Java 多线程并发运用:解析单个大文件入库
Posted 多鱼的夏天
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 多线程并发运用:解析单个大文件入库相关的知识,希望对你有一定的参考价值。
背景
上周在博客园看到一篇名为《多线程并发解析单个大文件,1800 万数据 8 线程 5 分钟入库 》的文章,虽然内容全是代码,但全文分析下来还是有所收获的,文中用递归拆分大文件,交由多线程解析的思路值得细究。
“ 如何快速对 1GB 级别的 CSV 文件进行解析并入库?” 这是个不错的话题,记得以前为了查看一个大日志文件,专门下载了 Logviewer 软件才勉强能看,普通文件编辑软件都没办法查看的文件,怎么能高效解析呢?
受此文启发,这里来探究下这个问题。
普通 IO 读取大文件存在的问题
1、编写一个生成指定大小的文件的工具类 BigFileGenerator ,运行它得到一个 2G 的 CSV 文件,文件中的每一行代表一条 web 请求访问信息,结果发现 Java 写文件还是挺快的,运行结果:
total line:22808227
cost :46(s)
2、创建一个工具类 BigFileReader ,编写一个使用 FileInputStream 、按块读、每次读取 64MB 数据的方法 readByBlock ,只读不处理,总耗时 8.6 分钟:
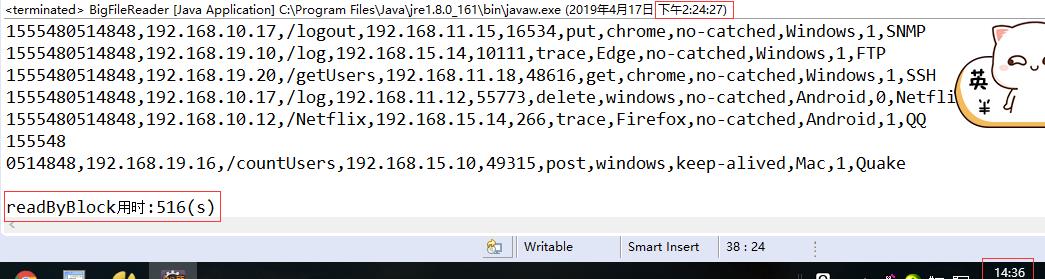
3、编写一个使用 BufferedReader 逐行读取的方法 readByLine,只读数据、不解析,操作总耗时十分半:

4、编写一个使用 BufferedReader 逐行读取、并解析入库的方法 readByLineAndParse,使用 “ mysql 数据库 + InnoDB 引擎 + 自增主键 ”,每次 2000 条 SQL 批量插入,总耗时未测出,半路停止执行:
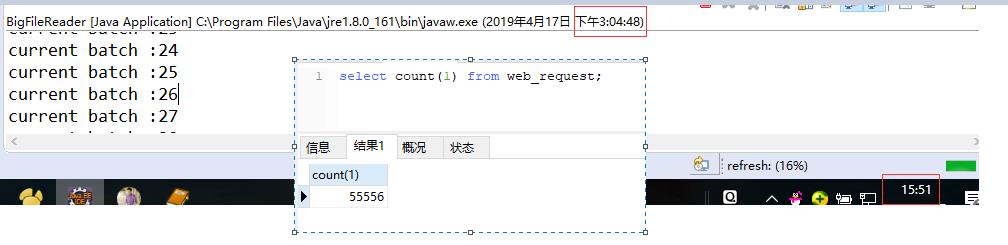
执行了 47 分钟,总共才入库 55 万条记录,总量 2000 多万,照这个速度大约 188 分钟,相当慢。
从测试结果分析,“ 单线程 + 普通 IO ” 解析大文件,存在几点问题:
第一,效率问题,未做任何处理、仅读取操作就相当费时;
第二,定长读取效率比逐行读取高一点,但是无法保证数据的连续性,每次读取 64MB 的数据块,但是不能保证该次读入数据的最后一条是完成的,这不利于数据解析。此外,受限于 JVM 的内存配置,一次不能读取太大的数据到内存中,否则会出现 OOM 异常。
第三,在没有完整测试过内存映射读取方式的效率时,我对普通 IO 读取文件的认识是有偏差的,从后来的测试结果看,使用 BufferedReader 逐行读取的效率也不是很低。
总的来说,我认为大文件解析的瓶颈在于数据库和 OS 资源,多线程解析方案中,读文件操作作采用普通 IO 和内存映射技术都是可以。
Java 多线程解析大文件的基本思路
1、多线程提高解析效率:将大文件切分为 N 小块,每一块交由一个线程去解析,直到所有块都被解析完成。这里涉及文件切分算法和多线程协作控制,稍后将细讲。
2、使用 RandomAccessFile 类对文件进行切分:其 seek 方法可跳到任意位置进行数据读取,文件切分时计算切块 end 位置,再查找其后首次出现的 \\r\\n 的文件指针位置,将其作为切块真正的结束位置,以保证数据完整性。
3、RandomAccessFile 提供了内存文件映射 API ,能够加快大文件的处理效率。
“内存文件映射”是把位于硬盘中的文件看做是程序地址空间中一块区域对应的物理存储器,文件的数据就是这块区域内存中对应的数据,读写文件中的数据,直接对这块区域的地址操作,就可以,减少了内存复制的环节。
内存映射技术和多线程并发解析大文件的实现过程
功能实现类图
这个简单功能的实现大概涉及到几个类,绘制类图如下:

MainControl 中main 方法的执行流程:
- 调用 FilePartitionUtil 的 partition1 方法将大文件切分,得到 N 个 FilePartition 对象;
- 每个 FilePartion 提交给一个 ParseWorker 任务;
- ParseWorker 循环读取 FilePartition 区域中的内容,找到每一行包含 \\r\\n 的记录交给 DataHandler 对象处理;
- DataHandler 以逗号分割每行文本信息,并映射为数据库对应字段,再调用 DBHelper 获取数据库连接后批量入库。
####准备工作
1、利用前面编写的工具类,生成一个 2G 的 CSV 文件,第一行为标题,长度为 95 字节,文件中有效记录总数 2000 多万行。
2、创建测试数据库和数据表,语句为:
CREATE DATABASE bigfile;
use bigfile;
DROP TABLE IF EXISTS `web_request_multiple`;
CREATE TABLE `web_request_multiple` (
`time` bigint(20) DEFAULT NULL,
`src_ip` varchar(15) DEFAULT NULL,
`request_url` varchar(255) DEFAULT NULL,
`dest_ip` varchar(15) DEFAULT NULL,
`dest_port` int(11) DEFAULT NULL,
`method` varchar(32) DEFAULT NULL,
`user_agent` varchar(22) DEFAULT NULL,
`connection` varchar(32) DEFAULT NULL,
`server` varchar(32) DEFAULT NULL,
`status` varchar(20) DEFAULT NULL,
`protocol` varchar(32) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4;
注意:为了提高入库效率,表没有设计主键,数据库引擎选择 MyISAM。最初表设计了自增主键,使用 InnoDB 引擎,结果测了一天多线程入库都没有完成,多线程解析跟单线程解析效率一样低,数据库成了新瓶颈。
调整测试方向后,多线程解析 2G 、二千多万条记录的文件最终耗时二十几分钟,多线程解析大文件总算能体现出优势了。
####第一步,切分大文件
1、需要确定两个信息:文件总字节数和切分个数,二者相除得到每个切分区域的平均长度;初始化 N 个切分区域的信息。
2、程序生成的 CSV 文件的每一行数据都是包含 \\r\\n 的完整记录,所以需要逐个修正切分区域的起始、终止位置信息。
3、修正逻辑:对每个切分区域的 end 信息,往后移动文件指针,直到遇到第一个 \\r\\n 字符为止,此时该切分的 end 信息实际是 “ 初始 end + 移动的位置 + 2(\\r\\n 两个字符)”;下一个切分的位置为 “上一个切分的 end + 1 ”。
网上参考的切分算法都是递归实现的,我觉得递归算法不太好理解,所以按自己的思路实现的,使用两个 for 循环,第一个初始化,第二个修正 ,具体代码为:
/**
* 两个 for 循环完成对大文件的切分
* @param start 文件切分起点位置
* @param splitCount 需要切分的个数
* @param totalSize 文件总长度
* @param randomAccessFile 大文件访问类
* @return
* @throws IOException
*/
public static List<FilePartition> partition1(long start, int splitCount, long totalSize, RandomAccessFile randomAccessFile) throws IOException
if(splitCount<2)
throw new IllegalArgumentException("切分块不能小于 2 ");
//返回结果:所有切分区域信息
List<FilePartition> result = new ArrayList<FilePartition>(splitCount);
//每个切分区域的总长度
long length = totalSize/splitCount;
//初始化切分块信息
for(int i=0;i<splitCount;i++)
//创建一条记录
FilePartition partition = new FilePartition();
//平均切分时每个区域的起止位置:类似分页计算页面起止位置的算法
long currentStart = start+length*i;
//位置是从 0 开始的,所以需要减 1
long currentEnd = currentStart+length-1;
partition.setStart(currentStart);
partition.setEnd(currentEnd<totalSize?currentEnd:totalSize-1);
result.add(partition);
//从第二个切分块开始,修正起、止位置:保证每块的终止位置处是\\r\\n 换行符
long index = result.get(0).getEnd();
for(int i=1;i<splitCount;i++)
//定位到上一个切块的 end 处,往后寻找换行符号
randomAccessFile.seek(index);
byte oneByte = randomAccessFile.readByte();
//判断是否是换行符号,如果不是换行符,那么读取到换行符为止
while(oneByte != '\\n' && oneByte != '\\r')
randomAccessFile.seek(index++);
oneByte = randomAccessFile.readByte();
FilePartition previous = result.get(i-1);
FilePartition current = result.get(i);
//循环结束时,index 此时位于\\r 位置
//此时还差一个 \\n 符号,修正上一个切块的 end 和当前切块的start
previous.setEnd(index+1);
current.setStart(index+2);
//设置下次寻找的位置为当前切块的 end
index = current.getEnd();
return result;
算法的重点在于修正 end 为换行符号所在的位置时,循环结束时文件指针所处的位置是一个 \\r 字符,我们生成的文件每一行都有 \\r\\n ,所以这里修正时多加了一个 \\n 字符的长度。
第二步,设计解析任务
以上是关于Java 多线程并发运用:解析单个大文件入库的主要内容,如果未能解决你的问题,请参考以下文章