[人工智能-深度学习-63]:生成对抗网络GAN - 图片创作:普通GAN, pix2pix, CycleGAN和pix2pixHD的演变过程
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-63]:生成对抗网络GAN - 图片创作:普通GAN, pix2pix, CycleGAN和pix2pixHD的演变过程相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122015783
目录
第2章 基于深度学习DNN的计算机视觉的基本原理(图像的判定)
第3章 常规生成对抗网络GAN的基本原理(不受控的图像的生成)
第4章 pix2pix网络的基本原理(“形似”受控的图像生成、创作)
第5章 CycleGAN的原理(“神似”受控的图像生成、创作)
第1章 传统计算机视觉基本原理(图像的建模)
1.1 传统的计算机视觉
在2012年之前,CV的主要研究方法是使用人工设计(hand-designed)的图像特征来完成各种任务(见下图)。

1.2 不足
这些特征都是人为预设的,图像的处理基于这些预设的特征,如颜色特征、外形特征等等。人为特征的最大缺陷是:不同场合的特征不一样,不同场景,需要建立不同的模型,适应性差。
传统的图形学管线(pipeline)中,输出图像需要经过建模、材质贴图、光照、渲染等一系列繁琐的步骤。

第2章 基于深度学习DNN的计算机视觉的基本原理(图像的判定)
2.1 基于深度学习的计算机视觉DNN
2012年,随着使用深度神经网络(Deep Neural Network, DNN) 在ImageNet的分类任务上取得了巨大成功,图像处理的任务由认为构建图像特征发展成,机器自己发现图像的特征。
如下图所示,DeepNet能够自动发现输入图像(RGB通道的像素),并根据发现的特征,完成某种任务。这些DNN包括:全连接网络、卷积网络CNN、时序网络RNN/LSTM.
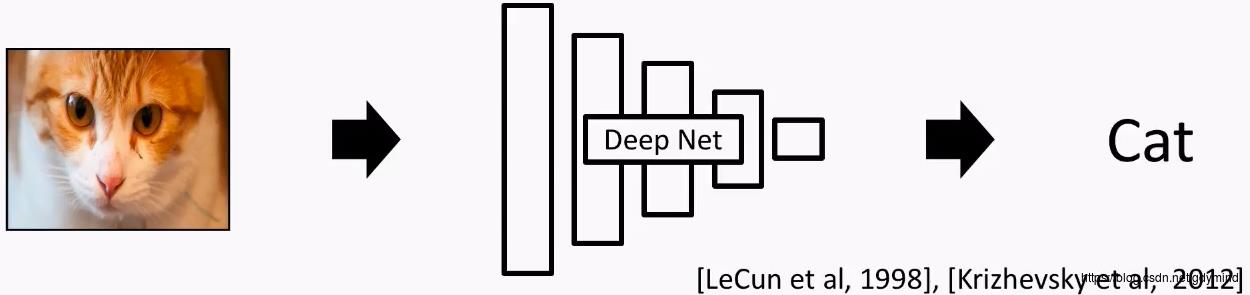
基于网络自动发现的图像特征, 可以完成的任务包括(不限于)
(1)物体识别(Object detection) [Redmon etal., 2018]
(2)对人体肢体的理解(Human understanding) [Guler et al., 2018]
(3)自动驾驶(Autonomous driving) [Zhao et al., 2017]

2.2 DNN的不足
之前的DNN可能是输入一幅图像,输出一个标签(比如说猫),那我们能不能输入“猫”这个字,输出一张猫的照片呢?

很遗憾,答案是No!
因为这种任务实在太复杂啦!
我们很难让DNN凭空输出图像这样的高维数据(High dimensional data)(这里的“高维”可以理解成数据量大)。
实际上,在很长一段时间里,DNN只能输出数字这种简单的、低分别率的小图像,就像下面这样:

而想要生成想游戏场景这类的图片,DNN这种方法根本没用。
第3章 常规生成对抗网络GAN的基本原理(不受控的图像的生成)
3.1 常规生成对抗网络GAN
2014年,一个叫做生成对抗网络(Generative Adversarial Network)——也就是大名鼎鼎的GAN——的东西横空出世。作者是下面这位小哥和他的小伙伴们:






至此,GAN网络可以自己输出多维度的图片数据了。
图像数据具备了真实图片集的公共特征。
生成的高纬度的图像数据会骗过网络的判决器,被判定为真实的图片。
3.2 生成对抗网络的创作本质

GAN网络输出的创作图片,与输入图片无关
输入:可以是任意的随机数。
输出:与训练集上的真实图片具备相同的特征,但具体是什么样子的,什么尺寸,不受控制。
3.3 生成对抗网络的不足
生成对抗网络虽然能生成高维的图像,该图片与参与网络训练的高纬度的真实图片,具备相同的特征。比如,自动生成人像图像或其它相关的图像。
但图像的生成或输出,与输入之间实际上并没有明显的语义上的对应关系。
(1)输出的图片没有用户控制(user control)能力
在传统的GAN里,输入一个随机噪声,就会输出一幅随机图像。随机图像能够骗过判决网络,具备与真实图片相同的特征。

但用户是有想法滴,如果我们想输出的图像是我们想要的那种图像,和我们的输入是对应的、有关联的。比如输入一只喵的草图,输出同一形态的喵的真实图片(这里对形态的要求就是一种用户控制)。

GAN网络是做不到的,GAN网络无法根据指定的图片,输出与输入有结构上关联的图片。
(2)低分辨率(Low resolution)和低质量(Low quality)问题
尽管生成的图片看起来很不错,但如果你放大看,就会发现细节相当模糊。

3.4 GAN网络的改善的目标
前面说过传统的GAN的种种局限,那么现在,我们相应的目标就是:
- 提高GAN的用户控制能力
- 提高GAN生成图片的分辨率和质量
为了达到这样的目标,和把大象装到冰箱里一样,总共分三步:

(0)GAN: 给定一个随机数,可以输出一个具备真实图片(训练数据集)特征的图片。
(1)pix2pix:有条件地使用用户输入,它使用成对的数据(paired data)进行训练。
(2)CycleGAN:使用不成对的数据(unpaired data)的就能训练。
(3)pix2pixHD:生成高分辨率、高质量的图像。
第4章 pix2pix网络的基本原理(“形似”受控的图像生成、创作)
4.1 pix2pix网络的目标
这种方法,就是在训练的时候,就告诉网络,输入图片与输出图片具备某种对应关系,对GAN网络进行限制,而不是像GAN网络进行任意的输出符合真实图片特征的图片。
也就是说,pix2pix网络在学习真实图片的同时,与能够学习到,该真实图片来源什么的输入图片。
pix2pix对传统的GAN做了个小改动,它不再输入随机噪声,而是输入用户给定图片,输出与输入有结构对应关系的图片。

4.2 pix2pix的问题
(1)情形1: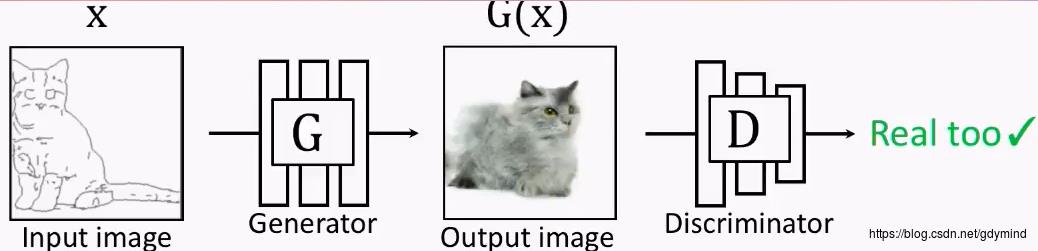
如果G网络的输出是下面这样的,D网络拿来一看,也会认为是真的图片。
这种输出它的图片满足GAN网络的要求。
(2) 情形2:

如果G网络的输出如果是下面这样,D网络会判断是真图:
这种输出它的图片也满足GAN网络的要求。
如何确保,输入图片X, 只输出情形2的图片呢?而不是情形1的图片呢?
4.3 怎样建立输入和输出的对应关系呢?
为了体现这种对应关系,解决方案也很简单:
我们把G网络的输入和输出一起作为D的输入,D网络的判决时,不仅仅根据G网络的输出进行决,还根据G网络的输出进行判决,只有G网络的输出与G网络的输出具备对应关系,D网络才认为G网络输出的图片是期望的图片,如下图所示:
(1)情形1:输出与输入一致的情形

下列条件只有同时得到满足,输出图片才会被判为真:
- 满足GAN网络的判决条件,即输出满足真实图片的特征。
- 输出图片与输入图片相似,即实现了输入对输出的控制
(2)情形2:输出与输入不一致的情形

下列条件只要有一个不满足,输出图片就被判为假:
- 满足GAN网络的判决条件,即输出满足真实图片的特征;否则,输出图片不满足期望的真实图片的特征。
- 输出图片与输入图片相似,即实现了输入对输出的控制;否则,输出图片与输入图片没有关系,不是由输入图片产生的,而是随机产生的。
4.4 pix2pix名称的由来
pix2pix通过增加判决网络对输出与输入图片的相似性检查,确保输出的图片,与输入图片有明确的对应关系来达到输入对输出的控制。
现在的问题来了:如何检查输出与输入图片的相似性呢?
(1)pix2pix的做法
pix2pix通过把输出图片与输入图片的每个像素点的距离和作为loss,来判断两个图片的相似性的,
loss越小,相识度越高。
pix2pix并没有通过增加什么新的网络,来确保输出与输入的相似性关系。
这就是pix2pix的由来!
由于pix2pix对相似性检查和保证,是直接通过像素到像素进行检查的完成的,因此pix2pix的输出与输入是显性的、表象的、强关联关系,属于“形似”。
4.5 pix2pix创作的本质

pix2pix能够确保输出图片与输入图片有一定的关联。或者说,给定一个输入图片,输出的图片,除了满足真实图片的特征,还能体现、保留输入图片原有的信息。
pix2pix是通过数据集,而不是神经网络结构,来保证输出与输入关系的!
因此pix2pix网络,需要成对的数据集(paired数据集)。
4.5 pix2pix的应用
pix2pix的这项研究还是挺成功的,大家可以去这里线体验一下demo,它能把草图(sketch)变成图片。
这里 https://affinelayer.com/pixsrv/
https://affinelayer.com/pixsrv/
(1)草图变图片[Isola, Zhu, Zhou, Efros, 2016]:

(2) 灰度图变彩色图[Isola, Zhu, Zhou, Efros, 2016]:

(3)自动着色 Data from [Russakovsky et al. 2015]:

(4)交互式着色[Zhang*, Zhu*, Isola, Geng, Lin, Yu, Efros, 2017]:

4.7 pix2pix创作的限制或不足
(1)对数据集的要求较高
在训练时,需要人为的指定参照图片与真实的输出图片的成对的对应关系(paired)。
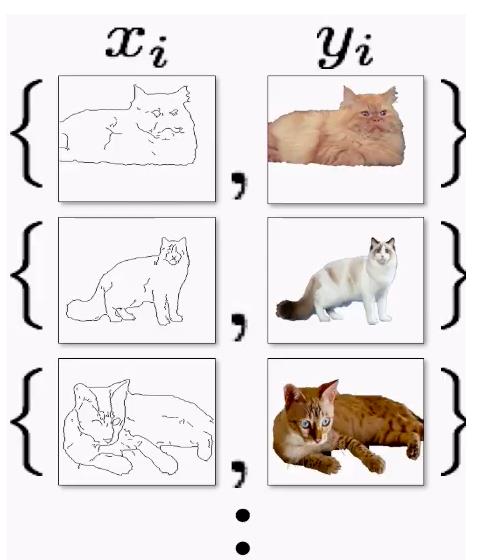
只有这样,pix2pix网络才能按照期望的方式,对输入图片进行创作,而不是对输入普通进行任意的创作(GAN网络就是属于任意创作)!!!
(2)输出的创作图片的内容受限
输出的创作图片,完全受限于输入图片,输出内容(轮廓)与输入图片完全一样,不同的仅仅是输出图片的填充信息。
第5章 CycleGAN的原理(“神似”受控的图像生成、创作)
5.1 CycleGAN网络的动机与要解决的问题
pix2pix必须使用成对的数据进行训练,很多情况下成对数据是很难获取到的,比如说,我们想把马变成斑马,现实生活中是不存在对应的真实照片的。

Cycle-constraint Adversarial Network也就是CycleGAN解决这个问题。
这种网络不需要成对的数据(称为unpaired数据集),只需要输入数据的一个集合(比如一堆马的照片)和输出数据的一个集合(比如一堆斑马的照片)就可以了。如下图所示:
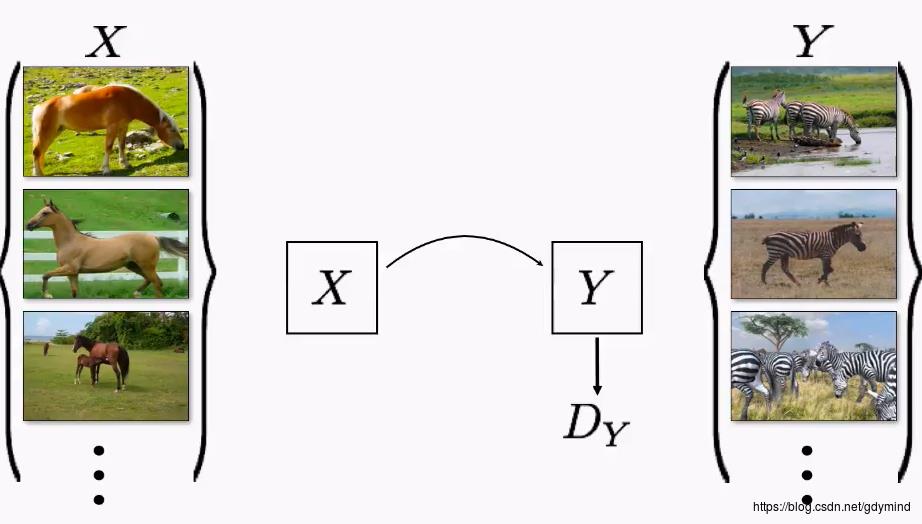
CycleGAN网络在不使用paired的数据的情况下,如何亦然能够确保输出与输入有内在的关联,而不是GAN网络的随意创作呢?
5.2 CycleGAN的本质
如果说,pix2pix是通过优化数据集,来保证输出与输入关系的!
那么说,CycleGAN通过优化神经网络的结构,来保证输出与输入关系的!
CycleGAN在GAN的网络结构的基础之上,增加了一个还原网络,用于把输出还原,用还原后的图片的像素与原始的输入像素进行比较,来确保输出与输入的对应关系,生成与还原都是特征提取后的还原,因此输出与输入在形式上不一定完全一致,而是在深层次的特征章保持一致。

5.3 来自于语言翻译的思想启示

(1)语言翻译
如果一把一段话从英文A翻译成中文C,再从中文C翻译回英文B,那么你应该得到跟之前原始输入的英文A一样的内容B。
- 转换后的中文C与原始的英文A或B在“形式”是不一样的,这与pix2pix不一样
- 转换后的中文C与原始的英文A或B在“语义”是一样的,这与pix2pix一样
- 原始的英文A与还原后的英文B在“形式”是一样的,这与pix2pix一样,A和B的相似度越高,说明输出与输入的转换越准确,此时A与C的差异性越大,说明创作性越强。
(2)图片转换
CycleGAN的原理与上述语言翻译基本相似。
先原始输入图片马A变成斑马C,然后再变回马B,那么最后的马B和开始输入的马A应该是一样的。
- 转换后的图片C与原始的图片A或B在“形式”是不一样的,这与pix2pix不一样
- 转换后的图片C与原始的图片A或B在“语义”特征是一样的,这与pix2pix一样
- 原始的图片A与还原后的图片B在“形式”是一样的,这与pix2pix一样,A和B的相似度越高,说明输出与输入的转换越准确,此时A与C的差异性越大,说明创作性越强。
5.4 CycleGAN名称的由来
对输出与输入图片的相似性检查,是确保输出的图片与输入图片有明确的对应关系的重要手段。
现在的问题来了:如何检查输出与输入图片的相似性呢?
(1)pix2pix的做法
pix2pix是直接通过像素到像素进行检查的完成的,因此pix2pix的输出与输入是显性的、表象的、强关联关系,属于“形似”。
(2)CycleGAN的做法
CycleGAN通过增加还原网络,首先把输出图片重新还原成输入图片,然后对输入图片与还原后的图片进行像素到像素的检查,确保输出图片与输入图片的相似性。这个还原的过程就是形成了一个闭环,这 就是“CycleGAN”的由来。
虽然,还远后的图片与输入图片,具备像素到像素的显性的、表象的、强关联关系,属于“形似”。
但输出图片与输入图片以及还原后的图片并非这种“形似”,而是内在特征的关系。
因此,CycleGAN的输出图片与输入图片之间是隐性、内在的、语义关系。
CycleGAN同时具备如下特征:
- 具备GAN网络自由创作的优点
- 具备pix2pix网络,输入对输出进行控制的优点
- 克服pix2pix网络,输出与输入只是“形似”的缺点与不足。
- 具备了输出与输入具备内在特征的相似,得到了“神似”的效果。
5.5 CycleGAN的网络实现
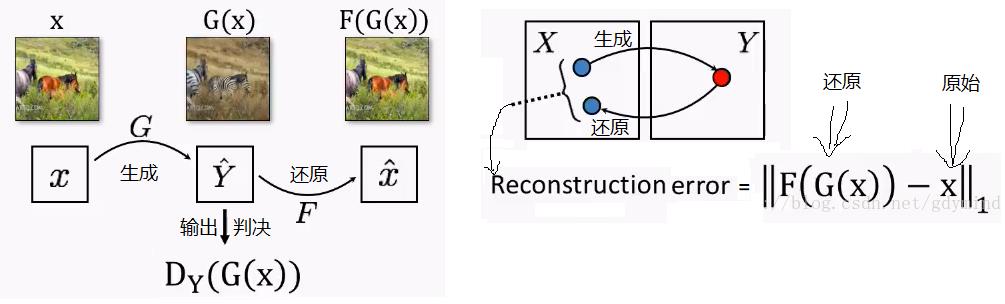
通过对还原图片与原始图片的比较,可以确保生成图片的准确性以及与输入图片的关联性。
5.6 CycleGAN的网络的优化
基本的CycleGAN网络,虽然能够还原成原始图片,但由于输出图片与输入图片之间仅仅是内在特征有一定的相似性,在形态是差异可能很大。如下图所示:

如何保证生成与还原这两个转换不是天马行空,进一步限定输出的准确性。
还需要对训练进行进一步的限制。斑马作为输入,得到普通的马,进一步还原成斑马。
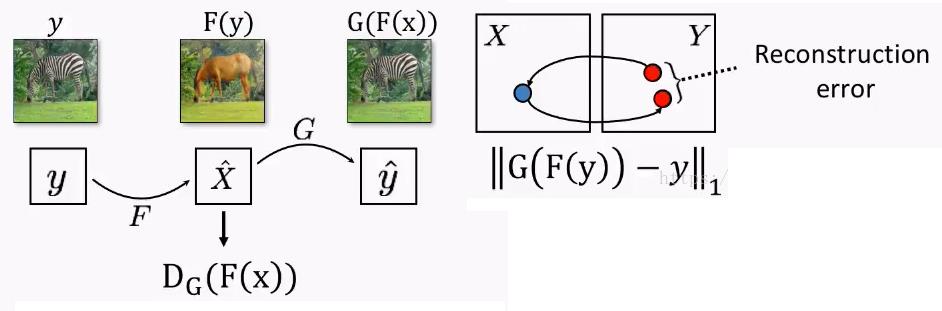
因此,整个CycleGAN经过两次翻译,两次还原:
(1)普通马 =》 斑马 =》 普通马
(2)斑马 =》 普通马 =》 斑马
如果经过上次两次翻译与还原,就能够进一步确保了输出与输入之间的关联性。
类似:
英文 =》 中文 =》 英文
中文 =》 英文 =》 中文
如果两个方向的转换都满足要求的,则证明网络在进行风格转换时,具备了相当强的精确性和创造性 。
CycleGAN成功的原因在于:它分离了风格(Style)和内容(content)。
人工设计这种分离的算法是很难的,但有了神经网络,我们很容易让它学习者去自动保持内容而改变风格。
5.7 CycleGAN网络的应用
(1)马变斑马


(2)橘子变苹果


(3)图像风格的迁移:


(4)游戏场景替换
它以一些德国城市的照片作为输入,成功替换了游戏GTA5中的场景!

(5)其他应用

第6章 pix2pixHD
6.1 pix2pixHD要解决的问题
我们还剩一个悬而未决的问题:分辨率和图像质量。pix2pix的输出图片,其图片的分辨率都不该高,过高分辨率导致训练时间的指数增长,同时也会出现转换不准确。
pix2pixHD就是用来解决这个问题的!
6.2 问题案例
假设我们输入一张高分辨率的草图:

使用pix2pix,结果很差(之前说过,让网络产生高维数据输出很难):

6.3 pix2pixHD的解决方法
pix2pixHD采取了金字塔式的方法(逐渐加强)
(1)先使用GAN或pix2pix输出低分辨率的图片。
(2)将之前输出的低分辨率图片作为另一个新增网络的输入,然后生成分辨率更高的图片。该新增的网络对输出图片进行高分辨率增强,这种方法不影响现有的网络架构,同时增加了新的增强功能。

6.4 效果
给定下面的高分辨率草图:

产生高分辨率的输出:

6.5 主要应用
(1) 比如用草图生成高分辨率人脸:


(2)图像增强(Image Enhancement)
(3)图像去雾(Image Dehazing)
(4)非监督动作重定向Neural Kinematic Networks for Unsupervised Motion Retargetting
参考:
一文读懂GAN, pix2pix, CycleGAN和pix2pixHD_gdymind的博客-CSDN博客_pix2pix
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122015783
以上是关于[人工智能-深度学习-63]:生成对抗网络GAN - 图片创作:普通GAN, pix2pix, CycleGAN和pix2pixHD的演变过程的主要内容,如果未能解决你的问题,请参考以下文章
[人工智能-深度学习-60]:生成对抗网络GAN - 结构化学习Structured Learning
[人工智能-深度学习-59]:生成对抗网络GNN - 基本原理(图解详解通俗易懂)
[人工智能-深度学习-61]:生成对抗网络GAN - 图像融合的基本原理与案例
深度学习与图神经网络核心技术实践应用高级研修班-Day3对抗生成网络(Generative Adversarial Networks)