关键字深度剖析,集齐所有关键字可召唤神龙?
Posted 言之命至9012
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关键字深度剖析,集齐所有关键字可召唤神龙?相关的知识,希望对你有一定的参考价值。
关键字深度剖析,集齐所有关键字可召唤神龙?【二】
今天继续上一次的关键字,学习《C语言深度剖析》,由于深度剖析,简单的东西就不赘述,继续集齐剩下的龙珠吧!

1. if、else 组合
1.1 if 和 else
1.1.1 结论1
认识一种不标准的写法,要认识但是不要模仿,这样的后果是,如果一旦有人改了表达式中的0,就会改变代码
int main()
if (0) //不推荐
int flag = 2;
if (1 == flag)
printf("hello bit\\n");
else if (2 == flag)
if (1)
printf("....................\\n");
printf("hello C深剖\\n");
else
printf("hello world\\n");
return 0;
1.1.2 结论2
在C中0为假,非0为真
1.1.3 结论3
if语句是如何执行的?
- 先执行()中的表达式,得到真假结果
- 条件的判定
- 根据结果进行分支功能
如果if的()中是函数,就是先执行表达式
int IsEmpty()
printf("某种数据是否为空!\\n");
return 1;
int main()
if (IsEmpty())
printf("yes\\n");
return 0;
1.2 bool 变量与"零值"进行比较
C语言中只有0和1,没有bool变量吗?
并不是,首先我们要知道要有bool变量就得导入<stdbool.h>,这是C99中引入的
但是当前使用C语言还是用的不涉及很多
1.2.1 bool变量的大小
int main()
bool ret = false;
ret = true;
printf("%d\\n", sizeof(ret)); //vs2013 和 Linux中都是1
return 0;

别急,还有一套BOOL类型,这套BOOL是微软定义的,也就是说用VS2019特殊才给的
int main()
BOOL ret = FALSE;
ret = TRUE;
printf("%d\\n", sizeof(ret)); //输出结果是4,因为在源代码中,是这么定义的:typedef int BOOL;
return 0;
这里肯定是不推荐BOOL,因为好的习惯是:一定要保证代码的跨平台性,微软定义的专属类型,其他平台不支持。
1.2.2 查看bool源码
源码用到了很多宏定义
//查看源码
/* stdbool.h standard header */
//stdbool.h
#ifndef _STDBOOL
#define _STDBOOL
#define __bool_true_false_are_defined 1
#ifndef __cplusplus
#define bool _Bool //c99中是一个关键字哦,后续可以使用bool
#define false 0 //假
#define true 1 //真
#endif /* __cplusplus */
#endif /* _STDBOOL */
/*
* Copyright (c) 1992-2010 by P.J. Plauger. ALL RIGHTS RESERVED.
* Consult your license regarding permissions and restrictions.
V5.30:0009 */
1.2.3 推荐写法
int main()
//int pass = 0;
//0表示假,C90,我们习惯用int表示bool
bool pass = false; //C99
if (pass == 0) //理论上可行,但此时的pass是应该被当做bool看待的,==用来进行整数比较,不推荐
//TODO
if (pass == false) //不推荐,尽管在C99中也可行
//TODO
if (pass) //推荐
//TODO
//理论上可行,但此时的pass是应该被当做bool看待的,==用来进行整数比较,不推荐
//另外,非0为真,但是非0有多个,这里也不一定是完全正确的
if (pass != 1)
//TODO
if (pass != true) //不推荐,尽管在C99中也可行
//TODO
if (!pass) //推荐
//TODO
return 0;
1.2.4 float 变量与"零值"进行比较
浮点数在内存中存储,并不想我们想的,是完整存储的,在十进制转化成为二进制,是有可能有精度损失的。
注意这里的损失,不是一味的减少了,还有可能增多。浮点数本身存储的时候,在计算不尽的时候,会“四舍五入”或者其他
精度损失的栗子
double d = 3.6; printf("%.50f\\n", 3.6);
double x = 1.0; double y = 0.1; printf("%.50f\\n", x - 0.9); //0.1 printf("%.50f\\n", y);应该是一样的个却打印出来不同的结果
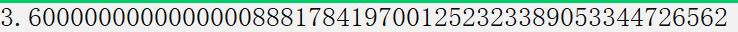

那么既然精度会产生问题所以不能用来作为判断
double x = 1.0;
double y = 0.1;
if ((x - 0.9) == y)
printf("you can see me!\\n");
else
printf("oops!\\n");

所以说浮点数在比较的时候绝对不能使用双等号进行比较
那么怎么才能使用呢?如果一定要用的话这样就可以了
#include<math.h>
#define EPS 0.00000000000001
double x = 1.0;
double y = 0.1;
if (fabs((x - 0.9) - y) < EPS)
printf("you can see me!\\n");
else
printf("oops!\\n");
或者是这样
#include <float.h>
#include<math.h>
double x = 1.0;
double y = 0.1;
if (fabs((x - 0.9) - y) < DBL_EPSILON)
printf("you can see me!\\n");
else
printf("oops!\\n");

什么是 DBL_EPSILON?
我们查找 DBL_EPSILON发现它是最小精度定义XX X_EPSILON是最小误差,是:XXX_EPSILON+n不等于n的最小的正数。
EPSILON这个单词翻译过来是’ε’的意思,数学上,就是极小的正数//两个精度定义 #define DBL_EPSILON 2.2204460492503131e-016 /* smallest such that 1.0+DBL_EPSILON != 1.0 */ #define FLT_EPSILON 1.192092896e-07F /* smallest such that 1.0+FLT_EPSILON != 1.0 */
终于我们能够回到float与0值的比较,或者是double和0值比较
if (fabs(a) < DBL_EPSILON)//不建议写=
//a == 0.0
也就是说如果类型doucle 的a的值是小于 DBL_EPSILON的,那么说明a相当于就是0.0,就是0值
小结:
- 浮点数存储的时候,是有精度损失的
- 浮点数是不能==比较的
- 如何改造使得可以比较
- 要不要<=细节
###1.2.5 指针变量与“零值”进行比较
1.2.4.1 对于NULL, '\\0', 0的整体理解。
int* p = NULL;
printf("%d\\n", 0);
printf("%d\\n", '\\0');
printf("%d\\n", NULL);

NULL其实就是0的强转
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
1.2.4.2 理解强制类型转换
强制类型转换是不会改变数据本身的存储的,只是改变了数据读取的类型方式,而真实的转化会改变内存中的数据
1.2.5 if-else书写风格
1.2.5.1 if- else匹配
C 语言有这样的规定:else 始终与同一括号内最近的未匹配的if 语句结合
int main()
int x = 0;
int y = 1;
if (10 == x)
if (11 == y)
printf("hello bit\\n");
else
printf("hello world!\\n");
return 0;
没有任何输出
int main()
int x = 0;
int y = 1;
if (10 == x)
if (11 == y)
printf("hello bit\\n");
else
printf("hello world!\\n");
system("pause");
return 0;
这样才对
1.2.6.2 if 语句后面的分号
关于if-else 语句还有一个容易出错的地方就是与空语句的连用。
if(NULL != p) ;
fun();
这里的fun()函数并不是在NULL != p 的时候被调用,而是任何时候都会被调用。问题就出
在if 语句后面的分号上。在C 语言中,分号预示着一条语句的结尾,但是并不是每条C 语
言语句都需要分号作为结束标志。if 语句的后面并不需要分号,但如果你不小心写了个分号,
编译器并不会提示出错。因为编译器会把这个分号解析成一条空语句。也就是上面的代码实
际等效于:
if(NULL != p)
;
fun();
2. switch、case 组合
2.1 不要拿青龙偃月刀去削苹果
书中说的很有意思
那你既然有了菜刀为什么还需要水果刀呢?你总不能扛着云长的青龙偃月刀(又名冷艳
锯)去削苹果吧。如果你真能做到,关二爷也会佩服你的。😛
已经有if–else为何还要switch–case
switch语句也是一种分支语句,常常用于多分支的情况。这种多分支,一般指的是很多分支,而且判定条件主要以整型为主,如:为了方便if语句某些状况,常常用于多分支的情况。
比如:
输入1,输出LEBRON
输入2,输出CURRY
输入3,输出KD
输入4,输出HARDEN
输入5,输出PG
输入6,输出GIANNIS
输入7,输出077
那我没写成if…else if …else if 的形式太复杂,那我们就得有不一样的语法形式。
这就是switch 语句。
int main()
int input = 0;
scanf("%d", &input);
switch (input)
case 1:
printf("LEBRON\\n");
break;
case 2:
printf("CURRY\\n");
break;
case 3:
printf("KD\\n");
break;
case 4:
printf("HARDON\\n");
break;
case 5:
printf("PG\\n");
break;
case 6:
printf("GIANNIS\\n");
break;
case 7:
printf("077\\n");
break;
2.2 switch–case配合
2.2.1 case的作用是什么? break在switch中的作用是什么?default的顺序?
- 配合使用case的功能是判定,break的功能是分支
所以一般来说,每个case语句结尾不要忘了加break,否则将导致个分支重叠
当然特殊情况也可以多个case执行一个语句
int main()
int input = 0;
scanf("%d", &input);
switch (input)
case 1:
case 2:
case 3:
case 4:
case 5:
printf("LEBRON\\n");
break;
case 6:
printf("GIANNIS\\n");
break;
case 7:
printf("077\\n");
break;
- default其实不是一定要放在最后的实际上可以放在任何地方,不过放在最后最符合语义
2.2.2 case的值有什么要求吗
case 语句后面是否可以是const修饰的只读变量呢?不行

int main()
const int a = 10;
switch (a)
case a: //不行
printf("hello\\n");
break;
default:
break;
system("pause");
return 0;
2.3 case 语句中有什么要求吗
- case语句中是不能直接定义变量的,或者可以带上来加上代码块,这样也可以使用,还可以传函数
- switch–case中最好不要使用return(保留意见)
2.4 case语句的排列顺序
- 把正常情况放前面,异常情况放在后面
- 按照执行频率排列case顺序
2.5 使用case 语句的其他注意事项
- case语句后面尽量简练。case 语句后面的代码越精炼,case 语句的结果就会越清晰,可以调用函数,一般来说case语句后面的代码尽量不要超过20 行。
- 不要为了使用case 语句而刻意制造一个变量
- 把default 子句只用于检查真正的默认情况。
小结

3. do、while、for 关键字
3.1 三种循环的死循环写法
while (1)
for (;;)
do
while (1);
3.2 输入输出流
任何c语言,在默认编译好之前,运行时,都会打开三个输入输出流

3.2.1 为什么scanf和printf叫做格式化输入和输出
我们试想一下这种情况,
当我们在屏幕上打出1234,究竟printf打出的是字符1234还是数字1234(一千二百三十四),当然应该是字符1234,这是ASCII值的转换,priintf自动的将我们所输出的1234转化为字符所打出,这就是格式化输出
因此同理当我们scanf接受收输出的时候其实本质上在将我们在屏幕上输入的字符给转化成了1234(一千二百三十四)进行存储,这叫做格式化输入
同时我们也应该记住函数printf也是有返回值的,它的返回值是其输出的字符的数量
因此,键盘,显示器等都叫做字符设备
3.3 break和continue
break 关键字很重要,表示终止本层循环。现在这个例子只有一层循环,当代码执行到break 时,循环便终止。
如果把break 换成continue 会是什么样子呢?continue 表示终止本次(本轮)循环。当代码执行到continue 时,本轮循环终止,进入下一轮循环。
do-while 循环:先执行do 后面的代码,然后再判断while 后面括号里的值,如果为真,循环开始;否则,循环不开始。其用法与while 循环没有区别,但相对较少用。
for 循环:for 循环可以很容易的控制循环次数,多用于事先知道循环次数的情况下。
3.4 循环语句的注意点
-
推荐思想,但不限制
在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放
在最外层,以减少CPU 跨切循环层的次数。
-
建议for 语句的循环控制变量的取值采用“半开半闭区间”写法。
半开半闭区间写法和闭区间写法虽然功能是相同,但相比之下,半开半闭区间写法写法更加
直观。什么叫做直观?
for( int i = 0; i < 10 ; i++)半开半闭下这样直接就可以看出是循环了10次
for( int i = 0; i < = 9 ; i++)这样就没有看的那么直观 要反映一下是9+1
-
不能在for 循环体内修改循环变量,防止循环失控
-
循环要尽可能的短,要使代码清晰,一目了然
-
把循环嵌套控制在3层以内
4. goto 关键字
原书作者是这么说goto的
一般来说,编码的水平与goto 语句使用的次数成反比。有的人主张慎用但不禁用goto
语句,但我主张禁用。
int main()
int i = 0;
START:
printf("[%d]goto running ... \\n", i);
Sleep(1000);
++i;
if (i < 10)
goto START;
printf("goto end ... \\n");
return 0;

使用要求: 只能在本代码块中使用,出了main函数 肯定不能用
5. void 关键字
5.1 为什么void不能定义变量
VS上测试void的大小是0个字节
linux上测试却是1个字节
说明其本身的大小就是不确定的,更重要的是它本身就被编译器解释为空类型
我们都知道定义变量的本质:开辟空间
而void作为空类型,理论上是不应该开辟空间的,即使开了空间,也仅仅作为一个占位符看待
所以,既然无法开辟空间,那么也就无法作为正常变量使用,既然无法使用,编译器干脆不让他定义变量。
因此自然是强制告诉我们不可以 以此定义变量
那void的价值是什么呢,就是要告知我是一种空类型,它是特殊用途专门使用的
5.2 void使用情况
5.2.1 void修饰函数返回值的作用
如果自定义函数,或者库函数不需要返回值,那么就可以写成void
那么问题来了,可以不写吗?不可以,自定义函数的默认返回值是int
所以,没有返回值,如果不写void,会让阅读你代码的人产生误解:他是忘了写,还是想默认int?
- 占位符
- 告知编译器函数返回值是无法接收的
函数声明了void,有返回值还用a接收会报错

声明了void,有返回值,但是不接收不报错

5.2.2 void 作为函数参数的作用
- 告诉编译器函数不需要传参
- 充当形参列表,告知用户不要传参
5.3 void 指针
5.3.1 void 指针定义变量
void* 是可以定义变量的,因为每个编译器都是明确的,void*既然是指针,大小就是约定的4/8个字节,
同时void*是可以被任何指针接受的,void*也可以接受任何指针类型`
这样的操作不报错,甚至不会有警告

因此很多库函数返回类型都是void*

这是因为系统接口的设计上会尽量设计成通用接口
5.3.2 void* 变量++?
借用书中所说
按照ANSI(American National Standards Institute)标准,不能对void 指针进行算法操作,
即下列操作都是不合法的:
void * pvoid;
pvoid++; //ANSI:错误
pvoid += 1; //ANSI:错误
ANSI 标准之所以这样认定,是因为它坚持:进行算法操作的指针必须是确定知道其指
向数据类型大小的。也就是说必须知道内存目的地址的确切值。
例如:
int *pint;
pint++; //ANSI:正确
但是大名鼎鼎的GNU则不这么认定,它指定void *的算法
操作与char *一致。因此下列语句在GNU 编译器中皆正确:
GNU计划,又称革奴计划,是由Richard Stallman(理查德·斯托曼)在1983年9月27日公开发起的。它的目标是创建一套完全自由的操作系统。他在编写linux的时候自己制作了一个标准成为 GNU C标准。ANSI 美国国家标准协会,它对C做的标准ANSI C标准后来被国际标准协会接收成为 标准C 所以 ANSI C 和标准C是一个概念,总体来说现在linux也支持标准C,以后标准C可以跨平台,而GUN c 一般只在linux c下应用。
pvoid++; //GNU:正确
pvoid += 1; //GNU:正确
在实际的程序设计中,为符合ANSI 标准,并提高程序的可移植性,我们可以这样编写
实现同样功能的代码:
void * pvoid;
(char *)pvoid++; //ANSI:正确;GNU:正确
(char *)pvoid += 1; //ANSI:错误;GNU:正确
GNU 和ANSI 还有一些区别,总体而言,GNU 较ANSI 更“开放”,提供了对更多语法
的支持。但是我们在真实设计时,还是应该尽可能地符合ANSI 标准。
5.3.3 void*指针可以直接解引用吗
不能解引用
小结:
最后,书中给出了这样一段话
void 的出现只是为了一种抽象的需要,如果你正确地理解了面向对象中“抽象基类”的概
念,也很容易理解void 数据类型。正如不能给抽象基类定义一个实例,我们也不能定义一
个void(让我们类比的称void 为“抽象数据类型”)变量。
void 简单吧?到底是“色”还是“空”呢?
好了今天的内容就到这里了哈!!!
今天的“龙珠”集齐了9颗
下次继续,请持续关注
干净又卫生,别忘了一键三连
以上是关于关键字深度剖析,集齐所有关键字可召唤神龙?的主要内容,如果未能解决你的问题,请参考以下文章