrics()
stage.shuffle.getShuffleRDD(partitionSpecs.toArray)
case _ =>
throw new IllegalStateException("operating on canonicalized plan")
override protected def doExecute(): RDD[InternalRow] =
shuffleRDD.asInstanceOf[RDD[InternalRow]]
我们可以看到在driver生成RDD的时候,会间接的调用到stage.shuffle.getShuffleRDD(partitionSpecs.toArray) 这个方法,
该方法在构造RDD的时候会把分区读取定义规则给作为参数传递进去,而这个方法在ShuffleExchangeExec的实现为:
override def getShuffleRDD(partitionSpecs: Array[ShufflePartitionSpec]): RDD[InternalRow] =
new ShuffledRowRDD(shuffleDependency, readMetrics, partitionSpecs)
而在ShuffledRowRDD中的两个方法:
override def getPartitions: Array[Partition] =
Array.tabulate[Partition](partitionSpecs.length) i =>
ShuffledRowRDDPartition(i, partitionSpecs(i))
override def compute(split: Partition, context: TaskContext): Iterator[InternalRow] =
val tempMetrics = context.taskMetrics().createTempShuffleReadMetrics()
// `SQLShuffleReadMetricsReporter` will update its own metrics for SQL exchange operator,
// as well as the `tempMetrics` for basic shuffle metrics.
val sqlMetricsReporter = new SQLShuffleReadMetricsReporter(tempMetrics, metrics)
val reader = split.asInstanceOf[ShuffledRowRDDPartition].spec match
case CoalescedPartitionSpec(startReducerIndex, endReducerIndex) =>
SparkEnv.get.shuffleManager.getReader(
dependency.shuffleHandle,
startReducerIndex,
endReducerIndex,
context,
sqlMetricsReporter)
case PartialReducerPartitionSpec(reducerIndex, startMapIndex, endMapIndex, _) =>
SparkEnv.get.shuffleManager.getReader(
dependency.shuffleHandle,
startMapIndex,
endMapIndex,
reducerIndex,
reducerIndex + 1,
context,
sqlMetricsReporter)
case PartialMapperPartitionSpec(mapIndex, startReducerIndex, endReducerIndex) =>
SparkEnv.get.shuffleManager.getReader(
dependency.shuffleHandle,
mapIndex,
mapIndex + 1,
startReducerIndex,
endReducerIndex,
context,
sqlMetricsReporter)
reader.read().asInstanceOf[Iterator[Product2[Int, InternalRow]]].map(_._2)
其中getPartitions 这个方法会在计算的时候被触发,ShuffledRowRDDPartition(i, partitionSpecs(i)) 这个就是我们要读取的每一个分区,
compute就是shuffle计算的逻辑,会根据不同的规则,触发不同的case,
对应到CoalesceShufflePartitions就是CoalescedPartitionSpec.
对应到OptimizeLocalShuffleReader就是PartialMapperPartitionSpec,但是在spark 3.1.2版本的时候,还是存在一点不足,
优化完之后并不是读取多个map task产生的分区,这个在SPARK-36105中进行了补充。
为什么叫做OptimizeLocalShuffleReader
经过以上分析,物理计划在进行了OptimizeLocalShuffleReader规则之后,会产生分区读取规则,而这种分区读取规则是定义在map task产生的分区上的,
而DAGScheduler在进行任务调度的时候,会根据任务的亲和性(尽可能保证reduce任务能够跑到上游的map任务的所在的同一个executor上)来进行调度,
这样在shuffle 数据的读取阶段,针对于读取一个map task多个分区的情况来说是有很好的网络传输优化的。
具体的代码是在ShuffledRowRDD.scala:
override def getPreferredLocations(partition: Partition): Seq[String] =
val tracker = SparkEnv.get.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster]
partition.asInstanceOf[ShuffledRowRDDPartition].spec match
case CoalescedPartitionSpec(startReducerIndex, endReducerIndex) =>
// TODO order by partition size.
startReducerIndex.until(endReducerIndex).flatMap reducerIndex =>
tracker.getPreferredLocationsForShuffle(dependency, reducerIndex)
case PartialReducerPartitionSpec(_, startMapIndex, endMapIndex, _) =>
tracker.getMapLocation(dependency, startMapIndex, endMapIndex)
case PartialMapperPartitionSpec(mapIndex, _, _) =>
tracker.getMapLocation(dependency, mapIndex, mapIndex + 1)
当然也可以参考这边篇what-new-apache-spark-3-local-shuffle-reader加深对LocalShuffleReader的理解
以上是关于AQE中的CoalesceShufflePartitions和OptimizeLocalShuffleReader的主要内容,如果未能解决你的问题,请参考以下文章
Spark3 AQE (Adaptive Query Execution) 一文搞懂 新特性
阿里云RemoteShuffleService 新功能:AQE 和流控