Datawhale开源学习:Linux系统基本操作的详细记录
Posted Spuer_Tiger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Datawhale开源学习:Linux系统基本操作的详细记录相关的知识,希望对你有一定的参考价值。
前言
本文作为作者(我)在参与Datawhale开源学习的《Linux系统基本操作》专题学习中的笔记,主要以Terminus终端为例,详细介绍了Linux系统环境下的cmd常规操作命令及其主要用法,还有概念的解释,全文以教程+任务的方式进行(未更新结束.....),相关的课程和任务文档链接在这里->Datawhale Linux组队学习。
文章目录
1.使用命令行登录指定的Linux环境
ssh工具有很多,我们当然选择免费又美观的一款啦,https://blog.csdn.net/puss0/article/details/103390947,可参考这篇博客,这里我们选择的是@cheniie推荐的Termius终端(基础款是免费的,高级版收费,学生免费),软件下载链接点这里!
我选用的是7.27.0.0版本,操作流程如下:
(注:a.尽可能退出校园网,b.第一次打开软件选择continue without account,c.端口号默认22,指定端口除外。)



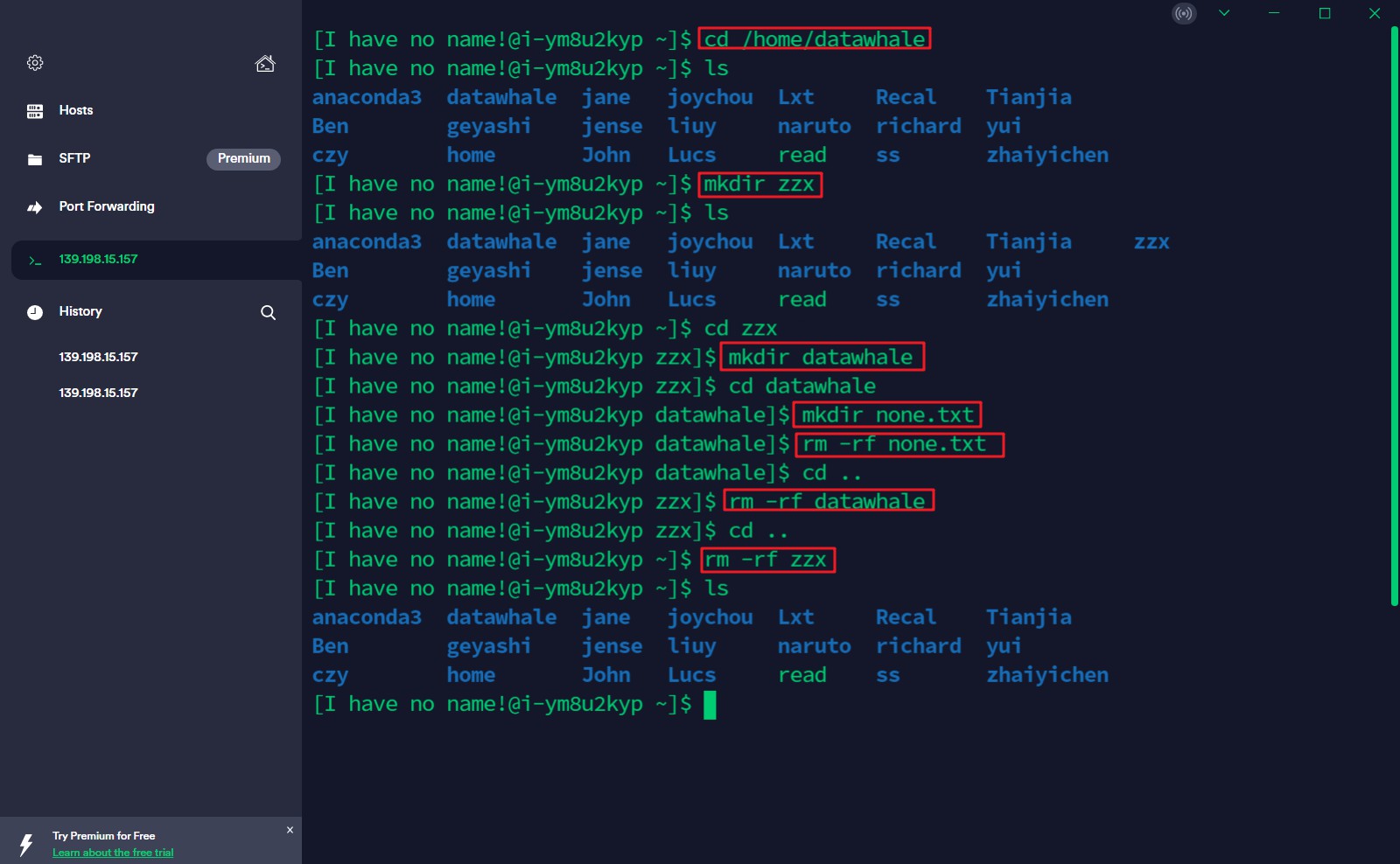
2.在目录下创建文件夹、删除文件夹
首先,了解一下Linux系统主要的目录名称及其功能。
| 目录名称 | 主要功能 |
|---|---|
| /bin | 目录存放着最经常使用的命令。 |
| /boot | 存放的是启动 Linux 时使用的一些核心文件,包括一些连接文件以及镜像文件。 |
| /dev | 该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的 。 |
| /etc | 存放所有的系统管理所需要的配置文件和子目录。 |
| /home | 用户的主目录,在 Linux 中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的。 |
| /lib | 存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。 |
| /media | linux 系统会自动识别一些设备,例如U盘、光驱等等,当识别后,Linux 会把识别的设备挂载到这个目录下。 |
| /opt | 给主机额外安装软件所摆放的目录。 |
| /proc | /proc 是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。 |
| /root | 该目录为系统管理员,也称作超级权限者的用户主目录。 |
| /sbin | 这里存放的是系统管理员使用的系统管理程序。 |
| /srv | 该目录存放一些服务启动之后需要提取的数据。 |
| /tmp | 用来存放一些临时文件的。 |
| /usr | usr 是 unix shared resources(共享资源) 的缩写,这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于 windows 下的 program files 目录。 |
| /var | 存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。 |
| /run | 是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。 |
参考链接:Linux 系统目录结构
然后,让我们一起学习一下Linux系统下的基本操作命令吧!当不知道如何使用该命令时,使用"man 命令",即可。
| Linux处理目录的常用命令 | 解释 | 参数选择 |
|---|---|---|
| ls | “ list files”, 列出目录及文件名。 | -a :全部的文件,连同隐藏文件( 开头为 . 的文件) 一起列出来; -d :仅列出目录本身,而不是列出目录内的文件数据; -l :长数据串列出,包含文件的属性与权限等等数据。 |
| cd | “ change directory”, 切换目录。 | ~:表示回到自己的家目录;… :表示去到目前的上一级目录;./runoob(文件夹名称)/:使用相对路径切换到 runoob 目录;/root/runoob(文件夹名称)/:使用绝对路径切换到 runoob 目录。 |
| pwd | “ print work directory”, 显示目前的目录。 | -P :显示出确实的路径,而非使用连结 (link) 路径。 |
| mkdir | “ make directory ”: 创建一个新的目录。 | -m :配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的脸色~; -p :帮助你直接将所需要的目录(包含上一级目录)递归创建起来, 可以自行帮你创建多层目录。 |
| rmdir | “ remove directory ”: 删除一个空的目录。 | -p : 从该目录起,一次删除多级空目录。 |
| cp | “ copy file ”: 复制文件或目录。 | -p: 连同文件的属性一起复制过去,而非使用默认属性(备份常用); -i: 若目标档(destination)已经存在时,在覆盖时会先询问动作的进行(常用); -r: 递归持续复制,用於目录的复制行为(常用); -s: 复制成为符号连结档 (symbolic link),亦即『捷径』文件(常用)。 |
| rm | “ remove ”: 删除文件或目录。 | -f :就是 force 的意思,忽略不存在的文件,不会出现警告信息; -i :互动模式,在删除前会询问使用者是否动作; -r :递归删除啊!最常用在目录的删除了!这是非常危险的选项!!! |
| mv | “ move file ”: 移动文件与目录,或修改文件与目录的名称。 | -f :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖; -i :若目标文件 (destination) 已经存在时,就会询问是否覆盖; -u :若目标文件已经存在,且 source 比较新,才会升级 (update)。 |
| Linux 文件内容查看的常用命令 | 解释 |
|---|---|
| cat | 由第一行开始显示文件内容 |
| tac | 从最后一行开始显示,可以看出 tac 是 cat 的倒着写! |
| nl | 显示的时候,顺道输出行号! |
| more | 一页一页的显示文件内容 |
| less | 与 more 类似,但是比 more 更好的是,他可以往前翻页! |
| head | 只看头几行 |
| tail | 只看尾巴几行 |
参考链接:Linux 文件与目录管理
下面,让我们一起完成对应学习的任务:

这里需要注意的是,进入datawhale文件夹的命令有两种,a:cd /home/datawhale(绝对路径访问),b:先进入home文件夹,再使用cd ./datawhale(相对路径访问)进去。然后删除文件的时候,添加-rf,强制删除参数,给定删除的权限。
3.在目录下下载文件、阅读文件、传输文件
先让我们一起学习一下,常用的wget下载命令吧。
| Linux下载文件的常用命令 | 解释 |
|---|---|
| wget http://www.linuxde.net/testfile.zip(文件地址) | 使用wget下载单个文件, 从网络下载一个文件并保存在当前目录。 |
| wget -O wordpress.zip(自定义名称) http://www.linuxde.net/download.aspx?id=1080(动态链接地址) | 下载并以不同的文件名保存,wget默认会以最后一个符合"/"的后面的字符来命令,对于动态链接的下载通常文件名会不正确, 可以使用参数-O来指定一个文件名。 |
| wget -c http://www.linuxde.net/testfile.zip(文件地址) | 使用wget -c重新启动下载中断的文件,需要继续中断的下载时可以使用-c参数。 |
| wget -i filelist.txt(url列表目录) | 按照url的列表目录,下载多个文件。 |
| wget -o download.log URL | 把URL对应的下载信息存入日志文件。 |
| wget -r -A.pdf URL | 根据指定的格式,下载指定格式文件。 |
参考链接:linux下载文件命令
| Linux传输文件的常用命令 | 例子及解释 |
|---|---|
| scp /path/filename username@servername:/path/ | 例如:scp /var/www/test.php root@192.168.0.101:/var/www/ |
| 功能:上传本地文件到服务器-> | 解释:把本机/var/www/目录下的test.php文件上传到192.168.0.101这台服务器上的/var/www/目录中 |
| scp username@servername:/path/filename /var/www/local_dir(本地目录) | 例如:scp root@192.168.0.101:/var/www/test.txt |
| 功能: 从服务器上下载文件 -> | 解释: 把192.168.0.101上的/var/www/test.txt 的文件下载到/var/www/local_dir(本地目录) |
| scp -r username@servername:/var/www/remote_dir/(远程目录) /var/www/local_dir(本地目录) | 例如:scp -r root@192.168.0.101:/var/www/test /var/www/ |
| 功能: 从服务器下载整个目录 -> | 解释:把/var/www/remote_dir/的所有文件下载到/var/www/local_dir(本地目录) |
| scp -r local_dir username@servername:remote_dir | 例如:scp -r test root@192.168.0.101:/var/www/ |
| 功能: 上传目录到服务器 -> | 解释: 把当前目录下的test目录上传到服务器的/var/www/ 目录 |
接下来,让我们一起完成对应的学习任务:

这里有一点,需要注意的是,从石墨文档里直接点击文件链接,对应跳转的URL会很奇怪,所以避个坑,不是你的网或者浏览器不行,而是石墨文档的URL有BUG。



Tips-》关于在命令行中可以使用Tab键进行关键词的补全:

4.在目录下使用vi或vim编辑文件
Vim 是从 vi 发展出来的一个文本编辑器。代码补全、编译及错误跳转等方便编程的功能特别丰富, 可以说是程序开发者的一项很好用的工具。
基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。 这三种模式的主要作用分别是:选择进入哪种模式,输入编辑当前文件,以及保存和退出文件。
命令模式(Command mode)
- 用户刚刚启动 vi/vim,便进入了命令模式。此状态下敲击键盘动作会被Vim识别为命令,而非输入字符。
- i 切换到输入模式,以输入字符。
- : 切换到底线命令模式,以在最底一行输入命令。
输入模式(Insert mode)
-
在命令模式下按下i就进入了输入模式。
-
相关的常用按键如下:

-
批量注释的方法:
批量注释:Ctrl + v 进入块选择模式,然后移动光标选中你要注释的行,再按大写的 I 进入行首插入模式输入注释符号如 // 或 #,输入完毕之后,按两下 ESC,Vim 会自动将你选中的所有行首都加上注释,保存退出完成注释。
取消注释:Ctrl + v 进入块选择模式,选中你要删除的行首的注释符号,注意 // 要选中两个,选好之后按 d 即可删除注释,ESC 保存退出。
-
删除的方法:
第一种,使用backspace键,可实现从游标位置从后往前依次删除。
第二种,使用detele键,删除游标位置的字符。
第四种,dd:连续按d按键两次,可删除当前行。
第五种,ndd:n为数字。删除光标所在的向下 n 行,例如20dd 则是删除 20 行。
底线命令模式(Last line mode)
- 在命令模式下按下:(英文冒号)就进入了底线命令模式,底线命令模式可以输入单个或多个字符的命令。
- q 退出程序。
- w 保存文件。
- ESC键 可随时退出底线命令模式。
参考链接:Linux vi/vim
最后,让我们一起完成对应的学习任务:

进入vim以后,首先选择模式i或:,进入对应的模式,我们按i按键,进入编辑模式,并输入代码段:

编辑完成后,按Esc按键退出当前模式,回到命令模式后输入:,进入底线命令模式,输入wq保存当前文件并退出vim。

最后,测试并运行.py文件:

nano的使用及操作流程如下:
先使用nano trail.py(名称自定义)进入nano并编辑文件内容:

然后使用Ctrl+x/X退出,选择y/Y保存文件:
最后命名trail.py文件并按Enter键,退出:

参考链接:nano简单使用介绍
5.在目录下创建py文件,并运行
关于OS和sys的用法参见Python OS 文件/目录方法和Python3 模块,下面,让我们直接上手对应的学习任务吧。
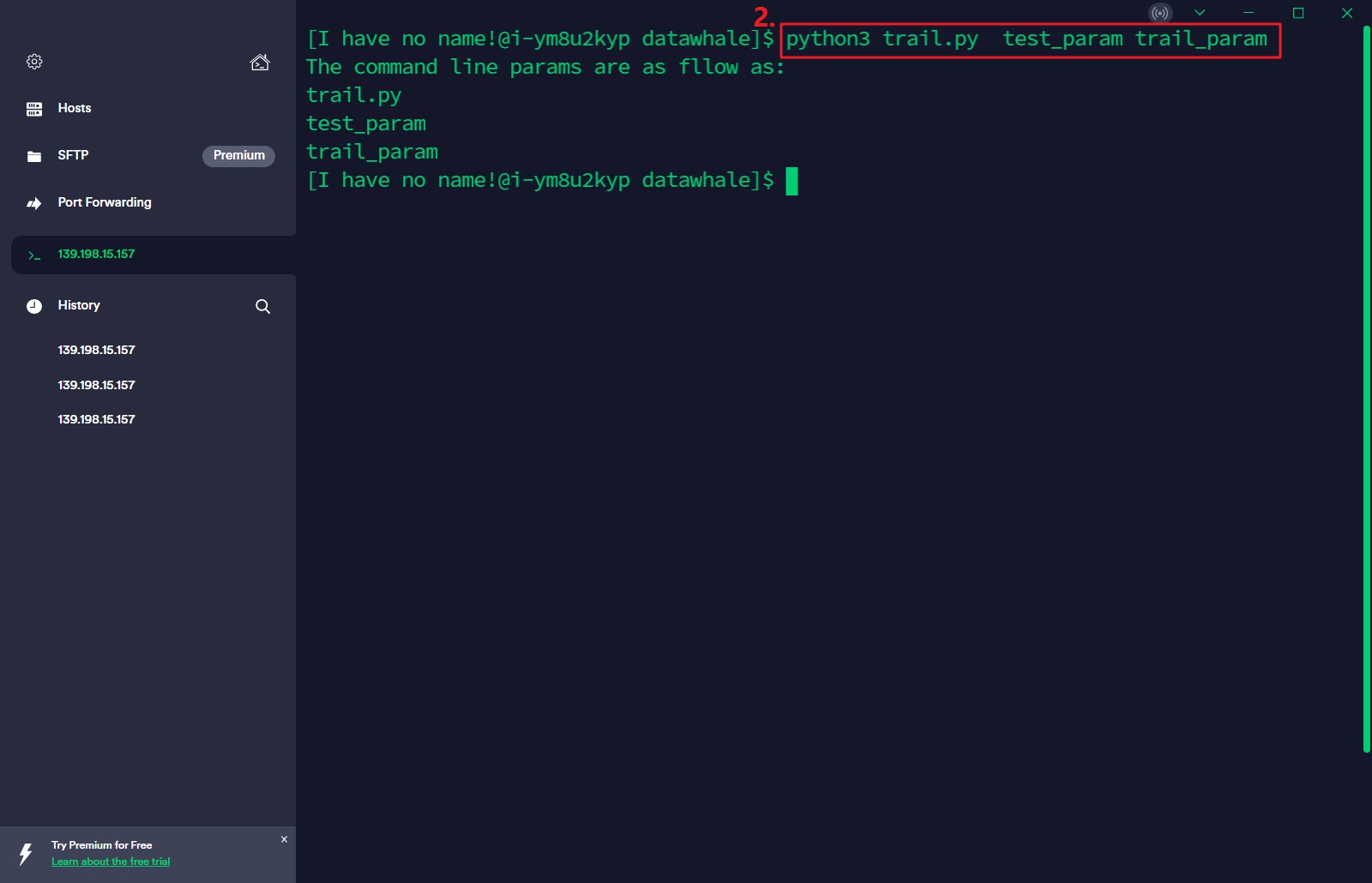
先编写对应的参数读取程序:

然后运行该.py文件:
编写识别名称首字母为“m”的文件,并保存:

运行该.py文件:

6.在目录下创建py目录,并使用import导入(有坑)
python模块化的学习,参见Python3 模块,下面,直接完成对应的学习任务吧!

这里的几个坑:
1.“attempted relative import beyond top-level package”报错,在上一级目录添加一个"__ init __.py"。
2.其次,在运行的affair.py添加sys.path路径为"…",然后再导入test6.py文件。
3.pandas的定位有两种:df.cloumns[…] (列定位)和df.iloc[…] (行定位),不支持直接的切片操作。
参考链接:python模块相对路径导入错误attempted relative import beyond top-level package解决


7.在Linux系统中后台运行应用程序,并打印日志
首先,我们一起学习一下&和nohup后台执行,以及jobs的用法:
&的用法及注意事项:
-
当在前台运行某个作业时,终端被该作业占据;可以在命令后面加上& 实现后台运行。
-
该命令的一般格式为:
command(命令) & -
不过,作业在后台运行一样会将结果输出到屏幕上,干扰你的工作。
-
使用ctrl+d,终止后台并退出ssh终端。(在Terminus的用法,Xshell没有尝试)
-
如果放在后台运行的作业会产生大量的输出,最好使用下面的方法把它的输出重定向到某个文件中,指令格式如下:
command > out.file 2>&1 &
[注]:关于"command > out.file 2>&1 & "的解释如下:
- command>out.file是将command的输出重定向到out.file文件,即输出内容不打印到屏幕上,而是输出到out.file文件中。
- 2>&1 是将标准出错重定向到标准输出,这里的标准输出已经重定向到了out.file文件,即将标准出错也输出到out.file文件中。最后一个&, 是让该命令在后台执行。
- 试想2>1代表什么,2与>结合代表错误重定向,而1则代表错误重定向到一个文件1,而不代表标准输出;换成2>&1,&与1结合就代表标准输出了,就变成错误重定向到标准输出。
nohup的用法及注意事项:
-
nohup命令可以在你退出帐户之后继续运行相应的进程。
-
该命令的一般形式为:
nohup command(命令) & -
在使用nohup命令后台运行命令之后,需要使用exit正常退出当前账户,这样才能保证命令一直在后台运行。
jobs的用法:
-
查看当前有多少在后台运行的命令。
-
该命令的一般形式为:
jobs -
-l:显示进程号;
-p:仅任务对应的显示进程号;
-n:显示任务状态的变化;
-r:仅输出运行状态(running)的任务;
-s:仅输出停止状态(stoped)的任务。
参考链接:
除此以外,还可以学习一下tmux的使用哦!因为,我们这里使用的远程服务器,所以没有权限安装tmux进行演示及操作。但是,这里有两份质量很高的tmux教程供参考。
参考链接:
然后,让我们一起完成对应的学习任务吧!

首先编写sleep.py:

然后再后台运行sleep.py,并将结果写入out.file文件:

最后,参看out.file文件的内容:

未完,更新中…
以上是关于Datawhale开源学习:Linux系统基本操作的详细记录的主要内容,如果未能解决你的问题,请参考以下文章